- The paper introduces the iMDP algorithm, which incrementally approximates stochastic control problems and guarantees convergence to the optimal value function.
- It details a unique approach combining state sampling, transition probability estimation, and asynchronous value iteration to manage continuous dynamics.
- Experiments on LQR and robot motion planning demonstrate the algorithm's robust performance and efficiency under significant process noise.
An Incremental Sampling-based Algorithm for Stochastic Optimal Control
In the paper "An Incremental Sampling-based Algorithm for Stochastic Optimal Control" (1202.5544), the authors develop a novel algorithm called the incremental Markov Decision Process (iMDP) for approximating control policies that resolve continuous-time, continuous-space stochastic optimal control problems. Building upon advances in Markov chain approximation and sampling-based path planning algorithms, the paper aims to address the computational challenges and lack of exact algorithmic solutions inherent in continuous stochastic optimal control tasks.
Problem Definition and Approach
The authors formulate the problem as follows: Given a continuous-time dynamical system with stochastic dynamics, compute an optimal policy minimizing the expected cost-to-go function. Typical approaches, such as numerical solutions to the Hamilton-Jacobi-Bellman PDE or discrete MDP approximations, become computationally prohibitive due to the curse of dimensionality.
To circumvent these issues, the paper introduces the iMDP algorithm. The core idea is to iteratively construct a sequence of discrete MDPs as stand-ins that incrementally approach the original problem's dynamics. Each iteration involves a refined MDP formed through random sampling from the state space with subsequent value iteration to derive an optimal policy incrementally.
Key Contributions and Methodology
The iMDP algorithm utilizes several primitive procedures including:
- Sampling: Randomly sampling from both the state space's interior and boundary to add new states to the MDP.
- Transition Probabilities: Generating stochastic transitions between these states that are locally consistent with the underlying dynamics.
- Asynchronous Value Iteration: Iteratively updating states using Bellman updates to solve the MDP while employing sampling of control inputs to manage the continuous control space.
Through rigorous proof, the authors establish that, with probability one, the approximating sequence of optimal value functions converges to the original problem's value function. This ensures the algorithm not only provides anytime solutions but also asymptotic optimality.
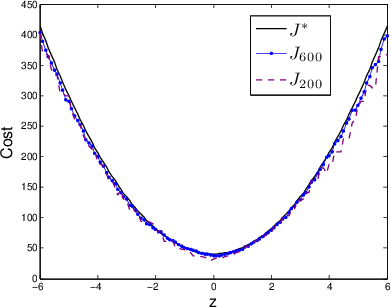
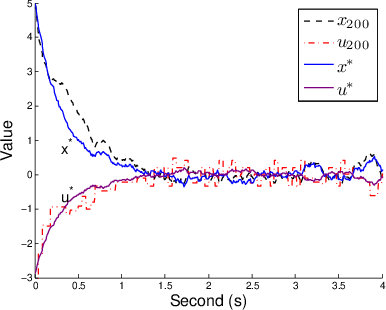
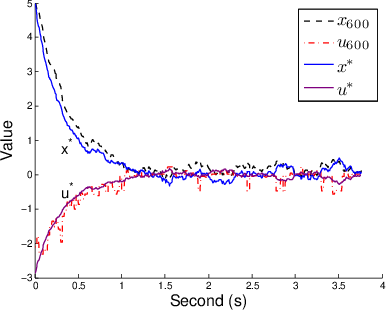
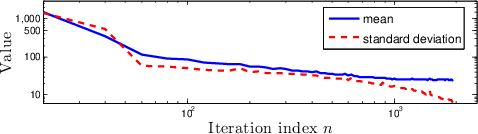
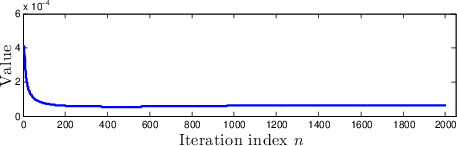
Figure 1: Results of iMDP on a stochastic LQR problem.
Experiments and Results
The paper showcases multiple simulations, including a two-dimensional stochastic LQR problem and robot motion planning with process noise.
- LQR Experiment: Demonstrates that the iMDP effectively approximates cost-to-go values and control policies over iterations, reducing error and variance with each iteration.
- Robot Motion Planning: When subject to considerable stochastic noise, the iMDP algorithm finds safer paths in cluttered environments, as indicated by the outlined trajectories. Unlike deterministic methods like RRT, iMDP provides robust feedback policies without necessitating constant re-planning.



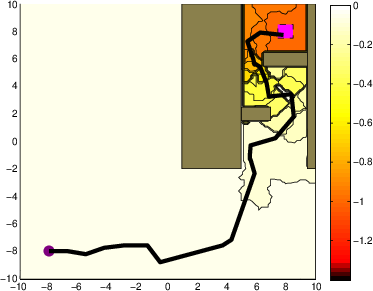
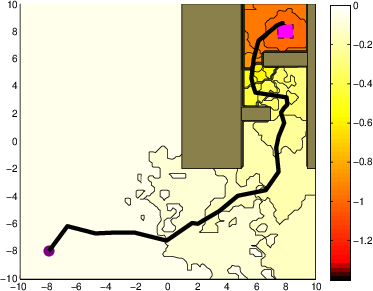
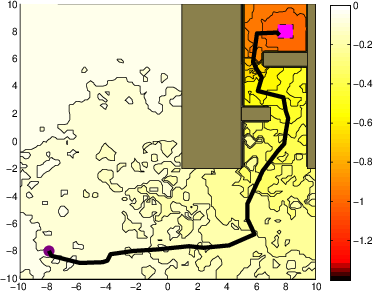

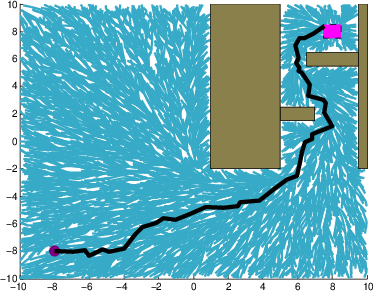
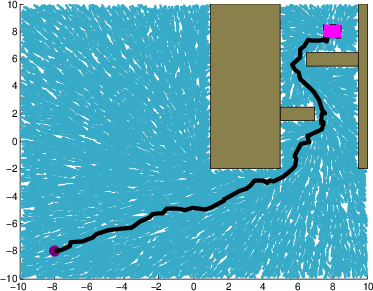
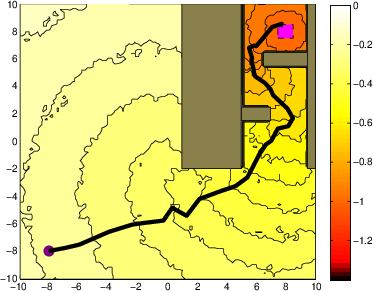
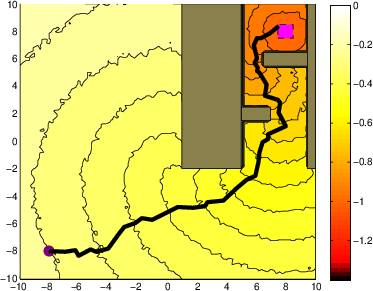
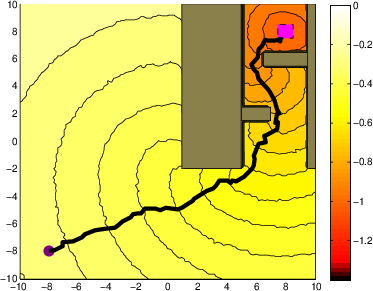
Figure 2: A system with stochastic single integrator dynamics in a cluttered environment.
Implementation Considerations
The iMDP balances computational complexity and accuracy by locally discretizing the problem space, which leads to an efficient incremental approach with linear space and time complexities. State sampling frequency and control set size directly influence the algorithm's performance, with convergence rates affected by the dispersion of samples in the state space.
The algorithm's flexibility suits high-dimensional systems, as evidenced by experiments with a six-degree-of-freedom manipulator demonstrating the feasibility of solving real-world robotics control problems.

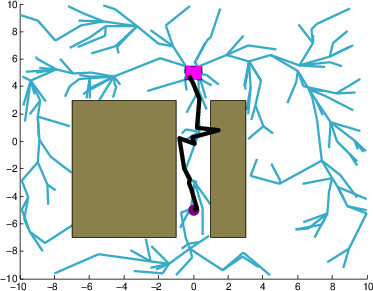
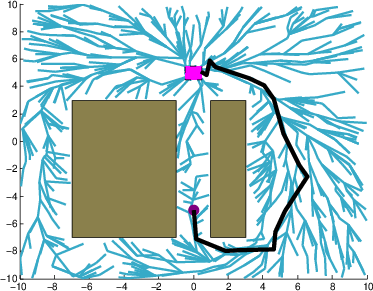
Figure 3: Performance against different process noise magnitudes.
Conclusion and Future Work
The iMDP algorithm presents a practical method for solving stochastic optimal control problems by delivering feedback control policies incrementally aligned with underlying stochastic dynamics. Future extensions consider adaptations for biased-sampling techniques and parallel implementations to enhance iMDP's real-time suitability, potentially extending its application to Partially Observable Markov Decision Processes (POMDPs) and deterministic control problems.
Overall, the study highlights the algorithm's promise for optimal control in complex environments where traditional methods fall short. The iMDP's incremental, sampling-based nature points toward broader applications across areas requiring effective regulation under uncertainty.