- The paper introduces an extended natural gradient descent method that uses unlabeled data and second-order information to improve convergence and model robustness.
- It leverages the Fisher Information Matrix to adjust parameter updates, ensuring invariance to re-parametrization and consistency regardless of training data order.
- Empirical results demonstrate that integrating Natural Conjugate Gradient yields faster convergence and enhanced generalization compared to standard SGD.
Revisiting Natural Gradient for Deep Networks
The paper "Revisiting Natural Gradient for Deep Networks" explores the application of natural gradient descent, initially introduced by Amari, to the training of deep models. The authors highlight connections to previously established optimization techniques and extend the algorithm's capabilities with second-order information. This essay explores the implications and numerical results of the study, as well as its contribution to the practical implementation of deep learning models.
Natural Gradient Descent
Natural gradient descent (NGD) stems from information geometry and offers a way to utilize the curvature of the parameter manifold in optimization. The Fisher Information Matrix plays a central role as the Riemannian metric, guiding updates in parameter space by considering local similarities over the manifold. This mechanism makes NGD robust to re-parametrization, which is an advantage when dealing with complex models like neural networks.
The formulation is based on manipulating gradients with respect to the KL divergence surface, favoring steps that preserve the intrinsic structure of the model. Practically, this involves computing the natural gradient ∇NL(θ) by correcting the gradient ∇L(θ) using the inverse of the Fisher matrix F−1.
Incorporating Unlabeled Data
One of the novel contributions of the paper is the effective use of unlabeled data to enhance generalization in NGD. By estimating the metric on random, unlabeled examples, the authors achieve improved test error, supporting the hypothesis that NGD benefits from diverse data exposure during training. This approach mitigates overfitting by avoiding large changes focused strictly around trained examples.
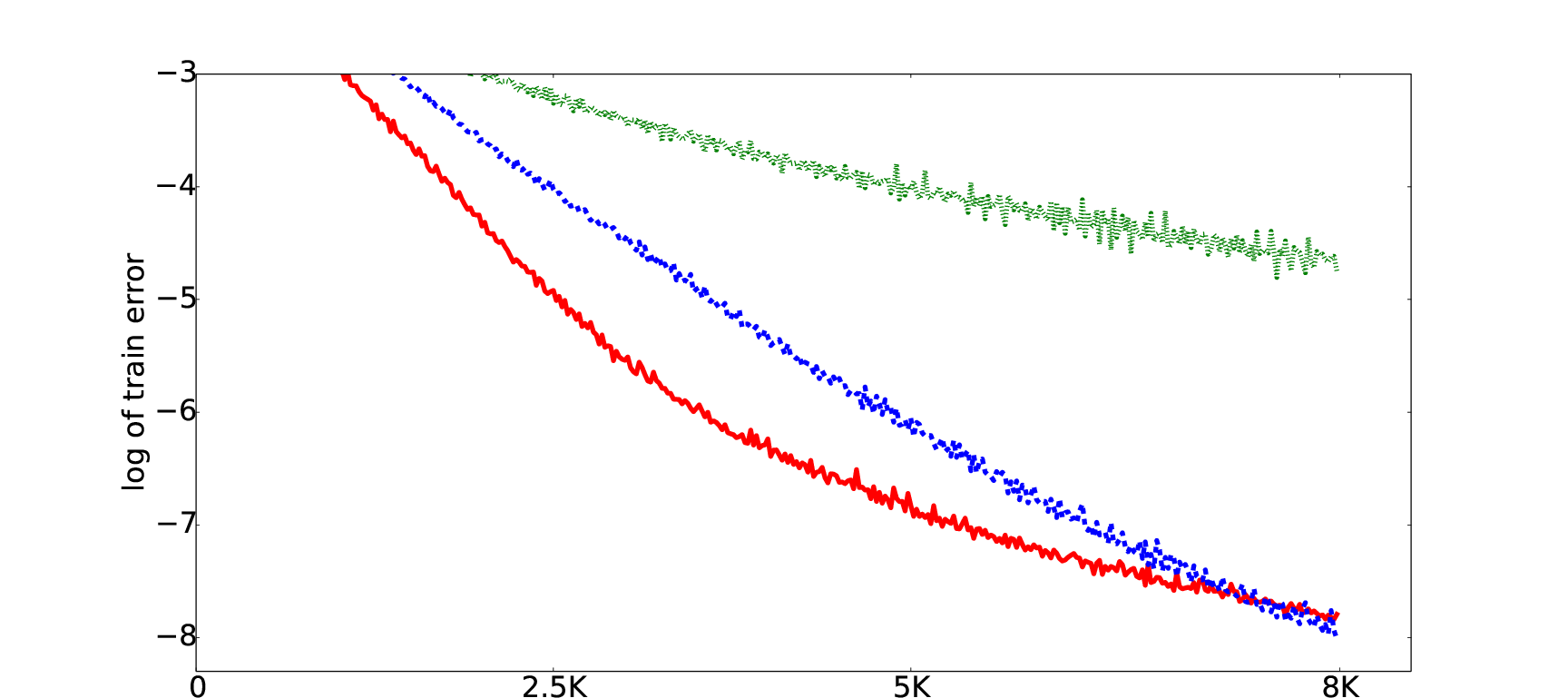
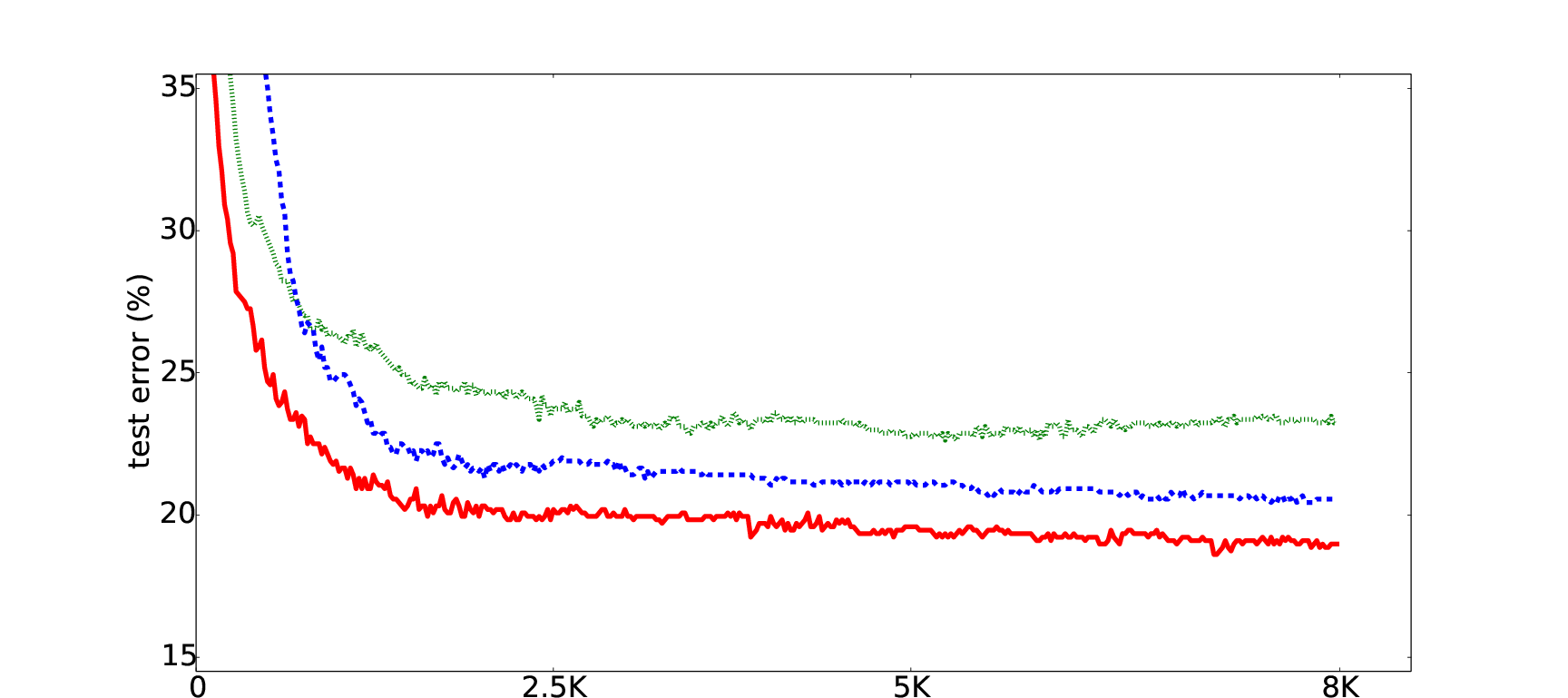
Figure 1: The plot illustrates improvements from using unlabeled data for metric estimation in NGD.
Robustness to Data Order
Another empirical insight from the study is the relative insensitivity of NGD to the ordering of training samples. Compared to Stochastic Gradient Descent (SGD), NGD's methodology ensures consistent learning and model formation irrespective of initialization sequences in data input. This robustness is crucial for processing nonstationary data streams, often encountered in real-world scenarios.
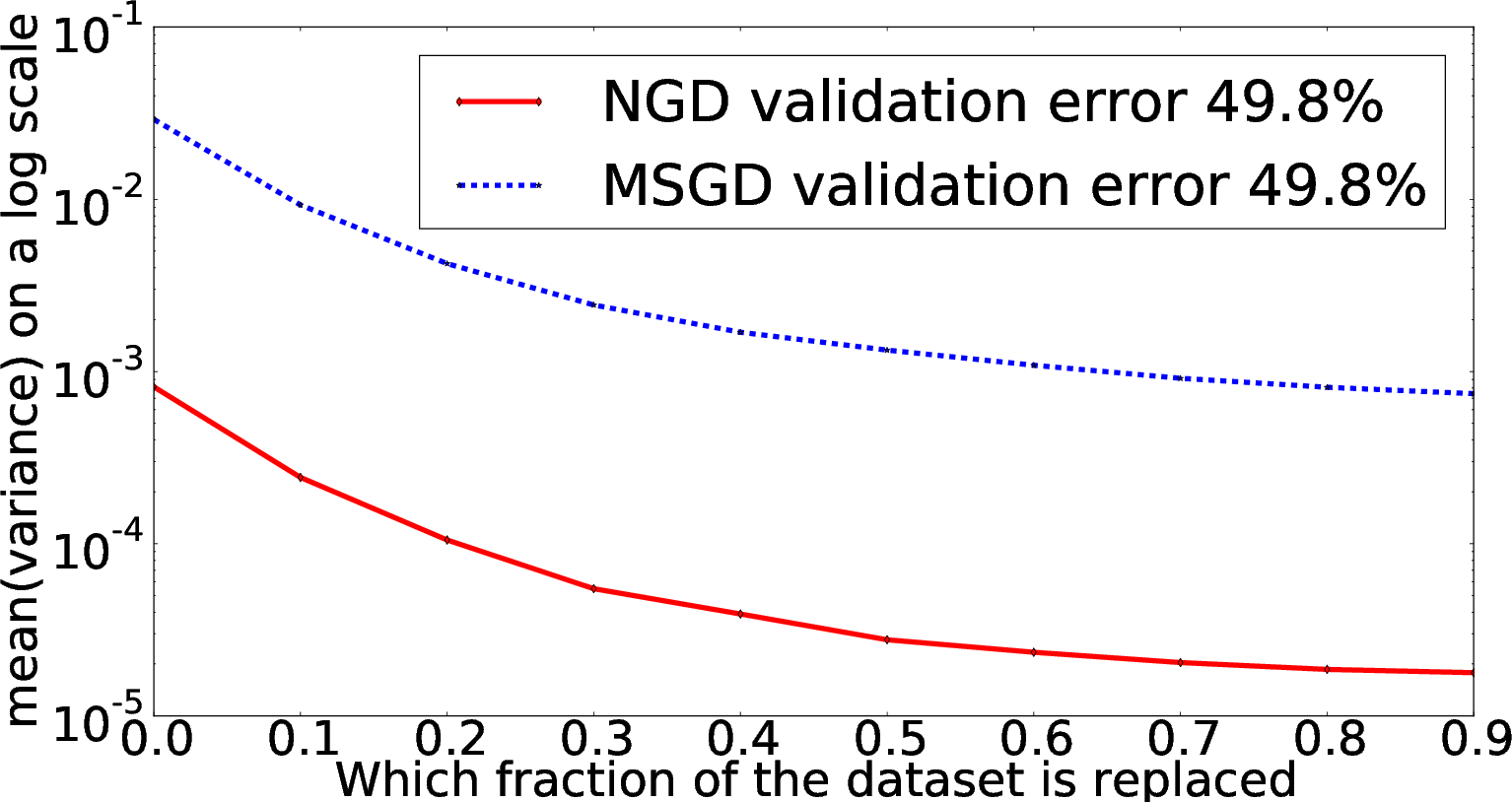
Figure 2: Variance impact is reduced in NGD according to training data order reshuffle, highlighting robustness.
The paper compares NGD with Hessian-Free Optimization and Krylov Subspace Descent, illustrating how these algorithms share roots in manipulating the manifold's geometry. One significant point is the equivalence of Hessian-Free Optimization's extended Gauss-Newton approximation with the Fisher Information Matrix used in NGD, which explains their similar performance in optimizing machine learning models.
Natural Conjugate Gradient
The authors further extend NGD with second-order techniques, introducing Natural Conjugate Gradient (NCG). This method encapsulates broader search directions on the manifold without requiring Hessian computation. By optimizing both the step size and direction correction term, NCG demonstrates faster convergence in experiments, suggesting improvements over simple NGD.
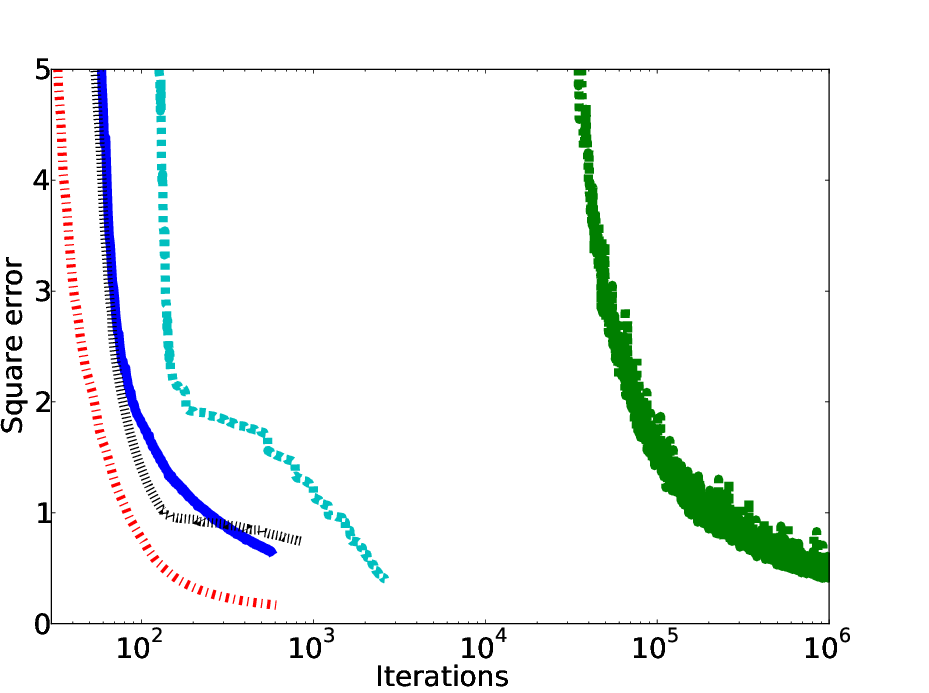
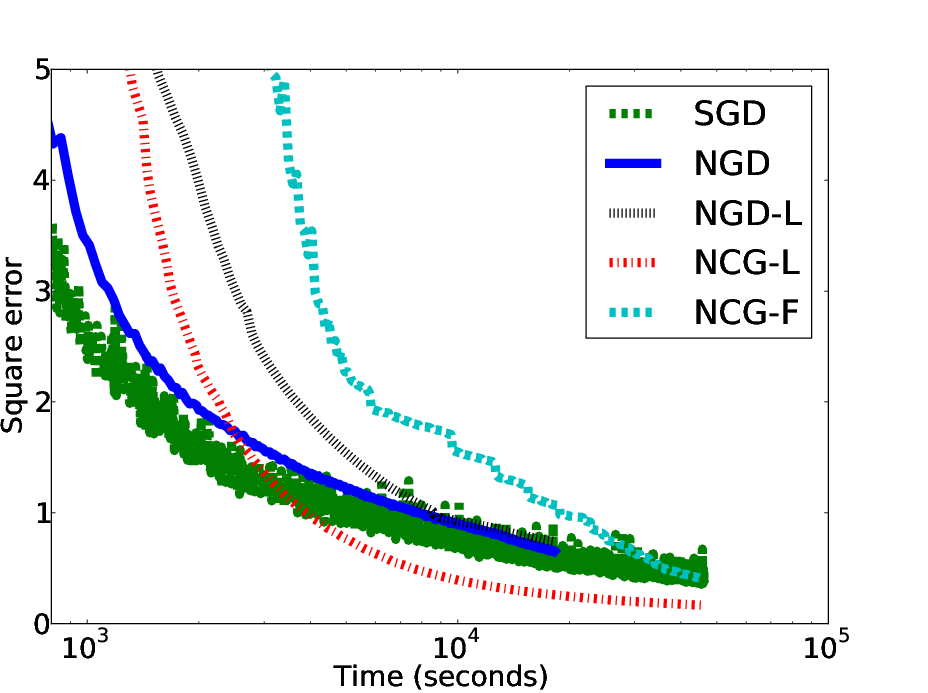
Figure 3: Comparative analysis shows improved convergence with second-order information in NGD implementations.
Conclusion
The exploration and refinement of natural gradient descent not only broaden its theoretical foundation but also provide tangible benefits in practice. The paper's contributions include leveraging unlabeled data, detailing robustness to data order, and integrating second-order information. Together, these advancements enhance NGD's applicability in training deep networks, ushering potential improvements in model robustness and generalization. The empirical results affirm NGD's value in environments where optimization fidelity and convergence speed are paramount.

