- The paper demonstrates that content-intrinsic features, notably source score, can forecast tweet volume for news articles.
- It employs comprehensive feature engineering and regression/classification techniques, achieving up to 84% accuracy in predicting tweet tiers.
- The study reveals a disconnect between traditional news authority and social media popularity, highlighting shifts in digital news dynamics.
Forecasting News Article Popularity on Social Media: An Analysis of "The Pulse of News in Social Media: Forecasting Popularity"
Introduction
The task of predicting the online popularity of news articles prior to publication presents a formidable challenge given the inherent randomness and complexity of human attention dynamics and information propagation. The paper "The Pulse of News in Social Media: Forecasting Popularity" (1202.0332) undertakes this problem by developing a multi-dimensional feature framework, using only article-intrinsic characteristics, to forecast the range of social popularity—specifically retweet volume on Twitter—achievable by news items. Disregarding the use of early popularity statistics, the research focuses on attributes that are observable or computable at publication time, thus offering practical foresight for content producers and curators.
Dataset Construction and Feature Engineering
A comprehensive corpus of news articles was harvested from Feedzilla over a one-week period in August 2011. This dataset, after cleaning and de-duplication, was cross-referenced with Twitter activity using Topsy to quantify the social propagation of each article, operationalized as the total number of (re)tweets per article.
The dataset exhibits a heavy-tailed log-log distribution in tweet volume, indicating a small minority of articles achieving disproportionate popularity while most remain relatively obscure.
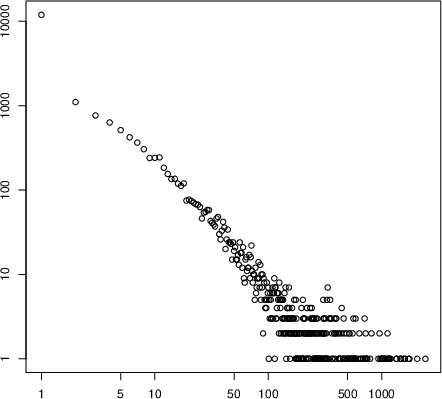
Figure 1: Log-log distribution of tweets across the news article corpus, illustrating the characteristic long-tail pattern of content virality on social platforms.
Four primary features were engineered to capture the potential for social propagation:
- Source Score: Quantified using historical t-density (mean tweets per article) for 1350 content sources, normalized via logarithmic transformation.
- Category Score: Average t-density per Feedzilla-provided news category, adjusted for differences in publishing rates and engagement intensities across domains.
- Subjectivity: Binary subjective/objective classifier leveraging LingPipe, trained on curated corpora representing factual reporting and commentary.
- Named Entity Prominence: Derived via Stanford-NER, with entity-specific t-density computed from one month of historical Twitter data.
Category-level and temporal analyses revealed substantial heterogeneity in t-density distributions and engagement, notably with "Technology" displaying both high publication volume and user attention.
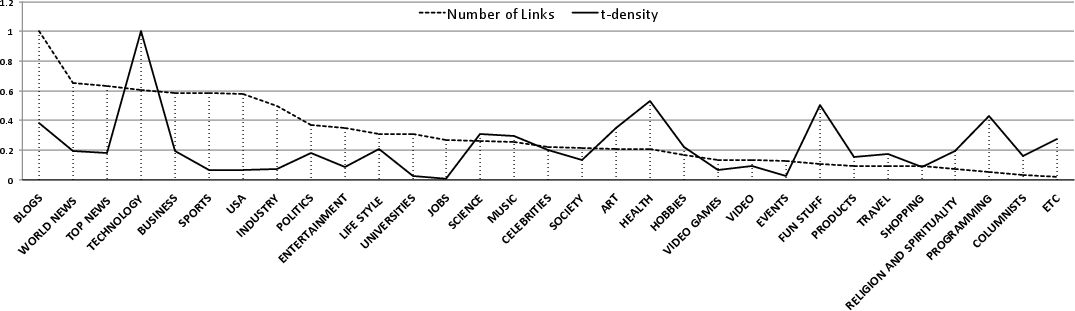
Figure 2: Normalized t-density scores for various news categories, highlighting divergence between publication volume and per-article engagement.
Source Dynamics and Temporal Patterns
Analysis of source-level trends identified significant variation and instability in individual source t-density, necessitating normalization and temporal smoothing. The optimal window for source t-density estimation was empirically determined at approximately 50 days, after which further inclusion of historical data yielded diminishing improvements in correlation with current performance.
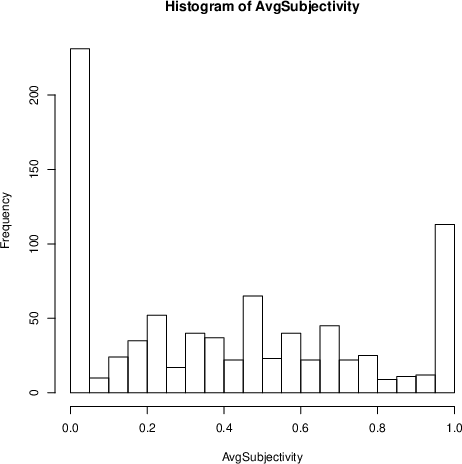
Figure 3: Distribution of average subjectivity of news sources, illustrating polarization between objective and subjective editorial styles.
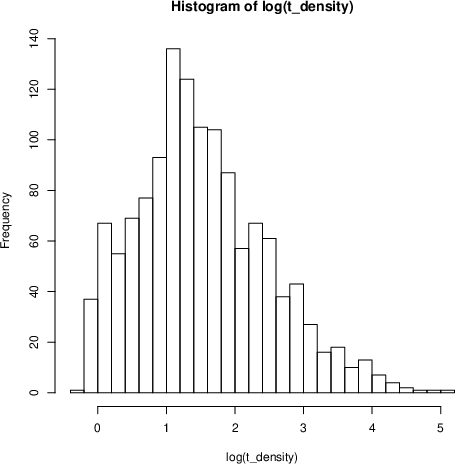
Figure 4: Log-transformed distribution of source t-density, improving normality for downstream regression applications.
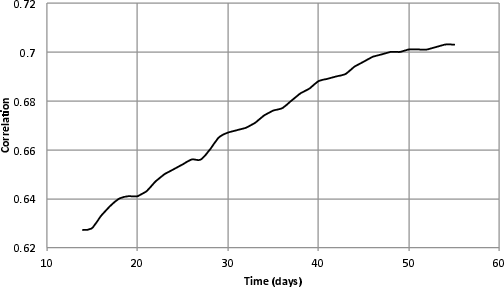
Figure 5: Correlation trend between historical source t-density window size and predictive accuracy, peaking near 50 days of trailing data.
Individual sources demonstrated distinctive temporal signatures in t-density, with some (e.g., major tech blogs) achieving sustained high engagement, while others (e.g., niche or personality-driven weblogs) exhibited burstiness.
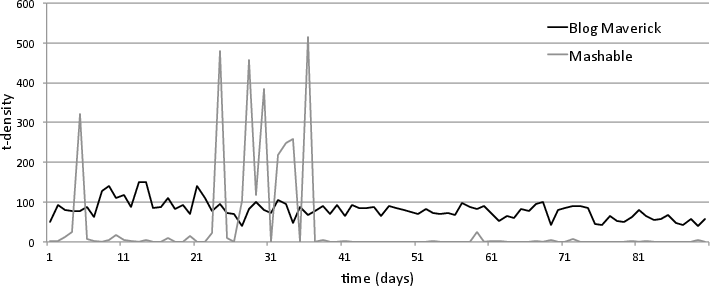
Figure 6: Timeline of t-density for representative sources, showing contrast in propagation stability between high-volume and niche publishers.
Network-wide, the periodic cyclicality in tweeting and posting activity did not translate to t-density, indicating that engagement rates are uncoupled from publishing volume periodicity.
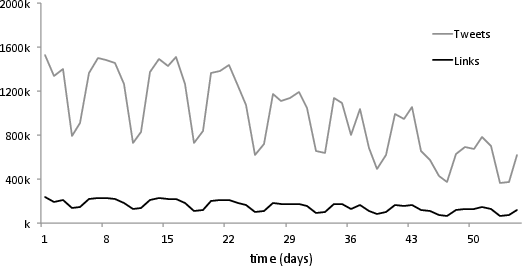
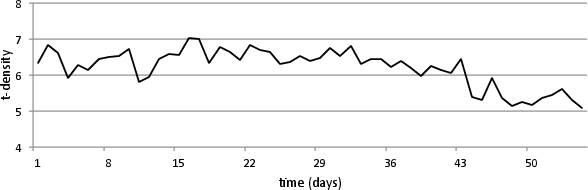
Figure 7: Temporal variation in absolute tweets, posting volume, and resultant t-density across all sources, highlighting the lack of clear periodicity in normalized engagement metrics.
Regression and Classification Results
Standard regression techniques, including linear, SVM, and KNN regression, were applied to predict log-tweet counts per article as a continuous variable. The transformations and feature combinations explored yielded an R2 between 0.25 and 0.34 on the test set, with improved performance for category-specific subsets such as "Technology" (up to R2=0.43). It was found that KNN regression underperformed with increasing dataset size, indicating non-locality of information spread in the feature space.
For practical applications, the classification problem was more salient: determining tweet-count tiers (e.g., low, medium, high) based solely on content-derived features. SVM, bagging, and decision tree classifiers were evaluated, with bagging achieving the highest overall accuracy of 84% when distinguishing between 1–20, 20–100, and 100+ tweet ranges.
Notably, ablation studies demonstrated that source score is the dominant predictor. Named entity and subjectivity features provided minimal incremental value in this regime. Conversely, category information—while weak for popularity prediction within articles that do propagate—proved relevant in classifying whether an article would achieve any Twitter visibility at all.
Re-Evaluating Traditional News Authority
The analysis of the relationship between conventional news authority (as marked by Google News/NewsKnife rankings) and social popularity on Twitter unmasks a surprising decoupling: major legacy media outlets tend to publish in higher volume but do not exhibit high per-article t-density. Technology-centric or marketing-oriented blogs, and well-known individual weblogs, dominate social propagation.
This highlights a substantial shift in networked media ecology, with social propagation mechanisms privileging different actors and editorial strategies compared to algorithmic homepage curation.
Implications and Future Directions
This research underscores the feasibility, albeit with significant stochasticity, of pre-publication social virality forecasting using only content-derived features. Source identity remains the overwhelming driver of engagement; subjectivity and named entity prominence, counterintuitively, offer negligible additional signal within the present modeling framework. The findings have several implications:
- Editorial teams could leverage t-density features to forecast—and iteratively modify—article construction and deployment strategies.
- News recommender systems may benefit from incorporating source- and category-derived priors for improved targeting of viral content.
- The divergence of traditional authority from networked popularity signals misalignment between legacy and social media influence, meriting further analysis of causal mechanisms.
Future research should seek to:
- Develop improved, non-overlapping category extraction schemes to enhance granularity of content type effects.
- Integrate network structure attributes, such as user influence scores and diffusion path characteristics, to augment predictive models.
- Explore real-time, early-diffusion-enhanced hybrid regressors to bridge pre-release and dynamic popularity forecasting.
Conclusion
The paper provides a rigorous, data-driven approach to forecasting the propagation of news articles on Twitter using content and source features, without resorting to post-release popularity signals. The empirical analysis establishes that while exact prediction of tweet volume remains challenging, robust classification into popularity brackets is achievable with high accuracy. The disconnect between traditional news authority and social media propagation foregrounds the evolving dynamics of digital news ecosystems. The research points to several concrete avenues for improving both theoretical understanding and practical application of social attention prediction in networked information space.

