Slicing and Dicing: Configuring Optimal Mixtures of Experts
Abstract: Mixture-of-Experts (MoE) architectures have become standard in LLMs, yet many of their core design choices - expert count, granularity, shared experts, load balancing, token dropping - have only been studied one or two at a time over narrow configuration ranges. It remains an open question whether these choices can be optimized independently, without considering interactions. We present the first systematic study of over 2,000 pretraining runs spanning models up to 6.6B total parameters, in which we exhaustively vary total experts, expert dimension, heterogeneous expert sizing within a single layer, shared expert size and load-balancing mechanisms. We find that at every active-parameter scale that we study, performance consistently improves with total MoE parameters even at extreme active expert parameter ratios like 128.Further, the optimal expert size is nearly invariant to total parameter count and depends only on active parameter count. Third, we see that other choices like shared experts, heterogeneous experts and load-balancing settings have small effects relative to expert count and granularity, although dropless routing yields a consistent gain. Overall, our results suggest a simpler recipe: focus on expert count and granularity, other choices have minimal effect on final quality.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies a special way to build big LLMs called “Mixture of Experts” (MoE). Instead of having one giant part that processes every word, MoE uses many small “experts.” For each word, a “router” picks only a few experts to do the work. This makes training more efficient while still letting the model be very powerful.
The authors ran over 2,000 training experiments to figure out which MoE design choices really matter for getting good performance and which ones don’t.
What questions did the researchers ask?
In simple terms, they wanted to know:
- How many experts should you have, and how big should each expert be?
- Is it better to mix different sizes of experts or keep them all the same?
- Should you include a “generalist” expert that always helps, no matter what?
- How much do routing tricks (like balancing work across experts or avoiding dropped tokens) affect performance?
- Can you tune these choices independently, or do they interact in complicated ways?
How did they study it?
They built many versions of MoE models and trained them on the same kind of data (a mix of web text, code, math, and encyclopedias). To make fair comparisons:
- They kept the “active compute” the same across models. Think of it like giving every model the same amount of running time per word, even though some have more experts waiting on the sidelines.
- They changed one thing at a time: total number of experts, the size of each expert (called “granularity”), whether experts had different sizes, whether there was a generalist expert that’s always used, and how the router balances work.
- They measured performance with a standard score called “cross-entropy loss.” Lower is better.
A helpful analogy: imagine a school with many teachers (experts). For each student’s question (token), a guidance counselor (router) picks the best 1–2 teachers to answer. The school size (total experts) can be huge, but only a few teachers are active per question, keeping the time and effort per question the same.
What did they find?
Here are the main takeaways:
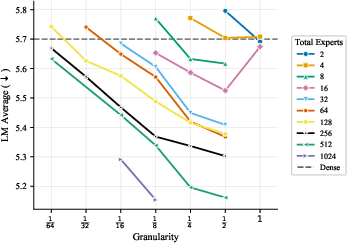
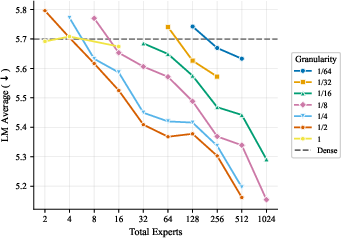
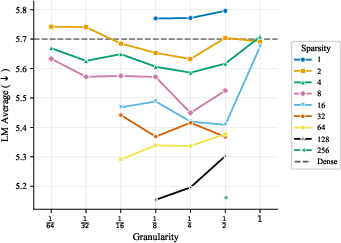
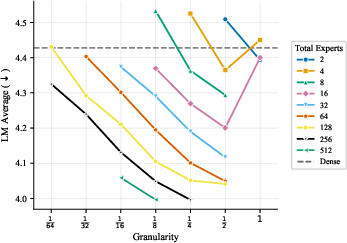
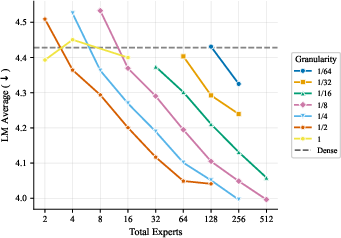
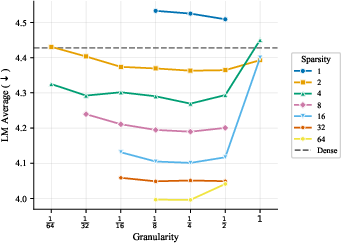
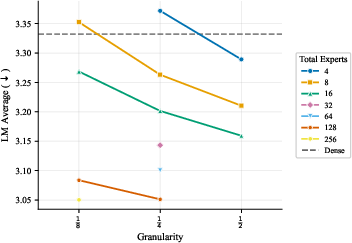
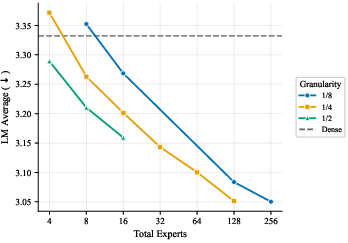
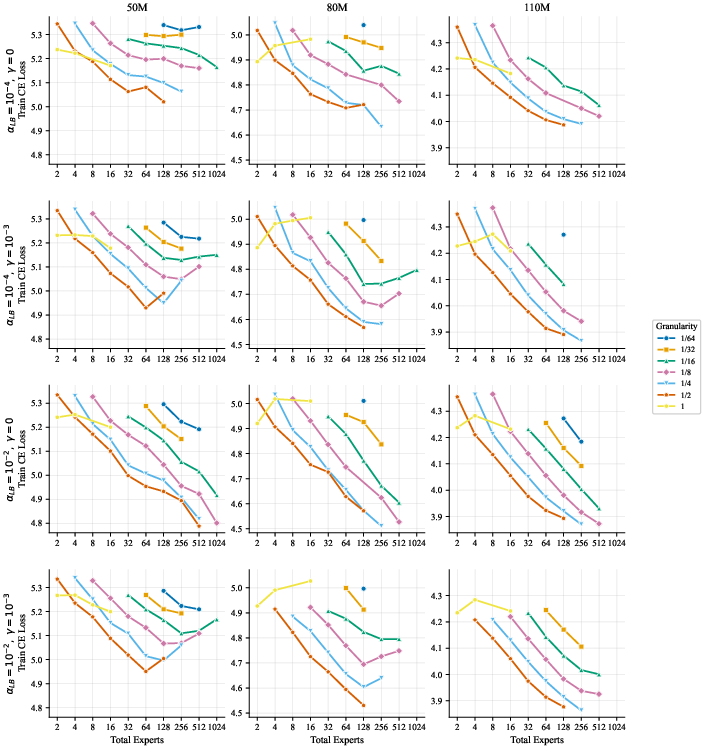
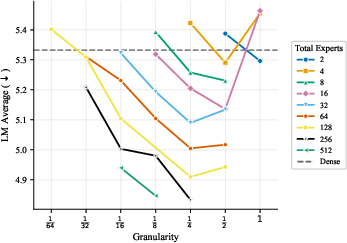
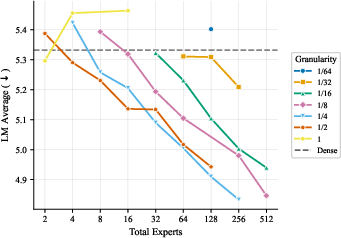
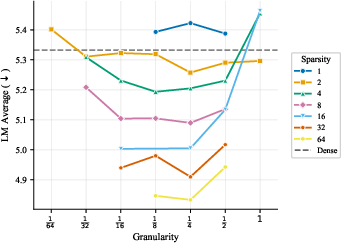
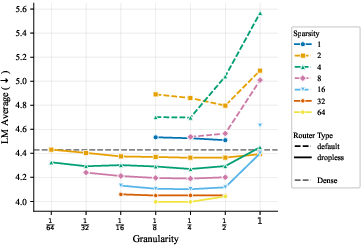
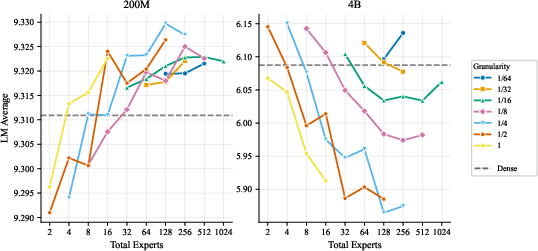
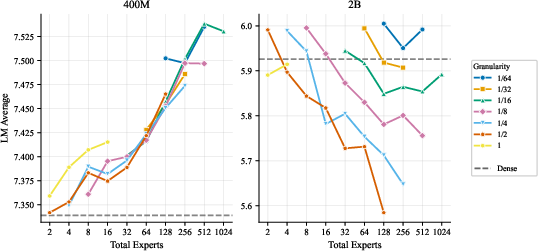
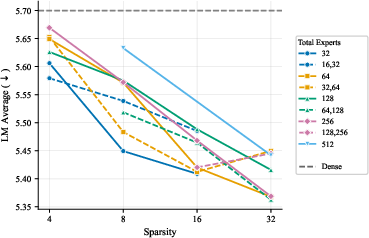
- More total experts helps, even if most are inactive at any moment. The models got better as they added more experts and parameters overall, even when the ratio of total to active parameters was extremely large. In plain terms: a big bench of specialists to choose from is useful.
- The best expert size depends mostly on how many parameters are active when a token is processed, not on the total size of the model. So pick expert sizes based on your per-token compute budget, then scale total experts up as memory allows.
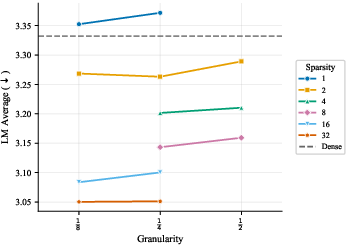
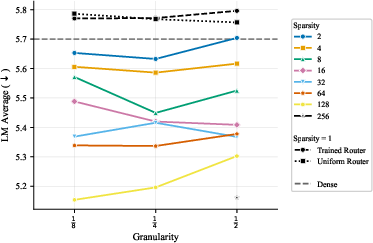
- Focus on two things: expert count and expert size (granularity). These two choices drive most of the performance. Other choices matter much less.
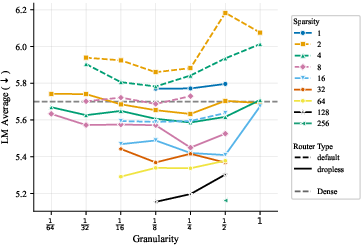
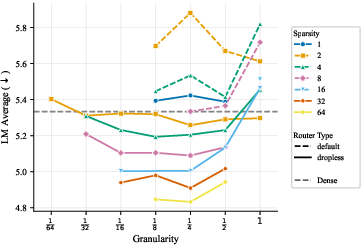
- “Dropless routing” gives a consistent boost. Sometimes an expert’s “classroom” gets too full and extra tokens are dropped or sent elsewhere. Dropless routing makes sure tokens aren’t dropped, and this usually improves results.
- Using a single active expert per token (top‑1 routing) underperforms. Activating two or more small experts per token tends to be better than relying on a single large expert.
- Splitting the feed-forward network (FFN) into smaller pieces without sparsity hurts. If you keep all parts active all the time (no routing, no sparsity), performance gets worse. The benefit comes from smart, sparse activation, not just slicing the FFN.
- “Generalist” experts that are always active don’t help and often hurt. Having a shared expert that participates for every token sounds nice, but experiments showed it usually makes things worse.
- Mixing different expert sizes (heterogeneous experts) doesn’t beat a well‑tuned set of same‑size experts. Flexibility alone didn’t give improvements; the homogeneous setup performed as well or better.
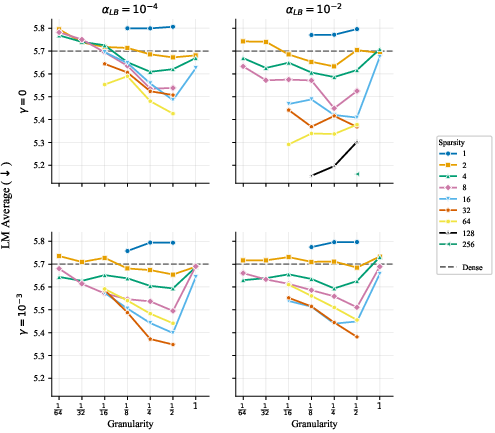
- Load balancing settings matter only a little—if you stay within reasonable ranges. You should avoid extreme settings that overcorrect routing, but otherwise, you don’t need to spend lots of time tuning these hyperparameters.
- MoE beats dense models once you have enough compute or data. At very small scales, MoE didn’t outperform regular dense models. But with more data or bigger active model sizes, MoE consistently did better.
Why does it matter?
This study simplifies how to build strong MoE LLMs:
- Put your effort into choosing the number of experts and their size. Set expert size based on your per-token compute, then add more total experts if you have memory to spare.
- Turn on dropless routing.
- Don’t rely on always-on generalist experts or complex mixes of different expert sizes.
- Keep load balancing reasonable, but don’t overthink it.
For teams training large models, this is practical advice that can save time and resources. It suggests a clean recipe: scale total experts and pick a stable expert size, and you’ll likely get most of the benefits of MoE without diving into overly complicated configurations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future work could address:
- Scaling beyond studied regimes: Do the reported trends (e.g., “increase total experts; keep granularity coarse”) hold at substantially larger active parameter counts (≥1B) and total parameters (≥10s–100s of billions or trillion-scale), or do returns saturate or reverse at very high activation sparsity and total expert counts (e.g., , )?
- Compute–data optimality: What are the compute-optimal trade-offs among expert count, granularity, and training tokens across data scales? How do optimal configurations shift under different data budgets and mixtures (given small models required much more data to realize MoE gains)?
- Generalization across datasets: Do the conclusions persist across markedly different corpora (e.g., multilingual, speech-text, noisy web, domain-specialized biomedical/legal) and data qualities, not just the OLMoE mixture?
- Downstream performance and robustness: How do configuration choices translate to downstream tasks (reasoning, coding, instruction-following), in-context learning, and robustness? The paper emphasizes validation cross-entropy and notes variance on downstream tasks without a systematic analysis.
- Inference efficiency and systems impact: What are the real-world throughput, latency, memory bandwidth, and communication costs of increasing (with constant active parameters) across hardware backends (GPU, TPU) and expert-sharding strategies? Does dropless routing maintain system efficiency at scale?
- Router algorithm breadth: How do alternative routing strategies (expert-choice, optimal transport/Sinkhorn, temperature/noise schedules, top- beyond the coupling, per-sequence/document routing) affect quality, stability, and balance under FLOP-matched comparisons?
- Decoupling active expert count from granularity: What is the optimal (active experts) at fixed active parameter count when and per-expert size are varied independently (rather than enforcing )? Does an optimal emerge beyond 1–2 across scales?
- Capacity management: How do capacity factor choices and alternative overflow handling interact with dropless routing, particularly at very high , and what are the accuracy–efficiency trade-offs?
- Load-balancing mechanisms and schedules: Can adaptive or learned schedules for auxiliary loss weight and loss-free bias (rather than fixed and ) improve stability and performance, especially for large where fixed appears too coarse?
- Stability and router regularization: What is the systematic effect of Z-loss, entropy penalties, temperature annealing, or noise injection on router stability across scales, beyond preliminary or appendix-only ablations?
- Expert heterogeneity search: Does more expressive heterogeneity (more than two pools, unequal compute splits, per-layer heterogeneity, learned/dynamic expert sizing, or continuous parameterization) provide benefits that the restricted two-pool, equal-split design may have missed?
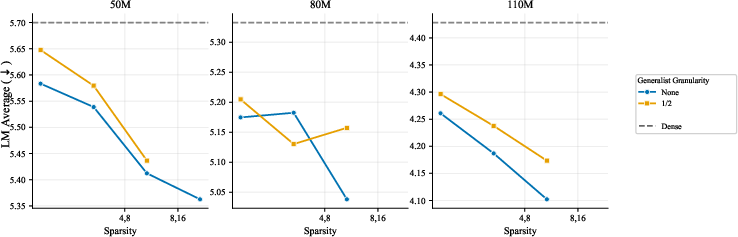
- Generalists under broader conditions: Are shared experts beneficial under other regimes (e.g., larger scales, multi-task mixtures, instruction tuning, different placement or warm-start/distillation of generalists, or multiple smaller generalists)? Current negative results may be configuration- or scale-specific.
- Layerwise MoE placement: How do optimal expert count and granularity vary by layer depth, and does selective MoE placement (early vs middle vs late layers) outperform uniform placement?
- Attention vs FFN sparsity: What are the effects of applying MoE to attention (or hybrid MoE across FFN and attention) on quality/efficiency relative to FFN-only MoE?
- Expert specialization analysis: How do routing patterns and expert specialization evolve (e.g., by domain/token types), how stable are they across seeds, and do they correlate with performance? Can this inform adaptive reallocation or pruning/merging of experts?
- Training duration and convergence: Do optimal configurations shift with much longer training (near-convergence) vs the reported budgets? Are observed trends transient early-training effects?
- Optimizer and regularization sensitivity: How do optimizer choices, learning-rate schedules, weight decay, dropout, and normalization strategies specifically affect routers and experts across configurations?
- Fine-grained experts at larger actives: The paper recommends relatively coarse experts (e.g., ) at studied scales. Is there a reproducible functional relationship between active parameter count and optimal that can be formalized as a scaling law?
- Tokenization and sequence length: How do tokenization schemes and sequence length/batch-shape (which affect per-step load variance) impact load imbalance, dropless benefits, and optimal capacity factors?
- Fractional/continuous granularity: Does allowing non-dyadic granularity (beyond ) or continuous expert-width allocation yield additional gains under the same compute/memory budgets?
- Multi-expert communication: Do mechanisms for cross-expert communication/aggregation (beyond weighted summation per token) improve learning and stability, especially at high ?
- Safety and alignment considerations: How do MoE configuration choices impact harmful content generation, calibration, or controllability post-alignment, and do shared experts or heterogeneity affect safety tuning?
- Reproducibility across infrastructures: Are results consistent across different training stacks (DeepSpeed, Megablocks variants), cluster topologies, and sharding strategies, given their potential to influence token dropping and utilization?
These gaps outline actionable directions to test the robustness, scalability, and practical utility of the proposed “simpler recipe” for configuring MoE models.
Practical Applications
Overview
This paper provides a large-scale, systematic exploration of Mixture-of-Experts (MoE) design choices across >2,000 pretraining runs (up to 6.6B total params). The central, actionable findings are:
- Quality increases monotonically with total MoE parameters (inactive expert capacity), even at very high activation sparsity.
- The optimal expert size (granularity) is largely determined by the active parameter scale, not the total parameter count.
- Other knobs (shared/generalist experts, heterogeneous expert sizes, most load-balancing settings) have small effects; dropless routing yields a consistent, small gain.
- Top-1 (single-expert) routing underperforms; MoE benefits do not materialize at very small active scales unless the data/compute budget is increased.
Below are concrete applications, grouped by immediacy, including sectors, potential tools/workflows, and feasibility assumptions.
Immediate Applications
These applications can be deployed now using existing frameworks (e.g., DeepSpeed-MoE, Megatron-Core, Fairseq-MoE, MegaBlocks) and standard GPU clusters.
- Production-ready MoE configuration recipe and HPO reduction
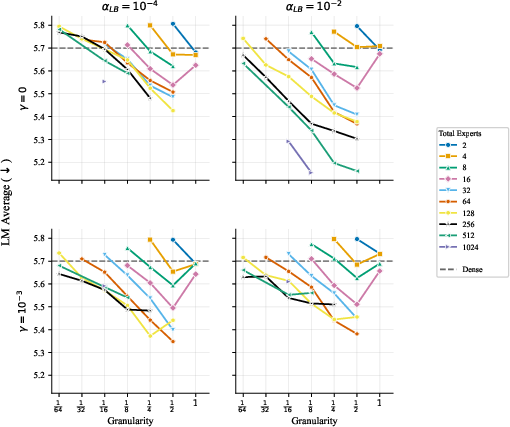
- What to do: Narrow the search to only two primary knobs—total expert count n and expert granularity g—and set k (active experts) via k = 1/g. Use top-2-or-more routing (avoid top-1). Enable dropless routing. Avoid shared “generalist” experts and heterogeneous expert sizing by default. Keep load-balancing weights within reasonable ranges (e.g., αLB ~ 1e-2 to 1e-4) and avoid overly large loss-free bias at high n.
- Practical defaults by active parameter scale (illustrative from the paper’s trends):
- ~50M active params: g in [1/4, 1/2]
- ~110M active params: g in [1/8, 1/4]
- ~300M active params: g ≤ 1/8
- Increase n as memory allows; expect quality to rise with total parameters for fixed FLOPs.
- Sectors: Software/AI platforms, cloud providers, model vendors, enterprise ML teams.
- Tools/workflows: “MoE Configurator” (script or UI) that takes active-parameter target, VRAM per device, number of devices, kernel availability (dropless), and outputs (n, g, k) with safe LB settings and router defaults. Integrate as a template in your training pipeline.
- Assumptions/dependencies: Block-sparse/dropless kernels available; FLOP-matched comparisons; results validated up to ~300M active and 6.6B total parameters on the reported data mixture.
- Capacity gains at fixed training FLOPs (latency/cost budgets)
- What to do: When compute-per-token is fixed (e.g., latency or energy constraints), increase total expert count n (and thus total parameters) to improve quality without raising per-token FLOPs.
- Sectors: Customer support/chatbots, code assistants, search and ads, content moderation.
- Tools/products: SKU variants of your LLM (same latency target, varying total n for higher quality tiers); “memory-for-quality” pricing tiers in model serving.
- Assumptions/dependencies: Sufficient GPU memory or model-parallelism bandwidth to host more (inactive) experts.
- Adopt dropless routing to reduce token loss and improve stability/quality
- What to do: Replace capacity-factor token drops with dropless routing (e.g., MegaBlocks). Gains are small but consistent across scales; parity at extremely high n.
- Sectors: Any production MoE deployment; regulated domains (where dropped tokens could be problematic).
- Tools/workflows: Kernel swap-in; router instrumentation for drop-rate to verify elimination; A/B tests.
- Assumptions/dependencies: Availability of dropless kernels; engineering integration cost.
- GPU procurement and capacity planning with activation sparsity s
- What to do: Use s = n * g as a simple planning metric. Given a latency/FLOP budget (fixed k = 1/g), scale quality by adding total experts n until memory is saturated.
- Sectors: Cloud/HPC, finance/quant firms, AI infrastructure teams.
- Tools/workflows: Procurement calculators that translate budgeted FLOPs and VRAM into (n, g, k) with expected quality improvements; scheduler policies that prioritize VRAM for higher-n models when compute is fixed.
- Assumptions/dependencies: Memory constraints dominate; communication overhead manageable with your parallelism strategy.
- Simplify architectures by removing always-on generalists and heterogeneous expert pools
- What to do: Default to homogeneous, routed-only experts. Paper shows generalists and heterogeneity do not beat well-configured homogeneous MoE at matched budgets.
- Sectors: All model builders (reduces engineering complexity, failure modes).
- Tools/workflows: De-scope feature flags for shared experts/heterogeneity; focus QA/testing on the simpler recipe.
- Assumptions/dependencies: Your tasks are similar to the study’s (LM pretraining, diverse text mixture). Some niche multi-task regimes may still benefit from shared experts—validate locally.
- Safer router defaults
- What to do: Avoid top-1 routing; default to top-2-or-more. Keep LB weight in a modest range; avoid large loss-free bias at high n.
- Sectors: Any MoE user; especially new adopters who lack router expertise.
- Tools/workflows: Router presets; monitoring dashboards for load imbalance, expert utilization, and router loss.
- Assumptions/dependencies: Same router class and token-choice scheme as common MoE stacks.
- When NOT to use MoE at very small scales
- What to do: If active parameters are ~10–20M and data/compute budget is small, a dense model may outperform MoE. If you must use MoE, increase the data/compute budget to realize benefits.
- Sectors: Academia/education, startups with very limited budgets.
- Tools/workflows: Budget checklists; decision tree in training docs (“dense vs MoE”).
- Assumptions/dependencies: Your scale is similar to those tested; task/data regimes comparable.
- Reporting and evaluation standards that improve reproducibility and governance
- What to do: Report active parameters, total parameters, activation sparsity s, router drop rate (if any), load-imbalance metrics, and whether dropless routing was used. Compare models at matched FLOPs.
- Sectors: Academia, open-source communities, policy/AI governance.
- Tools/workflows: Model cards and eval templates; CI checks to enforce reporting; logs for router stats.
- Assumptions/dependencies: Organizational willingness to standardize metrics; availability of the paper’s code to copy instrumentation patterns.
Long-Term Applications
These require additional research, systems development, or ecosystem maturation, but are grounded in the paper’s findings.
- Memory-first accelerator and system co-design for MoE
- Idea: Hardware and runtime stacks that prioritize large parameter storage and low-overhead activation of a small subset per token. Expect substantial gains since quality rises with total parameters at fixed FLOPs.
- Sectors: Semiconductors, cloud hardware, systems software.
- Potential products: MoE-optimized memory fabrics, near-memory compute for expert FFNs, router-aware interconnect scheduling.
- Dependencies/assumptions: Vendor kernel support for dropless sparse ops; network/memory bandwidth optimized for many small FFNs.
- Elastic MoE: runtime adaptation of n, k, and g under resource and latency constraints
- Idea: Dynamically adjust the number of experts activated and/or total experts loaded based on VRAM headroom, latency SLOs, or user tier to maximize quality at runtime.
- Sectors: Cloud serving, consumer apps with variable device capabilities.
- Potential products: “Elastic Experts” serving tier; autoscalers that add/remove inactive experts on the fly.
- Dependencies/assumptions: Fast expert swapping/streaming; router stability under changing expert pools; robust caching/quantization.
- AutoMoE controllers that learn to pick (n, g) under budget
- Idea: Automated controllers that, given a target active-param budget, VRAM, and training time, select granularity and total experts using priors from this paper’s scaling trends.
- Sectors: AutoML platforms, enterprise MLOps.
- Potential products: Planner that outputs a training curriculum and a minimal HPO sweep for n only; budget-to-quality estimators.
- Dependencies/assumptions: Transferability of the paper’s trends to new corpora and larger scales.
- Revisiting heterogeneity and shared experts with new objectives
- Idea: Although the paper finds no gains in general, specialized regimes (multi-task safety, tool-use, speech+text, grounded RL) may need different inductive biases and new routing/loss designs to unlock benefits.
- Sectors: Healthcare (safety-critical triage), finance (compliance), robotics (multi-modal control).
- Potential products: Domain-aware router losses, expert-regularization for cross-task transfer, safety-specialist experts with calibrated routing.
- Dependencies/assumptions: New training objectives; careful auxiliary-loss tuning; robust evaluation to avoid overfitting artifacts.
- Edge/on-device MoE via expert paging, quantization, and distillation
- Idea: Store many experts off-device and page/stream/quantize them; keep active compute low per token. Alternatively, distill many-expert MoEs into edge-suitable students.
- Sectors: Mobile, IoT, robotics.
- Potential products: Expert caches, cold-start expert prefetchers, MoE-to-dense student distillation pipelines.
- Dependencies/assumptions: Efficient storage, streaming, and quantization; predictable routing to prefetch correctly.
- MoE-aware safety, robustness, and fairness auditing
- Idea: Build auditing suites that measure expert-level specialization, load balance by demographic inputs, and the impact of dropless routing on failure modes.
- Sectors: Policy/governance, regulated industries.
- Potential products: Router fairness dashboards; expert-behavior probes; safety regression tests by expert assignment.
- Dependencies/assumptions: Access to router logits/assignments; privacy-preserving logging.
- Policy standards for energy/compute reporting that reflect MoE realities
- Idea: Require reporting both active and total parameters, activation sparsity s, dropless/dropped-token stats, and FLOP-matched evaluations in model cards and regulatory filings.
- Sectors: Government, standards bodies, publishers.
- Potential products: Certification checklists; standardized compute/quality disclosures; benchmarks that fix per-token FLOPs.
- Dependencies/assumptions: Community consensus; tooling to verify claims; alignment with broader AI transparency efforts.
Notes on Assumptions and Dependencies Across Applications
- External validity: Results are established up to ~300M active and ~6.6B total parameters, on a particular data mixture and token-choice routing. Extrapolation to trillion-parameter total scales or very different data distributions should be validated.
- Systems preconditions: Dropless routing depends on block-sparse kernels (e.g., MegaBlocks) and compatible frameworks; parallelism and communication overheads can limit scalability as n grows.
- Memory as a first-class constraint: Gains rely on hosting more total experts. If VRAM or memory bandwidth is tight (edge/embedded), benefits may be constrained without advanced offloading or quantization.
- Hyperparameter ranges: Load-balancing settings are robust within “reasonable” ranges but can hurt at high n if loss-free bias is too large; routers and kernels should be tested per deployment.
- Small-scale caveat: At tiny active scales and limited data/compute budgets, MoE may underperform dense—either increase the budget or prefer dense models.
Glossary
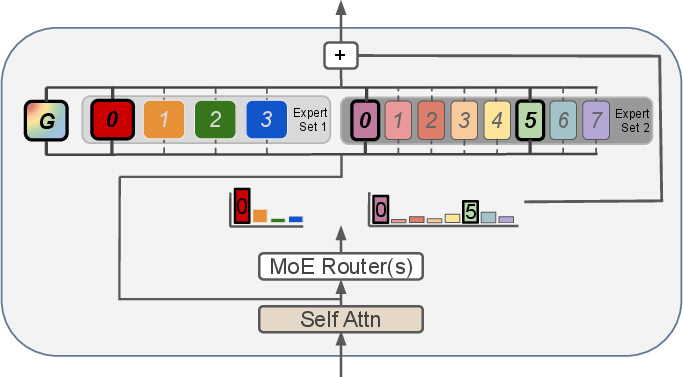
- Active expert count: The number of experts activated per token in an MoE layer; affects compute and memory cost independently of expert size. "Active expert count is independent of expert size."
- Activation sparsity: A measure of how many total FFN parameters exist relative to the active FFN parameters, defined as s = n * g. "We hold MoE activation sparsity fixed for "
- Affinity: A score measuring how well a token matches an expert, used by routers to choose experts. "compute an affinity between each (hidden state, expert) pair."
- Auxiliary loss: An additional loss term added to the primary task loss to encourage behaviors like load balancing. "Auxiliary losses are a direct and explicit tool to induce load balancing."
- Block-sparsity: A sparsity pattern that enables efficient computation by operating on blocks; used to avoid dropping tokens. "Dropless routing \citep{megablocks} uses block-sparsity to ensure that no tokens are dropped."
- Capacity factor: A multiplicative buffer on each expert’s token capacity to mitigate temporary load imbalance. "A common capacity factor is 2."
- Dropless routing: A routing strategy ensuring no tokens are discarded even under load imbalance, typically via block-sparse computation. "Dropless routing \citep{megablocks} uses block-sparsity to ensure that no tokens are dropped."
- Expansion factor: An alternative (but overloaded) name for activation sparsity; sometimes also used for FFN width expansion. "This is sometimes referred to as expansion factor, but this term is overloaded and also used to refer to FFN dimension expansion."
- Feed-forward network (FFN): The position-wise MLP sublayer in a Transformer that is replaced by experts in MoE layers. "replace the feed-forward network (FFN) in some or all transformer layers."
- Fine-grained experts: Experts with reduced intermediate FFN dimension to increase the number of experts at fixed compute. "more recent work has explored fine-grained experts with decreased intermediate FFN dimension"
- FLOP-matching: Controlling configurations so they use the same floating-point operations per step, enabling fair comparisons. "To FLOP-match all configurations on a per-timestep basis, we match active FFN parameters at each model scale."
- FLOPs-per-token: The computational cost measured in floating-point operations required to process each token. "Increased active expert count incurs a higher FLOPs-per-token compute cost and memory usage"
- Generalist (shared expert): An always-active expert whose output is combined with routed experts for all inputs. "Also referred to as shared experts, generalists are experts which are always activated, for all inputs."
- Heterogeneous experts: An MoE configuration where experts differ in size or granularity within the same layer. "heterogeneous MoE layers consisting of experts with different granularity"
- Load balancing auxiliary loss: A specific auxiliary loss that penalizes uneven routing so tokens are spread across experts. "A simple load balancing auxiliary loss \citep{shazeer2017outrageouslylargeneuralnetworks} penalizes overreliance on expert in each batch"
- Loss-free load balancing: A mechanism that balances loads by adjusting per-expert biases instead of adding a loss term. "A loss-free mechanism avoids the challenge of balancing loss terms, though it does introduce other inductive biases to the LM."
- Mixture of Experts (MoE): An architecture with many expert submodules where a router activates a subset per input to decouple capacity from compute. "Mixture of Experts (MoE) models decouple computational overhead from model capacity by adding experts which are conditionally activated by a learned router."
- Router: The component that selects which experts to activate for each token based on affinity scores. "At each timestep, the router for a particular MoE layer selects a subset of experts to activate."
- Router Z-loss: An auxiliary loss designed to stabilize router training, particularly at larger scales. "introduce an additional auxiliary loss, the Z-loss, designed to address instability in router training, especially at larger model scales:"
- Token choice: A routing algorithm that selects experts independently for each token based on highest affinities. "One of the most common is token choice"
- Token dropping: Discarding tokens that exceed an expert’s capacity during routing, passing them to the next layer without expert processing. "These remaining overflow tokens may be routed to the next best available expert, or they may be dropped altogether, passed directly to the next layer."
- Top-1 routing: A routing regime where exactly one expert is activated per token, often underperforming compared to multi-expert activation. "Top-1 routing underperforms in FLOP-matched settings"
Collections
Sign up for free to add this paper to one or more collections.