How AI Agents Reshape Knowledge Work: Autonomy, Efficiency, and Scope
Abstract: Frontier AI systems are bridging the gap between intelligence and utility by shifting from conversational assistants to autonomous agents that execute tasks end to end. Using production data from Perplexity's Search and Computer products, we study this transition by examining how AI agents accelerate and reshape knowledge work. Three key empirical findings emerge. First, using sessions with near-identical initial query pairs as natural experiments for the same underlying task attempted with both products, Computer performs 26 minutes of autonomous work per user session, versus 33 seconds for Search. Computer automates task decomposition and execution that Search users might otherwise manually orchestrate and implement. As a result, Computer shifts follow-up query distribution toward higher-order work such as verification and extension. Autonomy also increases execution quality, with per-query dissatisfaction rates 55% lower on Computer than on Search. Second, due to its autonomy advantage, Computer reduces completion time from 269 to 36 minutes on matched tasks, lowering estimated time and cost by 87% and 94%, respectively, compared to humans equipped with Search alone. Third, Computer changes the scope of work that users attempt: Computer queries more often cross occupational boundaries, require higher-order cognition, draw on broader expertise, take the form of composite tasks that bundle interdependent subtasks into a single query, and unlock work activities that are essentially absent from Search usage among the same users. Together, the evidence indicates that AI agents accelerate workflows, enhance output quality, reduce costs, and expand the breadth and depth of automated work.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper asks a big question: how do new AI “agents” change the way people do knowledge work (things like researching, writing, coding, analyzing, and planning)? The authors compare two kinds of AI tools:
- A conversational assistant (Perplexity Search), which answers questions and helps step by step.
- An autonomous agent (Perplexity Computer), which can plan and carry out many steps on its own to deliver finished work.
Using real-world usage data, they show that agents don’t just answer questions—they execute multi-step tasks, save a lot of time and money, and let people tackle bigger and more complex projects.
Key questions the paper tries to answer
The paper focuses on four simple questions:
- Autonomy: Do AI agents actually do more of the work by themselves?
- Efficiency: Do agents finish tasks faster and at lower cost than people using a regular AI assistant?
- Scope: Do agents change the kinds of tasks people even attempt—across different jobs and difficulty levels?
- Economics: When do agents make sense? How do they shift what’s “worth doing” with a given budget of time and money?
How the researchers studied it
The authors combined a simple economic model with real usage data from Perplexity’s products.
- A simple model of task costs:
- Think of a task as a number of steps (like a recipe with many actions).
- Using an agent has a higher “setup” cost (you spend time giving clear instructions and later checking the result).
- But agents have a lower “per-step” cost because they carry out many steps on their own.
- Bottom line: for short tasks, a quick chat assistant can be enough; for longer, multi-step tasks, an agent is usually better.
- Real-world comparisons:
- They looked at millions of sessions from Feb–May 2026.
- To make fair comparisons, they paired near-identical initial queries from the same user sent to both tools (“matched pairs”). This means the same person asked the same question in both products.
- They required the agent sessions to actually “do work” (like browsing, coding, creating files, calling external services), not just chat.
- They measured:
- How much “machine work time” the AI did per session (agents vs assistants).
- What users asked in follow-up messages (clarifying vs extending vs verifying).
- How often users showed dissatisfaction.
- How long a human would take to do the same task with only the assistant (time and cost estimates from tools, an independent AI judge, and user interviews).
- Whether agent tasks crossed job boundaries (e.g., a marketer doing light coding) and required higher-order thinking or multiple skills.
Main findings and why they matter
Here are the main takeaways, written in everyday terms:
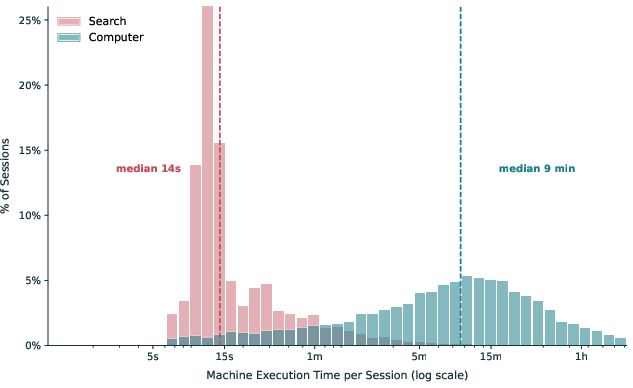
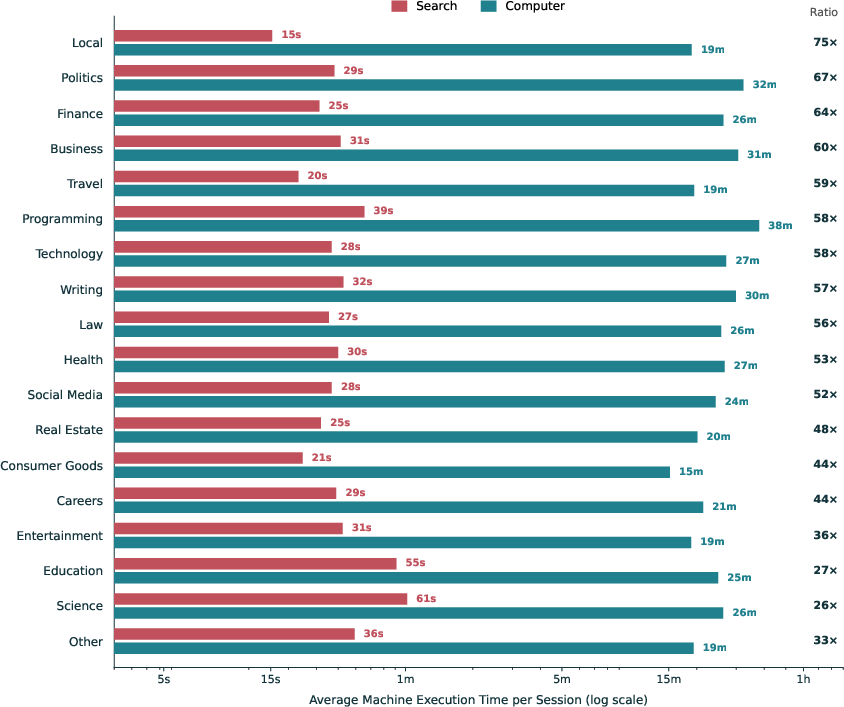
- Agents actually “do the work,” not just talk about it.
- In matched tasks, the agent (Computer) performed about 26 minutes of autonomous work per session, while the assistant (Search) did about 33 seconds—about 48 times more machine work.
- Agents also connected to other apps and services more often, chaining many actions together that a human would otherwise do manually.
- Follow-up messages shifted from “tell me more” to “build more.”
- With agents, users spent relatively more time checking and extending the output (e.g., “now add a section,” “export this”), and relatively less on back-and-forth clarifications.
- This means the agent delivers more complete drafts up front, and the human moves into “editor/manager” mode.
- Quality improved, not just speed.
- Dissatisfaction rates per query were 55% lower with the agent than with the assistant in matched cases.
- Big time and cost savings.
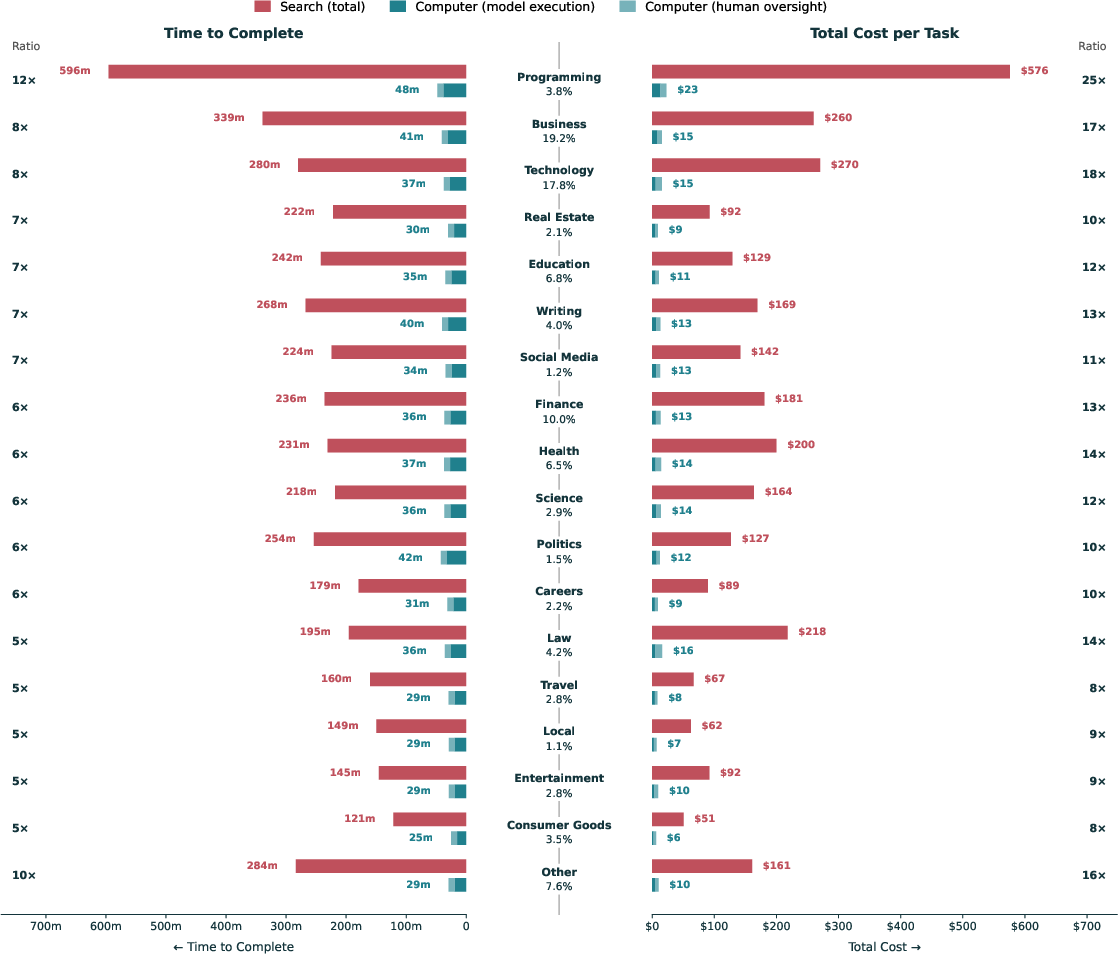
- For the same tasks, humans using only the assistant took about 269 minutes on average.
- With the agent, the combined agent+human workflow took about 36 minutes—a reduction of ~87% in time and ~94% in cost.
- To match the cost of the agent+human approach, a human using only the assistant would have to complete all the manual steps in under 20 minutes, which is rarely realistic for multi-step work.
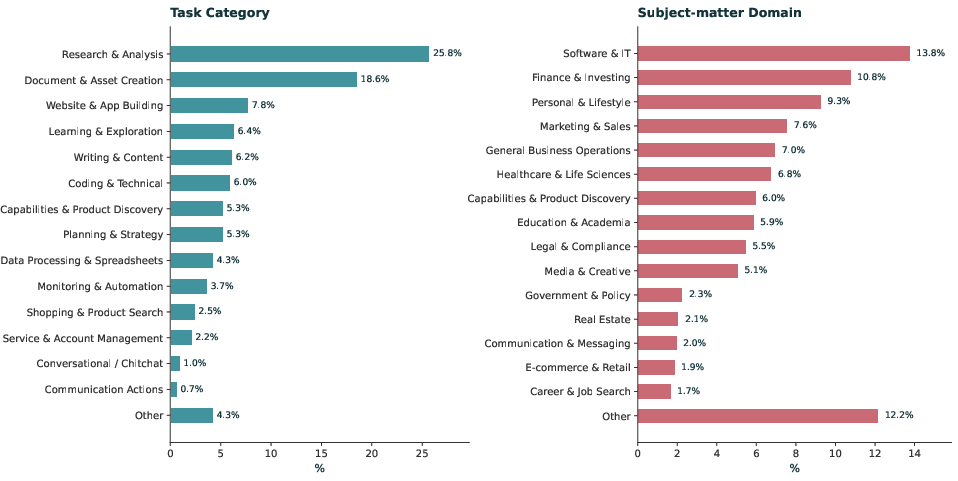
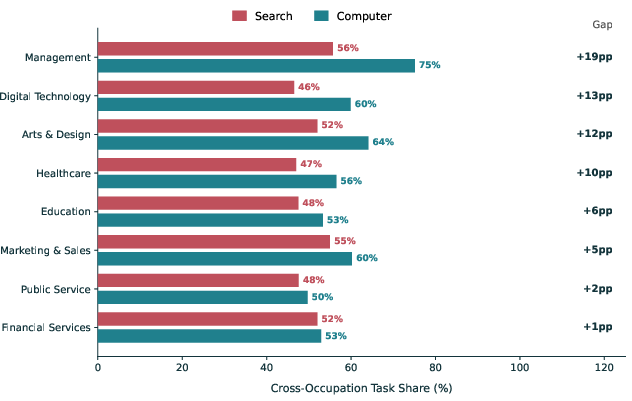
- Agents expand what people try to do.
- Across 8 job areas (like technology, finance, healthcare, education), people using agents more often crossed into tasks outside their usual field.
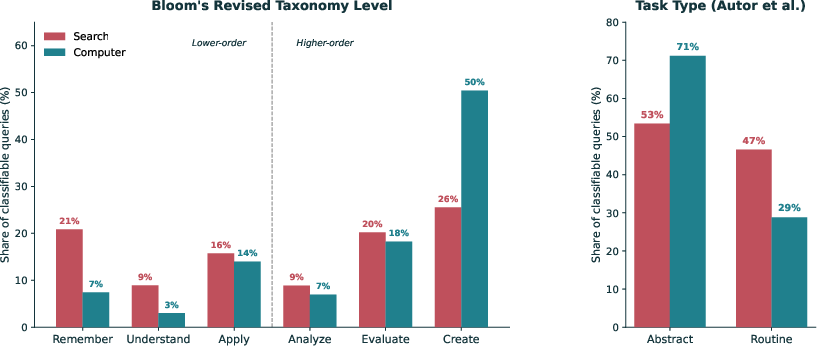
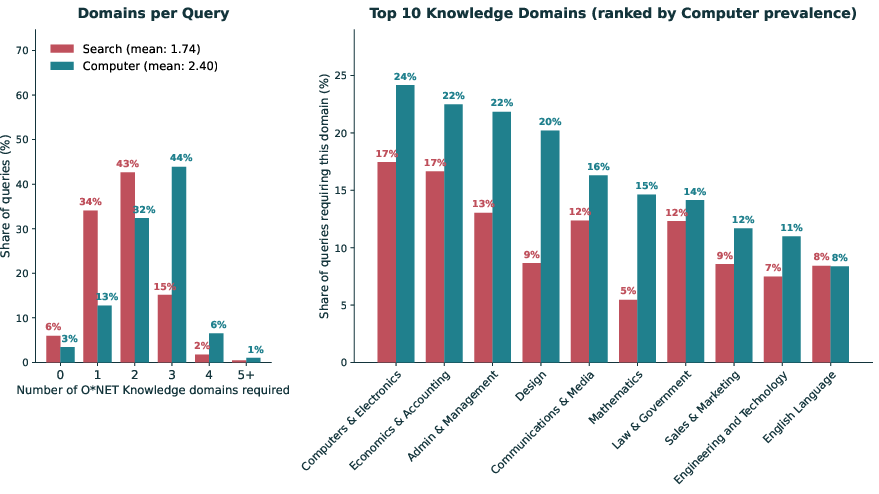
- Agent tasks required higher-order thinking (more “create” and “analyze,” less routine lookup), drew on more areas of knowledge at once, and bundled multiple subtasks into a single request.
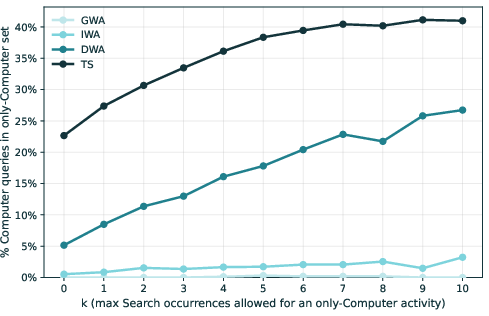
- About 23% of agent tasks included fine-grained activities that the same users never attempted with the assistant—suggesting agents unlock new kinds of work, especially at the execution level (like generating code, documents, spreadsheets, or websites).
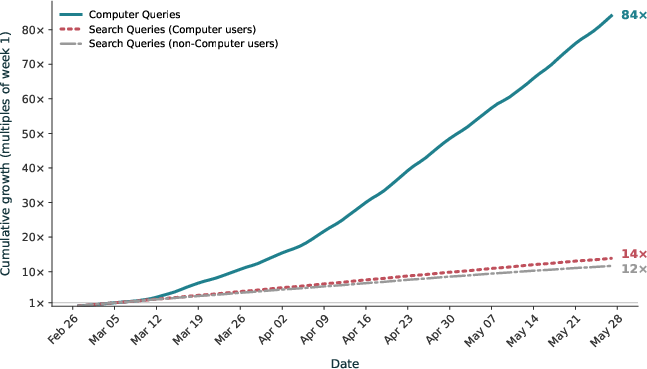
- Adoption grew quickly.
- After launch, agent usage grew fast, and people who adopted agents also used the assistant more—suggesting the tools can complement each other instead of replacing one another.
Why this matters: These results show agents don’t just speed up existing steps; they re-shape workflows. People can act more like small teams: the agent produces, and the person reviews, guides, and extends.
What it means going forward
- Bigger tasks become “worth it.”
- The model and the data agree: agents have a higher setup cost but far lower per-step cost. That means tasks with many steps—once too slow or expensive—become doable within a normal time or budget.
- As a result, the “frontier” of affordable work moves outward: more ambitious projects fit into the same day.
- Skills and roles shift.
- Humans spend more time specifying goals, checking results, and deciding what to do next—in other words, managing the agent and verifying quality—rather than doing every step by hand.
- Less coordination across multiple people for certain tasks.
- Because agents bundle and execute many steps, individuals can handle tasks that used to require handoffs across different roles, lowering coordination costs.
- Broader impact on jobs and organizations.
- If individuals can cross boundaries and complete more complex, multi-skill work, teams may reorganize around oversight, judgment, and integration, not just step-by-step production.
- Important limits and care points.
- Not every task fits the agent model—short, simple tasks are still faster with a quick assistant.
- Verification remains essential: agents are powerful but still need human review.
- The study is based on one product ecosystem and on observed logs; results may vary by task type, domain, or tool.
In short: AI agents don’t just give answers—they carry out work. They save lots of time and money, produce higher-quality outputs, and encourage people to attempt bigger, more complex projects. As this shift continues, people’s jobs may involve more directing and validating, and less manual execution.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what the paper leaves missing, uncertain, or unexplored, framed to guide concrete future research.
- Causal identification beyond matched sessions: Despite near-identical initial queries, users self-select which product to use and when; unobserved factors (e.g., urgency, stakes, user confidence) may still confound comparisons. A randomized assignment of tasks to Search vs. Computer (or encouragement designs) is needed to establish causal effects.
- Representativeness of dual-product users: Analyses focus on users who adopt both products, likely skewing toward tech-savvy early adopters. It remains unclear how results generalize to typical users, late adopters, or low-skill populations.
- Short observation window: The three-month post-launch window may capture novelty and rapid iteration effects, not steady-state behavior. Longitudinal studies should track learning curves, sustained usage, changing task mix, and durability of gains over 6–18 months.
- Framework quantities unmeasured: The theory’s fixed delegation cost, marginal step cost, and task step counts are not empirically identified. Concrete measurement/estimation of , , , , and step counts per task is needed to validate the model and its sorting threshold .
- Welfare and value are assumed, not measured: The core predictions about realized value, surplus, and value-to-cost ratios remain untested because task value is unobserved. Future work should elicit deliverable value via blinded expert ratings, downstream business metrics, or user willingness-to-pay.
- Autonomy metric conflates efficiency and latency: “Machine execution time” (wall-clock) may mix productive work with retries, waits, or inefficiencies and underestimates parallelized work. More granular telemetry (e.g., successful vs. failed tool calls, retry rates, idle/wait time) is required to isolate true autonomy.
- Runtime capping and parallelism: Capping at 3 hours truncates the right tail, and parallel execution means wall-clock undercounts total machine work. Tail behavior and full machine-time accounting (aggregate CPU/GPU-seconds) remain unknown.
- Task equivalence beyond the first turn: Near-identical initial queries can diverge due to agent planning or tool suggestions, so matched sessions may not reflect the same completed task. Auditing deliverables for functional equivalence is needed.
- Quality measurement is narrow: The paper uses a “next-turn dissatisfaction” proxy (incomplete in the excerpt) and lacks ground-truth accuracy, expert grading, or post-hoc human evaluations of artifacts. Failure modes (e.g., subtle errors, hallucinations, non-compliance) and their rates are not quantified.
- Success/failure rates and rework: The share of tasks successfully completed, the extent of rework required, and downstream defect rates are unreported. Benchmarking task success under explicit acceptance criteria is an open need.
- Cost model omissions: Efficiency analyses do not incorporate platform subscription fees, compute surcharges for long agent runs, overhead from integrations/security reviews, or user training time. A full cost accounting (including total cost of ownership) is needed.
- Human-time estimation uncertainty: Mapping “do” tool invocations to human-equivalent minutes rests on unvalidated assumptions; the LLM-based time estimate lacks ground truth; user interviews (n=25) are small and subject to self-report bias. Larger observational time-and-motion studies are needed.
- External validity across domains and languages: The study does not report performance by language, locale, or accessibility needs. Whether autonomy and quality gains persist in non-English or specialized regulatory environments is unknown.
- LLM-based labeling reliability: Task types, domains, Bloom levels, and O*NET mappings rely on single-model classifications without reported inter-rater reliability, calibration, or human validation. Future work should report agreement metrics and use multi-annotator adjudication.
- O*NET coverage limitations: Modern digital tasks may not map cleanly to O*NET hierarchies; “new tasks unlocked” may partly reflect taxonomy gaps rather than genuine capability expansion. Alternative and updated taxonomies should be tested.
- Heterogeneity of effects: The paper does not quantify how gains vary by user skill, occupation seniority, task complexity, or project size. Stratified analyses (e.g., novices vs. experts, small vs. large tasks) are necessary.
- Boundaries and failure cases: Conditions under which the agent underperforms (e.g., tasks beyond capability frontier, ambiguous objectives, high-stakes compliance) are not characterized. A “jagged frontier” analysis for agents is missing.
- Risk, safety, and compliance: The incidence and impact of risky behaviors (e.g., unsafe actions via connectors, privacy breaches, biased outputs, insecure code) are not measured. Audits and red-teaming focused on agentic actions and connector usage are needed.
- Connector ecosystems and reliability: Autonomy is partly driven by connector calls, but success rates, latency, brittleness, vendor differences, and error handling across connectors are not analyzed. Robustness across tool ecosystems is an open question.
- Organizational-level impacts: The paper infers reduced coordination costs but provides no team- or firm-level outcomes (throughput, cycle time, quality, release cadence). Field experiments at team and project levels are needed to track how gains propagate.
- Complementarity with existing tools: The DiD result (appendix) suggests complementarity with Search, but mechanisms (learning vs. task spillovers) are unclear and causal identification may rely on strong assumptions. Deeper causal analysis of complementarities and substitutions across tools is warranted.
- Human oversight burden and cognitive load: While delegation reduces manual steps, the cognitive demands of scoping, monitoring, and verifying agent work are not quantified. Measuring oversight time, error detection costs, and reviewer fatigue is necessary.
- Pricing and unit economics: The paper does not analyze how agent usage scales with pricing, compute costs, and billing models (e.g., per-minute vs. per-output). Demand elasticity and optimal pricing for long-horizon autonomy remain open.
- Environmental footprint: Increased machine work per session likely raises compute and energy usage; environmental costs per task are not reported. Carbon/energy intensity comparisons between workflows are needed.
- Security and data governance: Working across user environments raises security and privacy questions (e.g., data exfiltration, permission scopes). The incidence and mitigation of such risks are not quantified.
- Generalization to other agent systems: Findings are from Perplexity’s stack during early post-launch; portability to other agent frameworks, models, and enterprise settings is untested.
- Measurement under privacy constraints: The “no raw queries to analysts” policy safeguards privacy but limits deep content validation and error analysis. Methods for privacy-preserving ground-truth evaluation (e.g., secure enclaves, differentially private auditing) are needed.
- Dynamic product improvements as confounders: Rapid model and product updates during the study window may confound estimates. Version-controlled analyses that lock model/tool versions are needed for clean before-after comparisons.
- Downstream business outcomes: The paper measures task-level time reductions but not whether faster tasks translate into better project outcomes, revenue, customer satisfaction, or time-to-market in non-coding domains. Linking task gains to business KPIs remains open.
Practical Applications
Immediate Applications
The paper’s evidence that autonomous AI agents perform 26 minutes of machine work per session (vs. 33 seconds for assistants), cut task time by 87% and cost by 94%, reduce dissatisfaction by 55%, and expand cross-occupational scope yields the following deployable use cases.
- Application: Agent-led research briefs and literature reviews (Sectors: academia, healthcare, legal, finance, media)
- Value: Faster, higher-quality syntheses with citations; shifts human effort to verification and extension.
- Workflow/tools: Perplexity Computer orchestrates search, browsing, source cross-checks, and file creation; pause-for-approval prompts; connectors to academic indexes and document stores.
- Dependencies/assumptions: Access to licensed content; domain-expert verification; provenance-capture and audit logs for compliance.
- Application: Document and asset creation pipelines (Sectors: marketing, sales, product, HR)
- Value: Structured artifacts (briefs, policies, slide decks, emails) produced end-to-end; aligns with observed high share of document/asset creation.
- Workflow/tools: Agent generates drafts in Docs/Notion/CMS via connectors; approval gates; iterative extensions.
- Dependencies/assumptions: Brand/style guardrails; content review workflows; data-loss prevention controls.
- Application: Market/technical due diligence and competitive landscaping (Sectors: finance, BD, legal, strategy)
- Value: Comprehensive profiles and market maps with source triangulation; composite tasks bundled in one run.
- Workflow/tools: Browsing + API calls, spreadsheet generation, memo drafting; verification turns to validate key claims.
- Dependencies/assumptions: Data-license compliance; configurable source whitelists; risk disclosures.
- Application: FP&A and operational reporting automation (Sectors: finance, operations)
- Value: Month-end reports and commentary assembled autonomously; significant time savings on multi-step workflows.
- Workflow/tools: Connectors to BI/warehouses (Snowflake/BigQuery), Excel/Sheets; templated narratives; pause for manager approval.
- Dependencies/assumptions: Read-only, least-privilege access; reconciliations; segregation of duties.
- Application: Engineering scaffolding and test generation (Sectors: software)
- Value: Agents plan, scaffold features, generate tests, and draft PRs; humans supervise and merge (consistent with agentic coding gains in prior work).
- Workflow/tools: Repo connectors (GitHub/GitLab), code execution sandboxes, CI hooks; approval checkpoints.
- Dependencies/assumptions: Branch protection; secure token management; codebase size and context limits.
- Application: Policy/SOP drafting and regulatory mapping (Sectors: compliance, healthcare admin, manufacturing)
- Value: Drafts mapped to cited regulations; verification-focused human review.
- Workflow/tools: Knowledge retrieval + drafting; cross-references; redlining in DMS.
- Dependencies/assumptions: Attorney/compliance officer sign-off; up-to-date regulatory sources.
- Application: Curriculum, lesson planning, and assessment authoring (Sectors: education)
- Value: Create lesson plans, rubrics, quizzes; supports higher-order task creation observed in data.
- Workflow/tools: LMS connectors; banks of aligned objectives; iterative improvements based on outcomes.
- Dependencies/assumptions: Academic integrity policies; teacher oversight.
- Application: Customer support knowledge base refresh and reply drafting (Sectors: customer service, SaaS)
- Value: Faster article updates and suggested responses; verification/extension turns for correctness.
- Workflow/tools: CRM/helpdesk connectors; log parsing; doc publishing via CMS.
- Dependencies/assumptions: Access to tickets/logs; escalation rules; hallucination mitigation.
- Application: Cross-functional project bundling by single operator (Sectors: SMBs, startups, freelancers)
- Value: One person produces multi-asset packages (copy, landing page, email flows, analytics setup), reducing coordination costs.
- Workflow/tools: Web/CMS builders, email platforms, analytics connectors; agent orchestrates; user verifies.
- Dependencies/assumptions: API keys and account permissions; template libraries; clear acceptance criteria.
- Application: Verification-first QA workflows for AI outputs (Sectors: all)
- Value: Institutionalize approve/hold prompts and checklists, mirroring observed shift to verification and extension.
- Workflow/tools: Pause-for-user states, automated checklists/tests, diff viewers, sign-off trails.
- Dependencies/assumptions: Defined QA criteria; auditable logs; role-based access.
- Application: Task router for “assistant vs. agent” selection (Sectors: software/IT, enterprise IT)
- Value: Route short tasks to conversational assistants and long, multi-step tasks to agents, leveraging the step-count threshold insight.
- Workflow/tools: Step-count or complexity estimators; policy engine; monitoring.
- Dependencies/assumptions: Accurate task-complexity prediction; fallback paths; usage analytics.
- Application: Cost/time accounting dashboards for AI runs (Sectors: operations, ITFM)
- Value: Real-time ROI using per-session runtime and human/model costs; breakeven alerts (e.g., <20 min human threshold from paper).
- Workflow/tools: Telemetry on agent runtime, tool calls, human approvals; cost attribution; reporting.
- Dependencies/assumptions: Consistent logging; cost catalogs for human and model rates; tagging standards.
- Application: Talent and HR workflows (Sectors: HR, recruiting)
- Value: Draft job descriptions, screen resumes to criteria, generate interview guides; supervisors verify.
- Workflow/tools: ATS connectors; rubric-driven scoring; structured outputs.
- Dependencies/assumptions: Bias auditing; EEOC compliance; human decision-making retained.
- Application: Public-sector grant and policy memo drafting (Sectors: government, nonprofits)
- Value: Faster briefs and grant narratives; citations and data tables included; human verification loop.
- Workflow/tools: Data source connectors; document generation; approval workflows.
- Dependencies/assumptions: Privacy and data residency rules; procurement approvals; records retention.
- Application: Personal productivity automations (Sectors: daily life, sole proprietors)
- Value: Trip planning, vendor comparisons, resume tailoring, website setup with verification-first review.
- Workflow/tools: Calendar/email/CMS connectors; checklists; budget/time calculators.
- Dependencies/assumptions: Caution on high-stakes (legal/medical); explicit user permissions; privacy hygiene.
Long-Term Applications
These applications will benefit from further advances in reliability, integration, governance, and scaling, reflecting the paper’s long-horizon autonomy trajectory and broader scope shifts.
- Application: End-to-end autonomous back office (Sectors: finance, HR, procurement)
- Value: From data pulls to reconciliations and narrative commentary with minimal human touch.
- Dependencies/assumptions: Robust auditability, segregation of duties, regulatory clearance, near-zero hallucination rates.
- Application: Organizational redesign around “agent supervisors” and cross-occupational roles (Sectors: all)
- Value: Individuals own composite workflows spanning multiple occupations (consistent with observed 9 pp cross-occupation and higher cognitive complexity).
- Dependencies/assumptions: Change management, new performance metrics, labor agreements, upskilling programs.
- Application: Marketplaces and routers for specialized agents with cost-aware bidding (Sectors: software platforms)
- Value: Route tasks to the most cost-effective, capable agent; enforce SLAs.
- Dependencies/assumptions: Interoperability standards (e.g., MCP), benchmarking, billing transparency.
- Application: Regulated-domain certified agents (Sectors: healthcare, legal, finance)
- Value: Agents that meet domain-specific safety/quality thresholds (e.g., clinical documentation + order sets; first-draft legal filings).
- Dependencies/assumptions: Liability frameworks, certification regimes, human-in-the-loop mandates.
- Application: Persistent, long-horizon autonomous projects (Sectors: R&D, software migrations, policy analysis)
- Value: Agents run for days/weeks across workstreams, checkpointing progress and adapting plans.
- Dependencies/assumptions: Reliable memory/state management, robust failure recovery, monitoring and pause/override controls.
- Application: Standardized agent metrics and audits for procurement and compliance (Sectors: enterprise, public sector)
- Value: Adopt “time horizon,” autonomy minutes, and dissatisfaction rates as purchase and oversight metrics.
- Dependencies/assumptions: Industry consensus, third-party auditors, shared benchmarks.
- Application: Education transformation with agent-tutor orchestration (Sectors: education)
- Value: Mastery learning loops, individualized curricula, auto-grading with human spot checks.
- Dependencies/assumptions: Pedagogical validation, equity considerations, academic integrity safeguards.
- Application: Large-scale public service automation (Sectors: government)
- Value: Benefits processing, FOIA responses, case triage with transparency and fairness constraints.
- Dependencies/assumptions: Legacy system integration, privacy laws, bias mitigation and oversight.
- Application: Real-world action via RPA/IoT/edge devices (Sectors: facilities, labs, logistics)
- Value: Agents that act beyond software—instrument control, facility scheduling, routine operations.
- Dependencies/assumptions: Secure physical interfaces, safety interlocks, incident response protocols.
- Application: Updated risk, insurance, and compliance models for agent-run operations (Sectors: finance, cyber)
- Value: New underwriting for agent-related operational/cyber risks; continuous control monitoring.
- Dependencies/assumptions: Incident datasets, reporting standards, regulatory guidance.
- Application: Labor-market policy responses (Sectors: policy)
- Value: Targeted reskilling, wage insurance, portable benefits aligned with task recomposition dynamics.
- Dependencies/assumptions: Funding and political will; longitudinal evidence on displacement vs. reinstatement.
- Application: Enterprise data clean rooms and fine-grained permissions for agents (Sectors: enterprise IT)
- Value: Secure, auditable agent access to sensitive data with context integration at scale.
- Dependencies/assumptions: Robust identity/permissions, data residency controls, privacy-by-design.
Notes on Feasibility Assumptions
- Task economics: Gains are largest on high-step tasks that amortize delegation overhead; task routers should estimate step/complexity to maximize ROI.
- Reliability and safety: Verification-first workflows, audit trails, and human approvals are critical, especially in regulated or high-stakes contexts.
- Integration: Benefits depend on connectors (APIs, MCP) to apps, data warehouses, repos, and content systems; permissions and security are prerequisites.
- Measurement: Telemetry on autonomy time, connector calls, dissatisfaction signals, and costs is necessary for governance and continuous improvement.
- Change management: Cross-occupational scope expansion implies training, new roles (agent supervisors), and updated performance and accountability frameworks.
Glossary
- 0-1 knapsack problem: A combinatorial optimization problem where items with values and costs are selected to maximize value under a budget constraint, each chosen at most once. "The user therefore solves a standard 0-1 knapsack problem"
- Affordable task frontier: The boundary of tasks that can be completed within a given budget or resource constraint. "agent access expands the affordable task frontier toward weakly higher-value tasks"
- Agent orchestration: Coordinating multiple tools, steps, and sub-agents to autonomously plan and execute tasks. "the shift from conversational assistants to agent orchestration across a wide spectrum of knowledge work."
- Agent orchestration system: A platform that manages planning and multi-tool execution across environments to fulfill delegated outcomes. "Computer is a general-purpose agent orchestration system that performs work across increasingly broad environments and long horizons."
- Agent orchestrator: An agent that coordinates other tools or agents to carry out complex workflows. "Computer combines long-horizon asynchronous execution with even deeper and broader context integration as an agent orchestrator."
- Agentic browser: A web browser that embeds autonomous agent capabilities to act within web contexts. "Perplexity's Comet agentic browser"
- Answer engine (product category): A system that returns synthesized, cited answers to user queries rather than just links. "Perplexity Search introduced the answer engine product category: it allows a user to ask a question and receive a cited, synthesized answer from a knowledge base comprising billions of documents."
- Application Programming Interface (API): A standardized interface for software to communicate with external services or applications. "via Model Context Protocol (MCP) or an Application Programming Interface (API) endpoint"
- Asynchronous delegation: Assigning tasks to an agent to execute independently over time without continuous user interaction. "Our setting differs because Computer replaces the interactive loop with asynchronous delegation."
- Autonomy premium: The cost advantage per step gained by autonomous execution compared to human-in-the-loop execution. "their gap is the autonomy premium."
- Bloom's Revised Taxonomy: A framework classifying cognitive complexity levels from remembering to creating. "cognitive complexity (Bloom's Revised Taxonomy and routine versus abstract task types)"
- Breakeven analysis: An evaluation identifying the point at which two options have equal cost or performance. "A breakeven analysis shows that a Search-aided human professional would need to complete all manual steps in under 20~minutes to match the cost of Computer~+~Human."
- Capability frontier: The boundary delineating tasks that a model or system can perform successfully. "tasks within the model's capability frontier"
- Composite tasks: Single requests that bundle multiple interdependent subtasks into one larger task. "take the form of composite tasks that bundle interdependent subtasks into a single query"
- Connector call: An invocation from an agent to an external application or service via a connector. "7.9\% of Computer sessions invoke at least one connector call versus 1.8\% of Search sessions"
- Cosine similarity: A metric for measuring similarity between two vector embeddings based on the cosine of the angle between them. "(cosine similarity )"
- Difference-in-differences design: A causal inference method comparing changes over time between treated and control groups. "we isolate the causal effect with a matched difference-in-differences design"
- Dynamic programming: An algorithmic technique solving problems by breaking them into overlapping subproblems and reusing solutions. "We describe a standard dynamic programming solution in Appendix~\ref{app:dp}."
- End-to-end work execution engine: A system that plans and completes tasks from start to finish with minimal human intervention. "The shift is from AI as a conversational assistant to AI as an end-to-end work execution engine, characterized by greater autonomy and deeper integration into the user's entire digital environment."
- Fixed per-task cost: A one-time cost incurred for delegating or initiating a task, independent of the number of steps. "Each mode has a fixed per-task cost:"
- Frontier AI systems: The most advanced AI models and products at the cutting edge of capabilities. "Frontier AI systems are bridging the gap between intelligence and utility by shifting from conversational assistants to autonomous agents that execute tasks end to end."
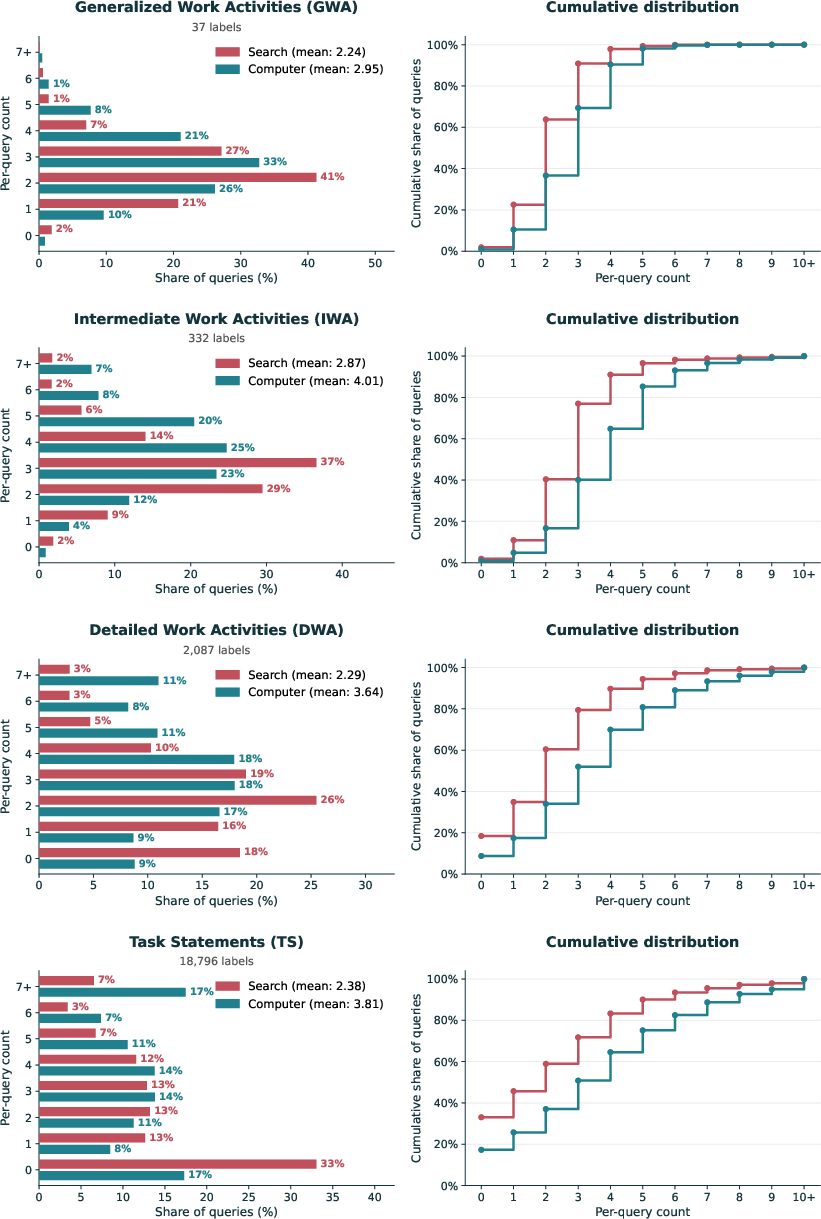
- Generalized Work Activities: High-level categories of work behaviors from the O*NET taxonomy used to describe job tasks. "Computer queries engage 2.95 of O*NET's Generalized Work Activities on average"
- Human bottlenecks: Constraints in workflows where human involvement limits throughput or progress. "consistent with human bottlenecks limiting how much reaches shipped software."
- Human-equivalent minutes: An estimate translating automated tool execution into the minutes a human would spend to perform the same steps. "The tool-based estimate sums human-equivalent minutes for each ``do'' tool invocation observed in the Computer thread"
- Human-in-the-loop: A system design where humans participate in or supervise the execution of task steps. "the human-in-the-loop cost per step"
- Indivisible (tasks): Tasks that must be completed in full to realize value; partial completion yields no value. "Equivalently, task opportunities are indivisible: a user attempts task in full or not at all."
- Jagged frontier: The uneven boundary where AI excels at some tasks but fails at others of similar apparent difficulty. "a ``jagged frontier'' that underscores the importance of task--tool fit."
- Long-horizon: Involving extended durations or many steps to complete tasks. "long-horizon asynchronous execution"
- Model Context Protocol (MCP): A protocol for connecting models to external tools and data sources. "via Model Context Protocol (MCP) or an Application Programming Interface (API) endpoint"
- Natural experiments: Observational settings where external conditions approximate random assignment, allowing causal inference. "using sessions with near-identical initial query pairs as natural experiments for the same underlying task"
- O*NET Knowledge domains: Subject areas from O*NET describing the bodies of knowledge required for jobs. "each Computer query requires substantive expertise in an average of 2.40 distinct O*NET Knowledge domains"
- O-ring model: An economic model of multi-step production emphasizing that failures in any step can reduce overall output. "extend the O-ring model of multi-step production to show that the return to automation is limited by the human bottlenecks in the process."
- Occupation-specific Task Statements: Fine-grained task descriptors tied to specific occupations in O*NET. "and 60\% more occupation-specific Task Statements (3.81 vs.\ 2.38) engaged per query."
- Task recomposition: The restructuring of job tasks into new bundles due to technology or process changes. "autonomous agent capabilities, and task recomposition."
- Task-based framework: An analytical approach modeling work as collections of discrete steps or tasks with associated costs and values. "We adopt an individual-level task-based framework"
- Time horizon metric: A measure of the duration at which agents achieve a target success rate on tasks. "\citet{kwa2025measuring} introduce the ``time horizon'' metric (the task duration at which agents achieve 50\% success rate)"
- Usage-based measure: An empirical metric constructed from real usage data to assess exposure or impact. "\citet{massenkoff2026labor} introduce a usage-based measure of AI exposure to document a capability-deployment gap across occupations."
- Value-to-cost ratio: A performance metric comparing the value generated to the cost incurred. "when the pre-agent budget binds, surplus and the value-to-cost ratio also weakly increase."
- Wall-clock time: Actual elapsed time from start to finish, as experienced by users, regardless of parallelization. "For Computer, we compute per-turn wall-clock time"
Collections
Sign up for free to add this paper to one or more collections.