- The paper demonstrates that using perceptual loss (MS-SSIM) in autoencoders results in images that are rated higher in quality by human observers compared to traditional losses like MSE and MAE.
- It shows that perceptual similarity metrics not only enhance image reconstruction but also improve feature extraction for tasks such as image classification and super-resolution.
- The study provides actionable insights on optimizing neural network objectives to align with human visual perception, reducing artifacts and enhancing overall image fidelity.
Summary of "Learning to Generate Images With Perceptual Similarity Metrics"
Introduction
The paper "Learning to Generate Images With Perceptual Similarity Metrics" explores the use of perceptual similarity metrics, in particular, the multiscale structural similarity score (MS-SSIM), as a loss function in image synthesis tasks. The goal is to better align the training of neural networks with human perceptual judgments of image quality, as traditional pixel-wise loss functions such as mean squared error (MSE) often lead to suboptimal perceptual quality. The research compares MS-SSIM with traditional loss measures in deterministic and probabilistic autoencoders, demonstrating superior performance in generating images that humans perceive as high-quality.
Perception-Based Error Metrics
The paper highlights that while pixel-wise loss functions like MSE are computationally convenient, they do not adequately capture human perception of image quality. Previous work on perceptual error metrics, including models like SSIM and its multiscale counterpart MS-SSIM, offers a more human-aligned approach to evaluating image quality. The paper leverages these perceptual metrics to train neural networks to generate images, focusing on deterministic and stochastic autoencoders where MS-SSIM is used as a training objective due to its differentiable nature.
Deterministic Autoencoders
Deterministic autoencoders trained with SSIM or MS-SSIM are shown to produce images that human observers consistently rate higher in quality compared to those optimized with MSE or mean absolute error (MAE). The study involves fully connected and convolutional architectures trained on diverse datasets, demonstrating robust performance across varying image sizes and network configurations. The results indicate a strong human preference for reconstructions synthetically optimized with perceptual metrics.
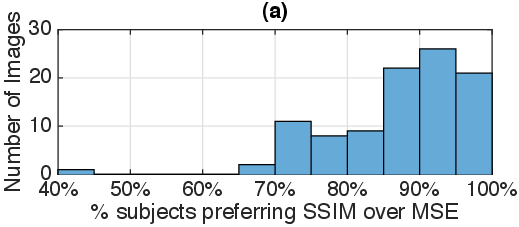
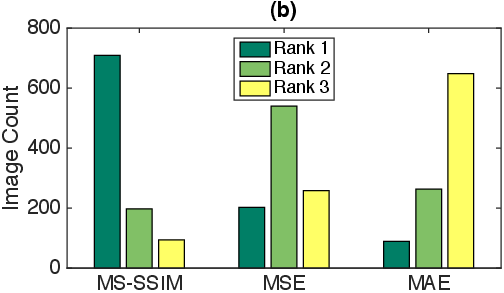
Figure 1: Human judgments of reconstructed images. (a) Fully connected network: Proportion of participants preferring SSIM to MSE for each of 100 image triplets. (b) Deterministic conv. network: Distribution of image quality ranking for MS-SSIM, MSE, and MAE for 1000 images from the STL-10 hold-out set.
Probabilistic Autoencoders
The research further explores the use of MS-SSIM within the framework of variational autoencoders (VAEs), adapted as Expected-Loss VAEs (EL-VAEs). By incorporating perceptual losses into the EL-VAE framework, the paper demonstrates that perceptually-optimized autoencoders outperform traditional models in generating novel images with high perceptual quality, as confirmed by human evaluations.


Figure 2: (a) Four randomly selected, held-out STL-10 images and their reconstructions. For these images, the MS-SSIM reconstruction was ranked as best by humans. Reconstructions are from the 128-hidden-unit VAEs. From left to right are the original image, followed by the MS-SSIM, MSE, and MAE reconstructions. (b) Four randomly selected test images where the MS-SSIM reconstruction was ranked second or third.
Image Classification and Super-Resolution
Beyond reconstruction tasks, the paper also addresses whether perceptually-based training objectives aid in acquiring image representations useful for ancillary tasks like classification. Experiments using SVM on bottleneck features of deterministically trained autoencoders suggest improved performance in predicting image features, such as identity and lighting conditions, when trained with perceptual losses.
In image super-resolution tasks, perceptual losses enhance image detail recovery while reducing artifacts, achieving quality improvements recognizable by standard metrics like PSNR and SSIM.
















Figure 3: Visual comparisons on super-resolution at a magnification factor of 4. MS-SSIM not only improves resolution but also removes artifacts, \eg, the ringing effect in the bottom row, and enhances contrast, \eg, the fabric in the third row.
Conclusion
The paper makes a compelling case for integrating perceptual similarity metrics in training objectives for neural networks tasked with image generation, advocating for the paradigm shift from traditional pixel-wise losses to those more aligned with human visual perception. It sets a foundation for further research into perceptual metrics and their potential applications across various domains in computer vision, promising significant advancements in tasks requiring highly detailed and perceptually coherent imagery.