- The paper reviews random forests, consolidating recent theoretical advances in parameter selection, resampling, and variable importance metrics.
- The methodology employs bootstrap sampling and local averaging to link ensemble predictions with convergence and consistency benchmarks.
- The work explores extensions, such as online and survival forests, emphasizing practical implications for high-dimensional data analysis.
A Random Forest Guided Tour
Abstract
This paper provides an extensive review of random forests, a robust classification and regression methodology introduced by L. Breiman. It consolidates the latest theoretical and methodological advancements, examining foundational mathematical components such as parameter selection, resampling, and variable significance metrics to make the technique accessible to applied researchers.
Introduction
Random forests have emerged as a fundamental tool in machine learning, offering significant advantages in computational efficiency and accuracy across various data-driven applications, especially those involving large dimensionality. Despite their widespread implementation, there remains a critical gap in understanding the theoretical underpinnings of random forests—a gap this paper seeks to address by presenting prominent theoretical and methodological developments.
Random Forest Estimate
Basic Principles
A random forest is an ensemble learning method involving multiple randomized decision trees that operate according to the "divide and conquer" strategy. This involves aggregating predictions from individual decision tree models skilled in a subset of the overall data features. Critical to the operation of random forests is the selection of parameters such as mtry, nodesize, and a_n, which influence the robustness and performance of the constructed forest.
Algorithmic Overview
The construction of a random forest involves growing M distinct decision trees, where each tree is trained on a bootstrap sample of the data. An iterative process of random feature selection and optimizing the CART-split criterion constructs these trees. The flexibility of this construction process allows random forests to adapt to both regression and classification tasks.
Simplified Models and Local Averaging Estimates
Simplified Models
While simplified models such as purely random forests offer insights into random forests' theoretical properties, they often avoid the complexity of real-world data dependency. These models assume independence from the training dataset and focus on non-adaptive constructions, which are helpful for initial insights into convergence and consistency but do not fully capture the inner workings of Breiman's forests.
Local Averaging and Nearest Neighbors
Every random forest predictor is fundamentally a local averaging estimator employing weighted sums of approximations from the layered nearest neighbor approach. By considering simplified non-adaptive models, it becomes possible to connect weights in forests to the layered nearest neighbors, thereby offering an avenue to study the convergence properties of random forest estimates.
Theory for Breiman's Forests
Resampling Mechanism
Empirically, the bootstrap mechanism, pivotal to the operation of random forests, is poorly understood in theoretical circles. While subsampling has proven useful in theoretical explorations, extending theoretical insights to the bootstrap remains challenging.
Decision Splits
Understanding the decision split process—predominantly governed by the CART-split criterion—remains an area with limited theoretical guarantees. Recent work has provided asymptotic distributions of split locations to aid in understanding their impact.
Consistency and Asymptotic Normality
Establishing the consistency and asymptotic properties of random forest algorithms remains a complex task owing to algorithmic intricacies that interact with data-driven components. Theoretical results are presently asymmetric across various components of random forests, with stronger guarantees available for simplified models.
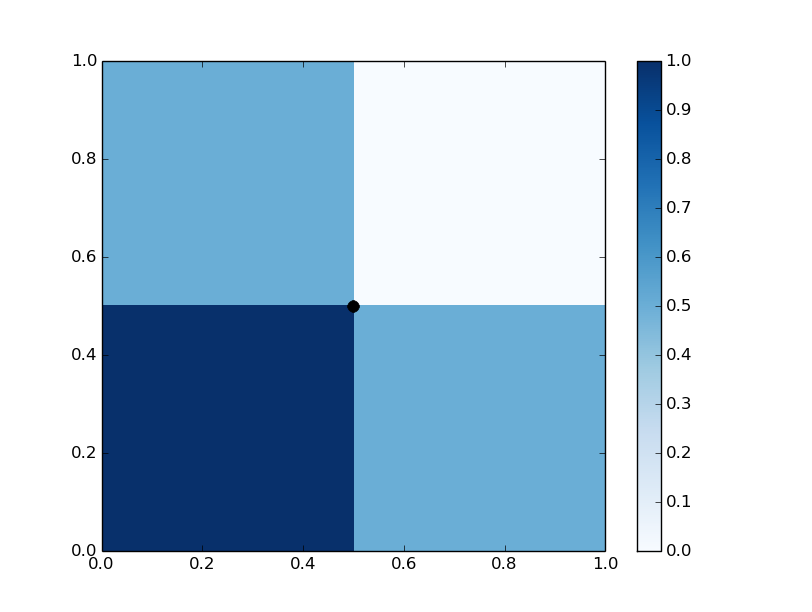
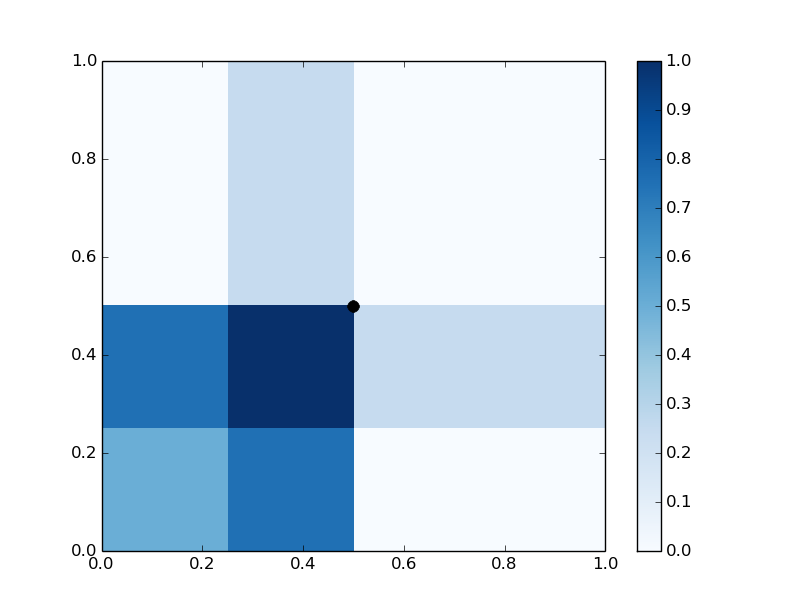
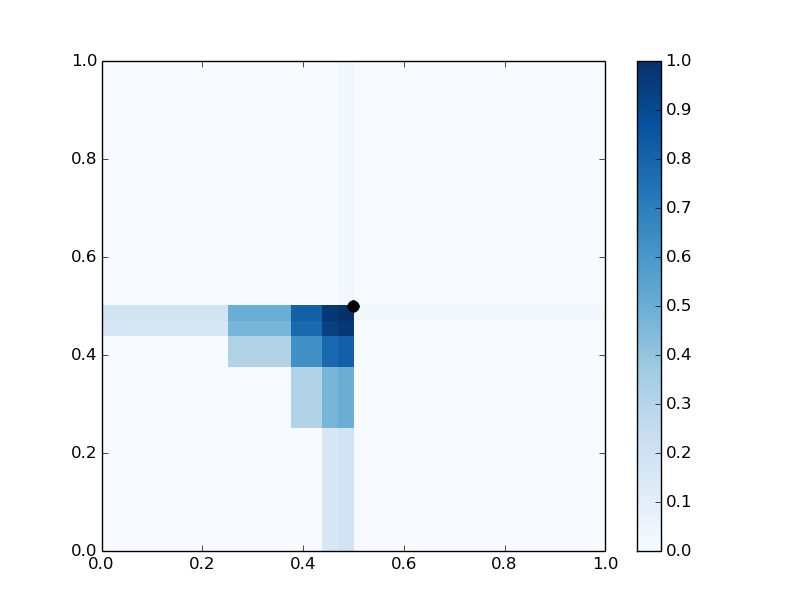
Figure 1: Representations of f1, f2, and f5 in [0,1]2, illustrating centered tree representation.
Variable Importance
Measures of Variable Importance
Two principal measures, Mean Decrease Impurity (MDI) and Mean Decrease Accuracy (MDA), enable practitioners to interpret random forest outputs by identifying influential features within a dataset. These metrics provide insight into the predictive contributions and reliability of model features.
Theoretical Results
Significant work has highlighted the relationship between these importance scores and classical statistical measures such as mutual information. However, more applied-focused studies are necessary to consolidate theoretical insights with practical interpretability.
Extensions
Recent extensions of random forests encompass weighted forests, online forests, survival forests, quantile forests, handling missing data robustly, addressing single-class classification problems, and managing unbalanced datasets, representing vital adaptations that extend the applicability of the original algorithm to diverse and sophisticated problems.
Conclusion
While random forests are highly effective in application, the need persists for rigorous theoretical insights and valid empirical testing methods, particularly concerning parameter selection and the quantification of performance improvements with increased tree depth. Future work could establish connections with neural network architectures, providing a novel perspective on capacity and generalization in ensemble methods. Moreover, optimizing algorithmic parameters like an, forest size, and selection criteria, remains an open question, calling for theoretical exploration and practical validation.
The combination of evolving theoretical insights with empirical experimentation will further elucidate the strengths and limitations of random forests, consolidating their position as a cornerstone of modern machine learning.