You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
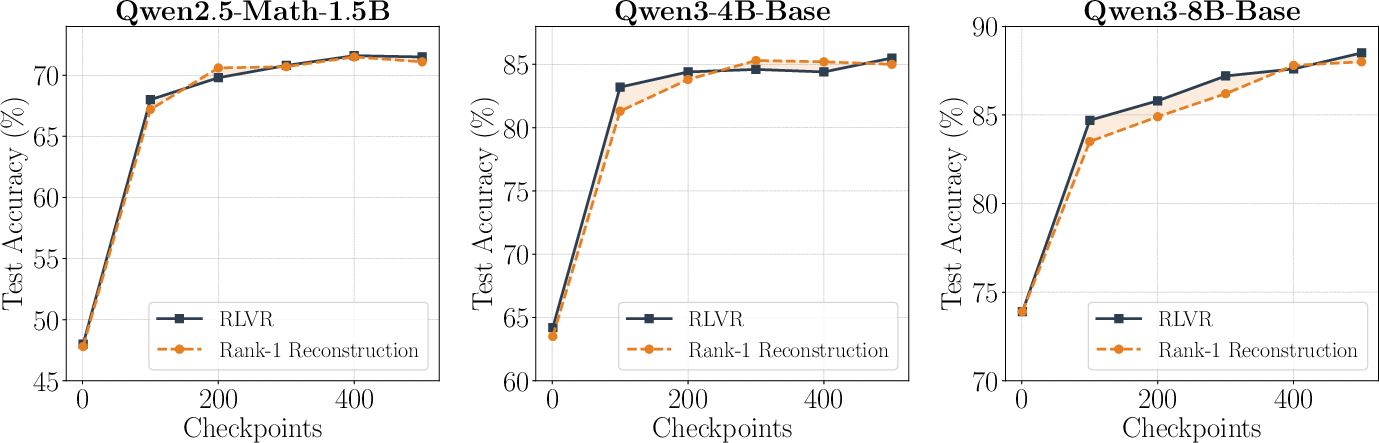
Abstract: Reinforcement learning with verifiable rewards (RLVR) has become a dominant paradigm for improving reasoning in LLMs, yet the underlying geometry of the resulting parameter trajectories remains underexplored. In this work, we demonstrate that RLVR weight trajectories are extremely low-rank and highly predictable. Specifically, we find that the majority of downstream performance gains are captured by a rank-1 approximation of the parameter deltas, where the magnitude of this projection evolves near-linearly with training steps. Motivated by this, we propose a simple and compute-efficient method RELEX (REinforcement Learning EXtrapolation), which estimates the rank-1 subspace from a short observation window and extrapolates future checkpoints via linear regression, with no learned model required. Across three models (i.e., Qwen2.5-Math-1.5B, Qwen3-4B-Base, and Qwen3-8B-Base), RELEX produces checkpoints that match or exceed RLVR performance on both in-domain and out-of-domain benchmarks, requiring as few as 15% steps of full RLVR training. Remarkably, RELEX is able to extrapolate far beyond the observation window at no training cost, predicting checkpoints up to 10-20$\times$ beyond the observed prefix with continued improvement (e.g., observe only the first 50 steps and extrapolate to 1000 steps). Our ablation analysis confirms the minimalist sufficiency of RELEX: neither increasing the subspace rank nor employing non-linear modeling yields further gains in extrapolation. Finally, we show that RELEX's success stems from a "denoising" effect: by projecting updates onto the rank-1 subspace, the model discards stochastic optimization noise that would otherwise degrade performance during extrapolation. Our code is available at https://github.com/weizhepei/RELEX.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories”
What is this paper about?
This paper is about a faster way to train big LLMs to get better at step-by-step reasoning, especially in math. Today, many teams use a method called RLVR (Reinforcement Learning with Verifiable Rewards), which rewards a model when it gives an answer a program can check as correct (like solving a math problem). RLVR works, but it takes a lot of time and computer power.
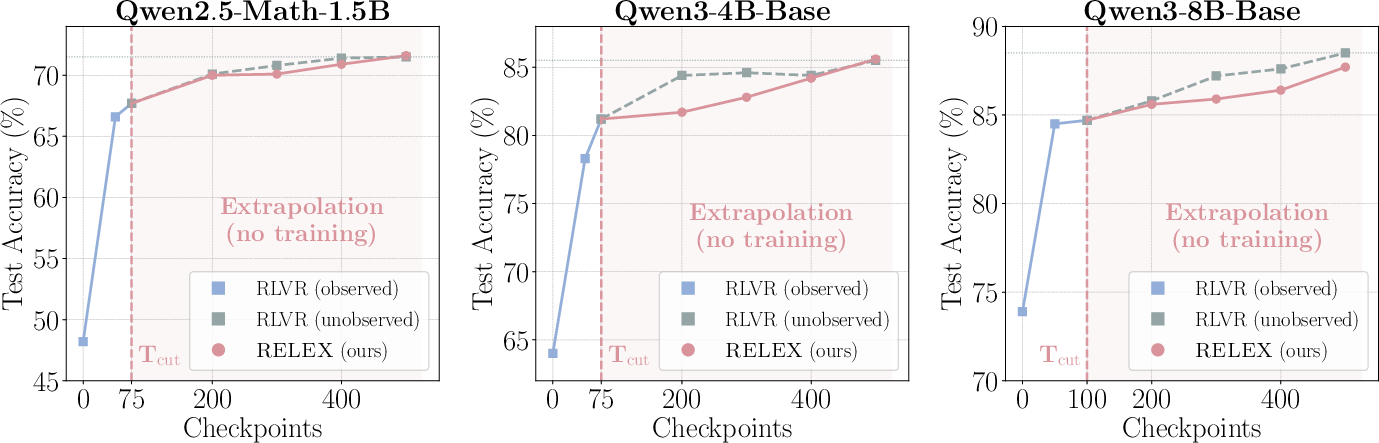
The authors show that you don’t always need to run the full, expensive training. By watching only the early part of training and using some smart math, you can “predict” where the model would end up later—and skip most of the training. Their simple method is called RELEX.
What questions did the researchers ask?
In simple terms, they asked:
- While a model is being trained with RLVR, do the model’s internal numbers (its “weights”) move in a simple, predictable way?
- If the movement is predictable, can we look at just the first part of training, figure out the trend, and jump ahead—creating later “checkpoints” (saved versions of the model) without actually doing the training to get there?
- Can this shortcut match or even beat normal training on math tests?
How did they study it? (Methods explained simply)
Think of training like a long hike where you save your location every few minutes (these saves are “checkpoints”). The model’s “weights” are like the GPS coordinates of your exact spot in a huge landscape.
Here’s their approach, in everyday language:
- Watch the early part of the hike:
- They record how the model’s weights change over the first chunk of RLVR training (for example, the first 15% of steps).
- Find the main direction of movement:
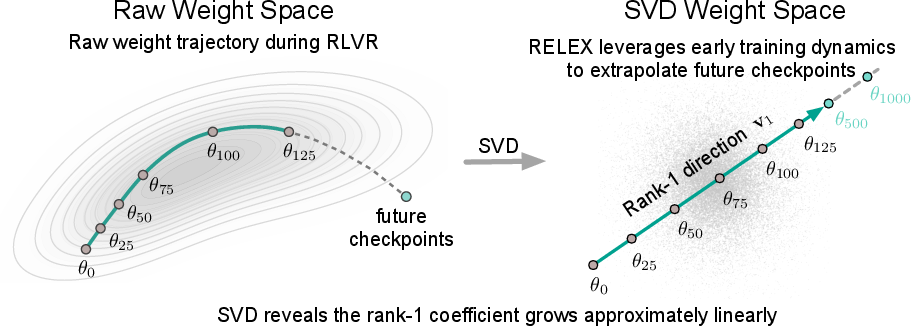
- They use a math tool (SVD, short for Singular Value Decomposition) that says: “Even though the model’s weights are super high-dimensional, almost all the important change is happening along one main direction.” Think of it like: instead of wandering in a big field, you’re mostly walking along a straight path.
- “Rank-1” just means “one main direction.”
- Measure how far along that direction the model goes at each step:
- They track a single number that tells how far the model has moved along that main direction over time.
- Surprisingly, this number grows almost like a straight line as training goes on (very close to perfectly linear).
- Extrapolate (predict the future):
- If your steps along a straight path increase at a steady pace, you can predict where you’ll be later without actually walking there.
- RELEX fits a simple straight line to the early steps, then “jumps ahead” to create future checkpoints as if the model had kept training—no extra training needed.
A helpful analogy:
- Imagine filming the first few seconds of a runner who speeds up to a steady pace on a track. If their speed becomes steady, you can guess where they’ll be at 1 minute without filming the whole minute. RELEX does that for model training.
What did they find, and why is it important?
Here are the key findings:
- The updates are low-rank (mostly one direction):
- Even though the model has millions or billions of weights, the changes that matter for getting better at math mostly follow a single direction. That’s “rank-1.”
- The progress along that direction is nearly a straight line:
- The “how far along the path” number fits a straight line extremely well (think: a near-perfect trend).
- RELEX can replace most RLVR steps:
- After observing only about 15–20% of the training, RELEX can predict later checkpoints that match or even beat full RLVR on many tests.
- On three different models (Qwen2.5-Math-1.5B, Qwen3-4B-Base, Qwen3-8B-Base), RELEX reached in-domain MATH accuracy equal to or close to the full training, and often did as well or better on out-of-domain math competitions (like AIME, HMMT, OlympiadBench, AMC).
- It can extrapolate very far:
- In some cases, they watched just the first 50 steps and predicted model checkpoints as far as 1000 steps—a 20× jump—still improving performance.
- Simple is best:
- Using only one direction (rank-1) and a straight-line fit worked best. Adding more directions or using fancy non-linear models didn’t help—and sometimes made things worse.
- “Denoising” effect:
- Projecting changes onto the one main direction removes random wiggles (training “noise”) that can hurt predictions. It’s like smoothing a shaky path and keeping only the true trend.
Why this matters:
- Massive time and cost savings: You can get near full-training performance after only a small fraction of the training, saving electricity, money, and time.
- Better understanding of training: It reveals that RLVR training, despite being complex, often follows a surprisingly simple path.
What could this change or lead to?
- Faster iteration: Teams can try ideas quickly—train a bit, predict the rest, and evaluate—without weeks of compute.
- Greener AI: Less energy used for training large models.
- New tools for training planning: If early training tells you the end result, you can stop early or correct course sooner.
- Deeper insight: It suggests that many improvements in reasoning come from moving steadily along one key direction already present in the model, rather than learning everything from scratch.
Notes and limitations
- Picking the observation window matters:
- How much early training you observe can affect how far and how accurately you can predict. The “best” window differed by model.
- Studied mainly on math and certain models/algorithms:
- Results are shown on Qwen-family models with a specific RLVR setup. More testing is needed for other tasks (like code), other model families, and other RL methods.
- Rank-1 worked best here:
- While rank-1 was enough in this study, different settings might need adaptive choices.
In one sentence
By noticing that RLVR training mostly moves a model’s weights along one main direction at a steady pace, RELEX can watch the beginning of training and accurately “skip ahead,” achieving near full performance with a fraction of the cost.
Knowledge Gaps
The paper leaves the following knowledge gaps, limitations, and open questions that future work could address:
- Generality beyond GRPO and math: verify low-rank, near-linear trajectories under other RL algorithms (e.g., PPO, DPO/RLAIF variants), task types (code generation, tool use, theorem proving), and model families/sizes (e.g., Llama/Mistral, 13B–70B+).
- Sensitivity to observation-window choice: develop and evaluate adaptive cutoff selection (e.g., using subspace drift, principal-angle change, or singular-value gaps) and quantify performance vs. window size systematically.
- Stationarity of the rank-1 direction: measure how the dominant subspace rotates over training (principal-angle trajectories) and identify conditions or phases when rank-1 ceases to be stable.
- Detecting linearity breakdowns: provide diagnostics to flag nonlinearity (e.g., residual analysis, change-point detection) and test piecewise-linear or segmented regression as fallback.
- When rank-1 is insufficient: design criteria for adaptive per-tensor rank selection based on explained variance and out-of-sample forecast error, and test whether modest ranks (r=2–4) help in nonstationary regimes.
- Cross-tensor dependencies: assess whether a joint low-rank model across layers (e.g., block/tensor decomposition or shared latent trajectories) improves extrapolation over independent per-tensor SVDs.
- Robustness across seeds and hyperparameters: replicate results under multiple random seeds, optimizers, batch sizes, KL penalties, and learning-rate schedules; report variance and confidence intervals.
- Theoretical guarantees: formalize conditions under which RLVR induces low-rank, near-linear dynamics (e.g., due to KL regularization or verifier structure) and provide error bounds for RELEX extrapolations.
- Long-horizon stability: characterize when extrapolations overshoot or degrade (e.g., Qwen3-4B at 1000 steps) and propose guardrails (uncertainty thresholds, confidence-aware clipping, re-anchoring checkpoints).
- Compute/memory footprint at scale: quantify SVD and checkpoint storage costs for very large models; develop streaming/incremental SVD that avoids retaining all prefix checkpoints and supports distributed training.
- Baseline completeness: compare against EMA/Polyak weight averaging, checkpoint ensembling, multi-point ridge regression in weight space, and temporal smoothing filters as denoising alternatives.
- Causal evidence for “spectral denoising”: isolate and quantify the noise removed by rank-1 projection vs. time-domain smoothing; test whether denoising alone (without extrapolation) improves checkpoints.
- Layer/module granularity: identify which layers (attention vs. MLP, early vs. late) dominate the rank-1 signal, and evaluate targeted extrapolation per module to reduce computation or improve stability.
- Data/process changes mid-training: study effects of dataset refresh, dynamic verifier difficulty, KL scheduling, or optimizer switches on subspace linearity and RELEX reliability.
- Sparse checkpoint sampling: determine minimal sampling frequency and prefix length needed for accurate subspace estimation; evaluate performance when only periodic checkpoints are available.
- Compatibility with parameter-efficient finetuning: test RELEX on LoRA/Adapter updates and compare subspace structure in adapter vs. full-weight deltas for efficiency benefits.
- Online/interactive variants: explore incremental subspace tracking with occasional RL steps (re-anchoring) to maintain stability over very long horizons.
- Trainability of extrapolated checkpoints: assess whether RELEX-produced checkpoints remain good starting points for continued RL or SFT without optimization instabilities.
- Broader evaluation beyond math OOD: include reasoning-heavy but non-math domains (commonsense, planning), multilingual settings, and tools-integrated tasks to test transferability claims.
- Metrics beyond accuracy: evaluate calibration, solution robustness, reasoning chain quality, and verification efficiency to ensure extrapolated models do not trade off reliability for accuracy.
- Safety and alignment effects: measure toxicity, honesty, reward hacking, and specification gaming under extrapolation to ensure “denoising” does not amplify undesirable behaviors.
- Failure-mode analysis: report the fraction and characteristics of tensors not meeting the R2 > 0.98 criterion, and investigate model-specific failure patterns (e.g., Qwen3-4B long-horizon drop).
- Subspace choice policy: formalize a principled selection policy (rank, window size, tensor inclusion) driven by validation forecasts rather than post-hoc performance.
- Reproducibility details: release seeds, exact hyperparameters, and significance tests for all tables, and quantify sensitivity to implementation choices (e.g., float precision, SVD truncation method).
Practical Applications
Immediate Applications
Below are concrete, deployable uses of the paper’s findings and RELEX method that can be adopted with today’s tooling, especially for RLVR/GRPO-style reasoning fine-tuning in LLMs.
- RLVR cost and time reduction for reasoning models
- Sectors: software/AI labs, education tech, finance (quant/math), research
- What: Run only 15–20% of RLVR steps, then extrapolate checkpoints with RELEX to match or approximate full-run performance; use the extrapolated “best step” as the production model.
- Tools/workflows: “relex-extrapolate” script/CLI; integration into RLHF/RLVR frameworks (e.g., TRL, HybridFlow) as a training callback; CI job that triggers extrapolation after N steps.
- Assumptions/dependencies: Access to per-step/sparse checkpoints in the first 15–20% of training; rank-1 near-linearity holds on the target model/task; verifiable rewards (e.g., math correctness); observation-window size tuned per model family.
- Early stopping and budget forecasting for RLVR runs
- Sectors: MLOps, cloud-cost optimization, project management
- What: Fit rank-1 trajectories in the first few checkpoints to forecast expected final accuracy, enabling early stop decisions and compute budgeting before full cost is incurred.
- Tools/workflows: Training dashboards that display projected learning curves from RELEX; automatic stop/continue rules based on projected plateau.
- Assumptions/dependencies: Stability of linear fit on the target setup; stored early checkpoints; monitoring of R² and singular-value gaps to detect when projections are unreliable.
- Checkpoint denoising/post-processing to improve robustness
- Sectors: model QA, evaluation and release engineering
- What: Apply rank-1 projection (without extrapolating steps) to existing RLVR checkpoints to reduce stochastic optimization noise and sometimes improve OOD generalization.
- Tools/workflows: “relex-denoise” post-processing pass before evaluation or release.
- Assumptions/dependencies: Dominant component captures task-relevant signal; verify no regression on safety/alignment tests.
- Fast seed/hyperparameter selection
- Sectors: research, platform teams optimizing RLVR pipelines
- What: Train multiple seeds/hyperparams for a short prefix, use RELEX to extrapolate their projected endpoints, and advance only the most promising runs.
- Tools/workflows: “relex-ranker” to score seeds/hparams from early checkpoints; orchestration with Ray/Tune or internal schedulers.
- Assumptions/dependencies: Rank-order correlation between extrapolated and fully trained performance; careful handling of observation-window sensitivity.
- Long-horizon checkpoint generation without training
- Sectors: internal benchmarking, academic evaluation
- What: Produce checkpoints far beyond the observed prefix (e.g., 10–20× more steps) to probe trends, run ablations, or test OOD behavior—at zero additional training cost.
- Tools/workflows: Batch generation of synthetic future checkpoints for downstream eval pipelines.
- Assumptions/dependencies: Extrapolation stability depends on window choice and model family; validate with holdout evaluation.
- Storage-efficient checkpoint archiving and reproducibility
- Sectors: MLOps, model hubs
- What: Store base weights + per-tensor rank-1 vector + linear coefficients instead of hundreds of checkpoints; reconstruct any intermediate step on demand.
- Tools/workflows: “relex-pack” (codec) for checkpoint compression and “relex-unpack” to reconstruct step T.
- Assumptions/dependencies: Consumers accept reconstructed checkpoints; versioning of the observation window and fit metadata; compatibility with tensor formats.
- Compute and carbon reporting for ESG initiatives
- Sectors: policy/ESG reporting, sustainability teams
- What: Quantify compute and carbon savings from RELEX-assisted training vs full RLVR; include in sustainability scorecards and procurement decisions.
- Tools/workflows: Carbon calculators integrated with training logs; “what-if” reports using RELEX projections.
- Assumptions/dependencies: Transparent baselines and consistent measurement; acceptance by auditors.
- Model robustness and safety regression testing
- Sectors: AI safety, evaluation teams
- What: Use RELEX-extrapolated and rank-1–denoised checkpoints as stress-test variants in OOD and safety harnesses (e.g., jailbreak, spec-violation assessments).
- Tools/workflows: Evaluation suite that sweeps base/RLVR/RELEX checkpoints to detect regressions.
- Assumptions/dependencies: Safety metrics available; governance sign-off to ship extrapolated variants internally.
- Democratized fine-tuning for small orgs and individuals
- Sectors: open-source, indie labs, education
- What: Fine-tune reasoning models on modest hardware by running a short RLVR window and extrapolating; deploy extrapolated checkpoints for classroom, competition prep, or small product pilots.
- Tools/workflows: Open-source RELEX repo and recipes for Qwen2.5/Qwen3; Colab/A100 one-day guides.
- Assumptions/dependencies: Access to verifiable-reward datasets; licensing of base models; careful evaluation before public deployment.
Long-Term Applications
These opportunities likely require additional research, validation beyond math RLVR, or productization across tasks/model families.
- Generalization beyond math RLVR to dialogue alignment, code, tool-use
- Sectors: chatbots, developer tools, enterprise assistants
- What: Apply RELEX to PPO/GRPO RLHF for safety/alignment, coding correctness, or tool orchestration.
- Tools/products: “RELEX-for-RLHF” plugin in alignment stacks; SDKs for code evaluators/verifiers.
- Assumptions/dependencies: Rank-1 near-linearity must hold under different reward types and model families; access to verifiable or proxy-verifiable rewards.
- Online, adaptive-rank subspace tracking during training
- Sectors: training frameworks (DeepSpeed, vLLM/TRL plugins)
- What: Monitor subspace drift and singular-value gaps; adapt observation window and rank automatically; switch between extrapolation and short refresh runs.
- Tools/products: “RELEX-Online” scheduler that interleaves training with subspace updates.
- Assumptions/dependencies: Reliable drift detection; low-overhead per-tensor SVD; stability guarantees.
- Low-rank RL adapters as “reasoning directions”
- Sectors: model hubs, multi-task systems, education/finance/legal domain assistants
- What: Package rank-1 update vectors as LoRA-style adapters that can be composed or transferred across related tasks to inject reasoning gains quickly.
- Tools/products: “Reasoning Direction LoRA” packs on model hubs; adapter composition UIs.
- Assumptions/dependencies: Transferability of dominant directions across tasks/models; licensing for redistribution.
- Personalized and privacy-preserving on-device adaptation
- Sectors: mobile, healthcare, assistive tech
- What: Run a brief on-device RLVR session with verifiable rewards (e.g., correctness checks for a user’s tasks) and extrapolate low-rank updates, keeping data local.
- Tools/products: Lightweight SVD kernels and RELEX runtime for edge NPUs.
- Assumptions/dependencies: Efficient per-tensor SVD on device; safe reward design; strong privacy constraints.
- Compute-aware schedulers and cloud auto-bidding
- Sectors: cloud providers, FinOps, platform teams
- What: Use RELEX forecasts to plan spot instance usage, pause/resume policies, and budget caps; “pay only until confidence threshold is met.”
- Tools/products: Cloud SDK integrations that react to projected gains vs costs.
- Assumptions/dependencies: Integration with billing APIs; reliable forecast confidence intervals.
- Governance, auditing, and disclosure standards
- Sectors: policy, regulators, auditing firms
- What: Use early-dynamics signatures and rank-1 predictability as one signal to validate training claims (e.g., “we trained for X steps on Y data”).
- Tools/products: Audit protocols/lint rules for checkpoint lineage and linearity diagnostics.
- Assumptions/dependencies: Access to (hashed) early checkpoints; risk of gaming; need for multi-signal audits.
- Hardware–software co-design for low-rank training dynamics
- Sectors: semiconductor, systems research
- What: Accelerators and kernels optimized for batched per-tensor truncated SVD and coefficient fits; memory layouts for subspace caching.
- Tools/products: Library support in cuSOLVER/oneDNN/ROCm; specialized IP blocks in AI accelerators.
- Assumptions/dependencies: Sufficient demand; upstream framework support.
- Training-free scaling and R&D portfolio planning
- Sectors: enterprise AI strategy, venture R&D
- What: Predict marginal returns for longer RLVR runs to prioritize projects, models, and datasets before committing compute.
- Tools/products: Portfolio simulators using RELEX-based ROI curves.
- Assumptions/dependencies: Forecast validity across domains; decision-making frameworks that account for uncertainty.
- Checkpoint marketplaces for compact “update recipes”
- Sectors: model hubs, licensing ecosystems
- What: Distribute rank-1 directions plus linear coefficients as compact artifacts that end-users can apply to compatible base models to obtain advanced checkpoints.
- Tools/products: “RELEX recipe” format with compatibility tags and provenance.
- Assumptions/dependencies: Legal clarity on derivative weights; cross-version compatibility; safety filters.
- Safety monitoring via trajectory anomalies
- Sectors: AI safety, red teams
- What: Flag deviations from linear, low-rank dynamics (e.g., abrupt coefficient kinks) as potential indicators of reward hacking, mode collapse, or instability.
- Tools/products: Training observability that computes per-layer R² and alerts on anomalies.
- Assumptions/dependencies: Establishing normative thresholds; avoiding false positives.
Cross-cutting assumptions and dependencies
- Method validity: The paper demonstrates rank-1, near-linear dynamics for RLVR on Qwen-family models in math reasoning. Generalizing to other rewards, models (e.g., Llama), or algorithms (e.g., PPO) requires empirical validation.
- Observation-window sensitivity: Optimal window size is model-dependent; deploying RELEX robustly benefits from monitoring subspace drift, R², and singular-value gaps and selecting windows adaptively.
- Data and safety: Verifiable reward design is critical; extrapolated checkpoints must pass safety/alignment and OOD evaluations before release.
- Engineering constraints: Per-tensor truncated SVD must be memory- and time-efficient at scale; checkpoint I/O and tensor layout consistency matter for integration.
- Legal/licensing: Ensure base model licenses permit redistribution or derivative artifacts (including low-rank “recipes”).
Glossary
- Ablation analysis: A systematic study where components of a method are removed or varied to assess their impact. "Our ablation analysis confirms the minimalist sufficiency of RELEX"
- AlphaRL: A method that predicts dominant update directions from early checkpoints using rank-1 decompositions. "AlphaRL computes a rank-1 SVD independently at each early checkpoint"
- Base model: The original pretrained model before any additional fine-tuning or RL steps. "denote θ0 as the weight of a base model"
- Checkpoints: Saved copies of model parameters at different training steps. "producing a trajectory of checkpoints that progressively improve on target tasks"
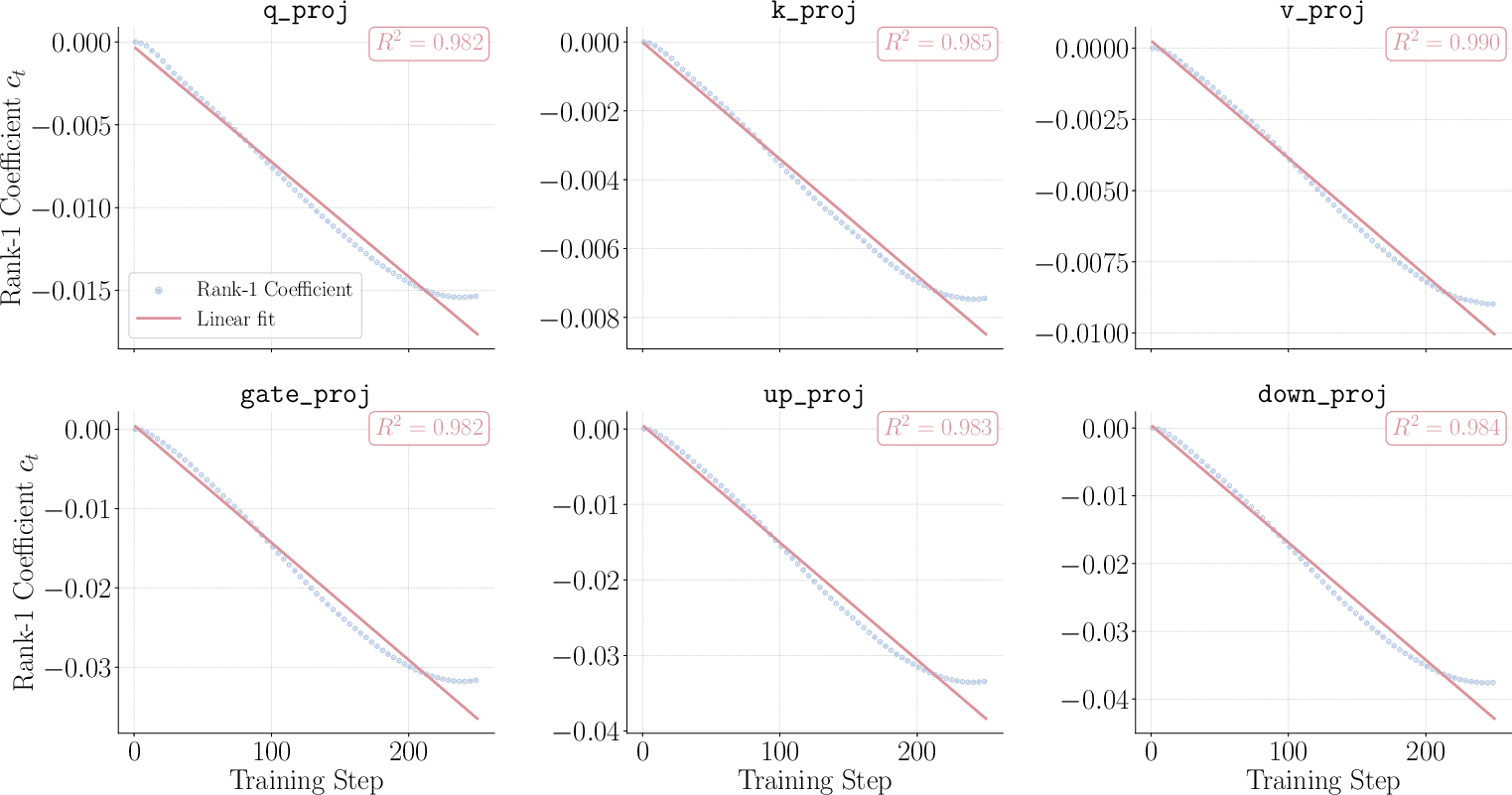
- Coefficient (rank-1 coefficient): The scalar weight of the dominant singular direction describing parameter change over time. "The rank-1 coefficient evolves linearly in training step."
- Coefficient trajectory: The time series of scalar coefficients along a fixed low-rank direction. "fits this rank-1 coefficient trajectory"
- Dominant direction: The primary direction in parameter space that explains most of the meaningful update variance. "a single dominant direction (rank-1) per weight tensor captures most downstream-relevant parameter change"
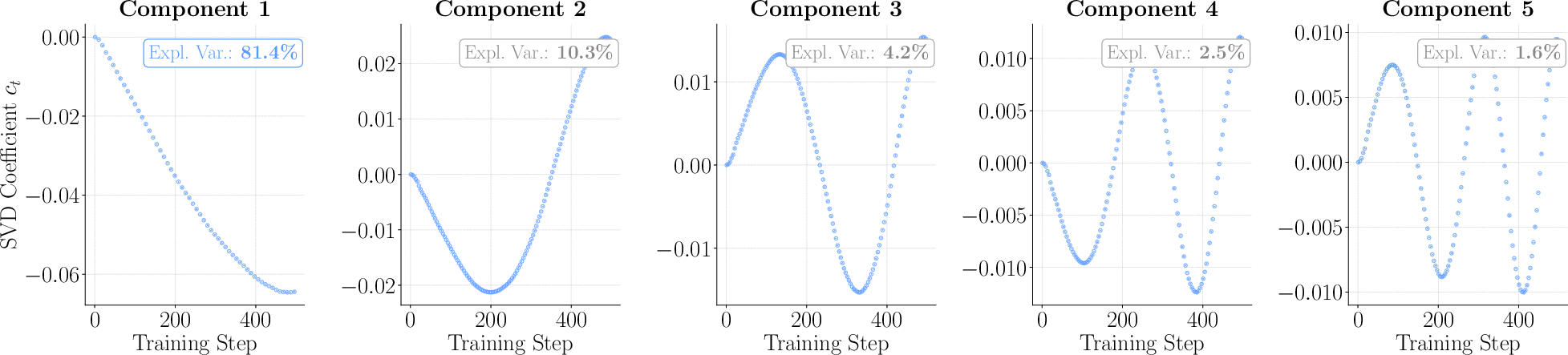
- Explained variance: The proportion of variability captured by selected components in a decomposition. "Annotation boxes show explained variance within the rank-5 subspace."
- Group Relative Policy Optimization (GRPO): An RL algorithm that updates a policy by comparing groups of sampled responses with a clipped objective and KL regularization. "Group Relative Policy Optimization (GRPO;~\citealp{shao2024deepseekmath}) as the RL algorithm."
- Kullback–Leibler (KL) penalty: A regularization term that penalizes divergence between the current policy and a reference policy. "regularized by a KL penalty toward a reference policy."
- Least squares: A fitting method minimizing the sum of squared errors to estimate linear trends. "then fit c(t) = at + b via least squares."
- Linear extrapolation: Predicting future values by extending a fitted line beyond the observed data range. "Linear extrapolation outperforms more complicated functions."
- Linear regression: Modeling a relationship between variables with a linear function used here to predict checkpoint coefficients. "extrapolates future checkpoints via linear regression"
- Logits Extrapolation: An approach that linearly extrapolates model outputs (logits) rather than weights. "propose Weight Extrapolation and Logits Extrapolation to reduce training cost."
- Low-pass filter: A filter that suppresses high-frequency (noisy) components while retaining low-frequency (signal) components. "acts as a low-pass filter that suppresses noisy residual directions"
- Low-rank: Having effective dimensionality much smaller than the ambient parameter space, often captured by a few singular vectors. "RLVR weight trajectories are extremely low-rank"
- LoRA: A low-rank adaptation technique that injects trainable low-rank matrices for efficient fine-tuning. "exploited by LoRA"
- Model soups: A technique that averages weights from multiple fine-tuned models to improve performance. "Task arithmetic and model soups exploit linear structure in weight space for model combination"
- Observation window: The initial segment of training steps used to estimate the low-rank subspace and dynamics. "estimates the rank-1 subspace from a short observation window"
- On-policy reinforcement learning (on-policy RL): RL that updates a policy using data sampled from the current policy. "on-policy RL is implicitly biased toward KL-minimal solutions"
- Ordinary least squares (OLS): The standard linear regression estimator minimizing squared residuals. "RELEX instead fits ordinary least squares over all observed steps"
- Out-of-distribution (OOD): Data or benchmarks drawn from a distribution different from the training domain. "out-of-distribution (OOD) benchmarks"
- Output-logit space: The space of unnormalized model outputs prior to softmax, used as an alternative extrapolation domain. "output-logit space at inference time"
- Parameter deltas: Differences between model parameters at two checkpoints, often relative to the base model. "parameter deltas Δ_t = θ_t − θ_0"
- Policy (π_θ): The parameterized decision rule in RL that maps states (or prompts) to action distributions. "train an LLM policy π_θ to maximize rewards"
- Principal components: Orthogonal directions capturing maximal variance used to analyze structure in updates. "analyze RLVR through the lens of principal components"
- Projection (onto a subspace): Mapping vectors onto a lower-dimensional subspace, often to denoise or summarize changes. "by projecting updates onto the rank-1 subspace"
- Rank-1 approximation: A representation of a matrix or update using a single singular vector and scalar coefficient. "captured by a rank-1 approximation of the parameter deltas"
- Rank-1 subspace: The one-dimensional subspace spanned by the top singular vector for a parameter’s trajectory. "projecting updates onto the rank-1 subspace"
- R2 (coefficient of determination): A goodness-of-fit metric indicating how well a model explains variance. "with ( means perfect fit) for most tensors"
- Reference policy: A fixed policy used to regularize RL updates via KL divergence. "regularized by a KL penalty toward a reference policy."
- Reinforcement learning with verifiable rewards (RLVR): RL training where rewards are programmatically validated (e.g., correctness checks). "Reinforcement learning with verifiable rewards (RLVR) has become a dominant paradigm"
- Right singular vector: The vector in SVD defining a principal direction in parameter space for updates. "We extract the top right singular vector \mathbf{v}_1 via truncated SVD."
- Scaling laws: Empirical relationships that model performance or loss as a function of compute/data/model size. "Scaling laws predict aggregate loss from compute"
- Singular value decomposition (SVD): A matrix factorization that decomposes trajectories into orthogonal directions and coefficients. "applying singular value decomposition (SVD)"
- Singular-value gaps: Differences between successive singular values indicating separation of signal and noise. "monitor subspace drift or singular-value gaps online"
- Spectral denoiser: A method that removes noise by retaining only leading spectral components. "rank-1 projection acts as a spectral denoiser"
- Spectral regularizer: A constraint or effect that biases learning toward leading spectral components to improve generalization. "acts as a beneficial spectral regularizer"
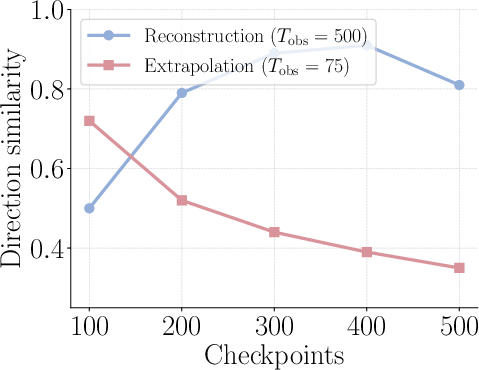
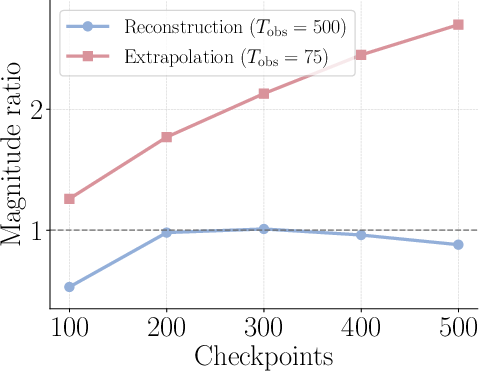
- Stationarity (rank-1 stationarity): The stability of the dominant low-rank direction over training time. "rank-1 stationarity is model-dependent"
- Subspace drift: Changes over time in the low-dimensional subspace capturing the updates. "monitor subspace drift or singular-value gaps online"
- Task arithmetic: Linear combinations of model weights to compose or edit behaviors. "Task arithmetic and model soups exploit linear structure in weight space for model combination"
- Token-level clipped objective: An RL objective that applies clipping at the token level to stabilize updates. "updates π_θ via a token-level clipped objective"
- Trajectory matrix: A stacked matrix of flattened parameter deltas across steps for SVD analysis. "stack the deltas into a trajectory matrix \mathbf{M}"
- Truncated SVD: Computing only the top singular vectors/values to obtain a low-rank approximation. "via truncated SVD"
- Two-endpoint baselines: Methods that extrapolate using only two checkpoints (e.g., base and one intermediate). "the two-endpoint baselines substantially underperform our method"
- Weight Extrapolation: Extrapolating future model parameters by linearly extending between checkpoints in weight space. "propose Weight Extrapolation and Logits Extrapolation to reduce training cost."
- Weight space: The high-dimensional space of model parameters. "raw weight space"
- Weight update trajectories: Sequences of parameter changes across RL training steps. "we study weight update trajectories during RLVR training"
Collections
Sign up for free to add this paper to one or more collections.

