- The paper shows that hallucinations in MLLMs result from high-frequency, fragmented attention patterns rather than overall attention magnitude.
- The authors introduce LaSCD, a training-free method that leverages Laplacian spectral analysis to suppress hallucinated content during decoding.
- Empirical evaluations on benchmarks reveal that LaSCD significantly reduces hallucination while maintaining robust performance on multimodal tasks.
Visual Attention Structure as a Hallucination Indicator in Multimodal LLMs
Multimodal LLMs (MLLMs) serve as critical components for visual reasoning and grounded language tasks, yet they display persistent vulnerabilities to visual hallucination—outputting text inconsistent with image content, such as mentioning nonexistent objects or erroneous descriptions. The standard intuition presumes hallucination arises from insufficient visual-token attention during decoding, motivating several mitigation strategies based strictly on increasing or reallocating attention mass. However, empirical evidence presented in this study demonstrates that visual-attention magnitude is a suboptimal proxy: hallucinations can occur at layers where the model still robustly attends to visual tokens.
Structural Attention Analysis
The central empirical finding is that hallucination in MLLMs is more tightly linked to the spatial high-frequency structure of visual attention rather than its aggregate mass. By computing the layer-wise Laplacian energy of the visual-attention slice at each decoding step, the authors discovered that hallucinations exhibit distinct spectral signatures:
- The layer with maximal Laplacian energy (E(ℓ)) marks the initial commitment to hallucinated content.
- The layer with minimal Laplacian energy transiently favors the ground truth, often briefly recovering the correct answer before final logits overwrite it.
This contradicts the magnitude-based hypothesis, fundamentally challenging existing approaches that rely solely on attention mass as a diagnostic or intervention criterion. The results are demonstrated in concrete decoding trajectories:
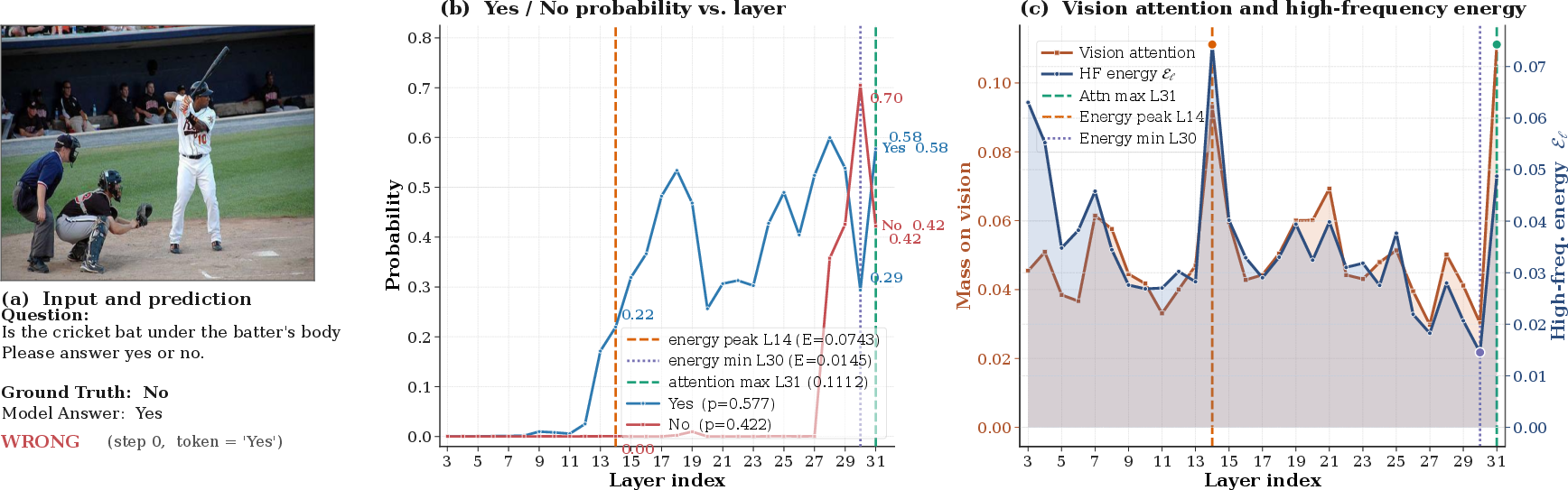
Figure 1: Layer-wise analysis during confident hallucination; the ground-truth answer briefly resurfaces at the minimum-energy layer, while hallucination is locked in at the peak-energy layer.
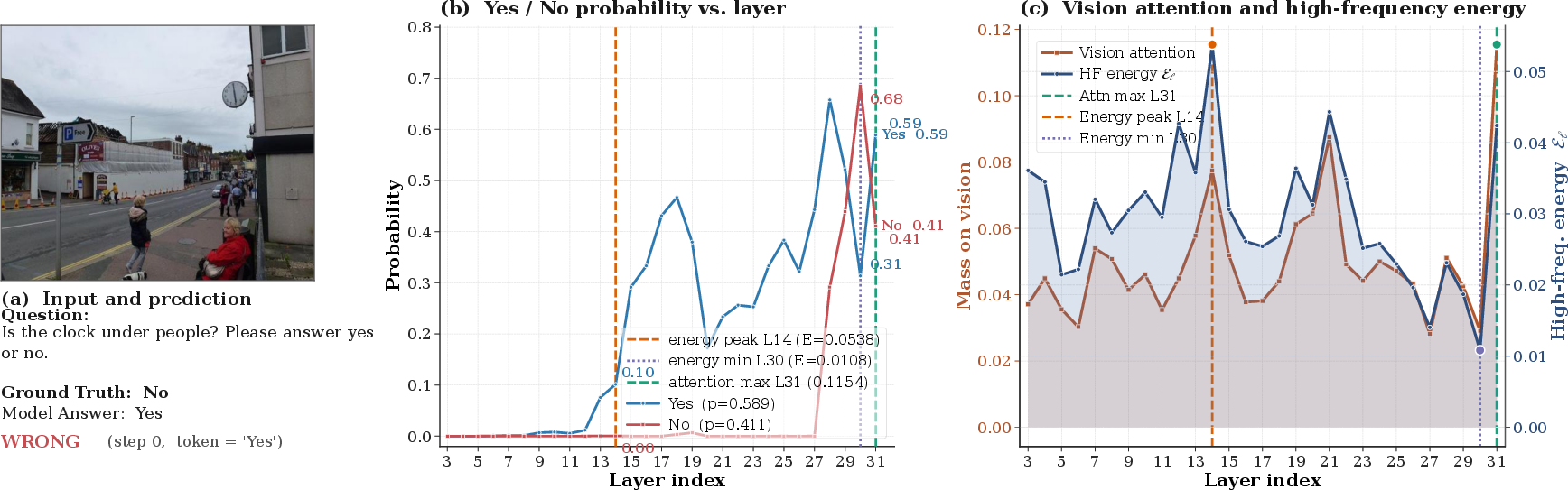
Figure 2: Case study showcasing the dynamics of hallucination emergence and transient recovery across decoding layers.
Laplacian-Spectral Contrastive Decoding (LaSCD) Methodology
Motivated by this structural insight, the paper introduces LaSCD (Laplacian-Spectral Contrastive Decoding), a training-free inference method for MLLMs. At each autoregressive generation step:
- Layer Scoring: The Laplacian energy is computed for candidate transformer layers over the visual-token attention slice. Both the peak (ℓpeak) and minimum (ℓgt) energy layers are selected.
- Contrastive Logit Remapping: The final-layer logits are contrasted against those at ℓpeak, suppressing tokens strongly favored at the hallucination-prone layer.
- Optional Correction: Low-energy logits from ℓgt are optionally weighted to promote transient recovery of the ground-truth token.
All operations are executed in closed form, leveraging only a single autoregressive forward pass. This approach bypasses the substantial compute overhead incurred by two-view contrastive decoding pipelines.
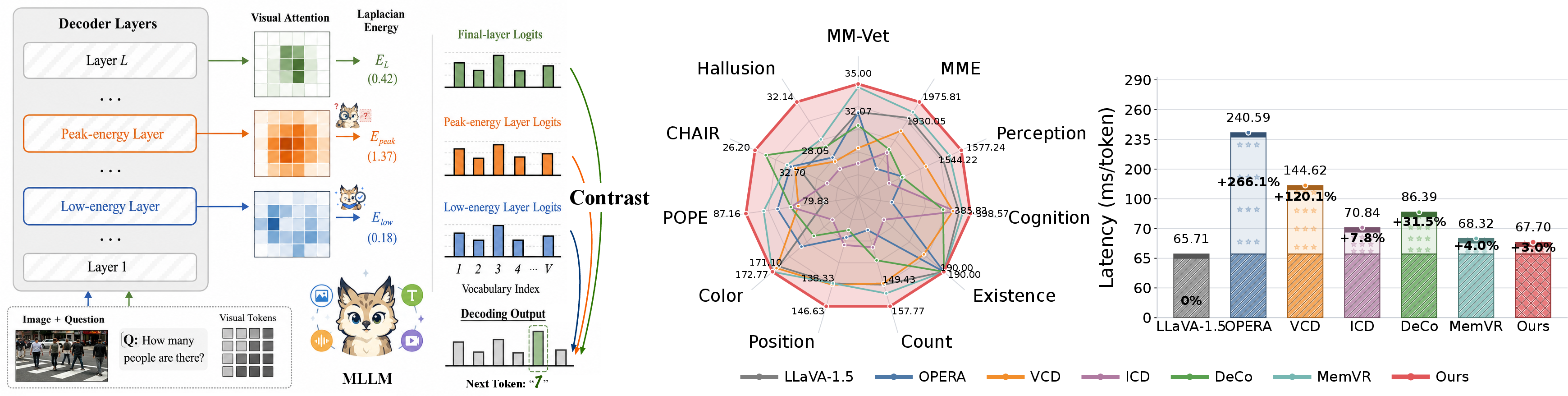
Figure 3: Overview of the LaSCD decoding strategy and comparison of performance/latency against state-of-the-art methods.
Experimental Evaluation and Empirical Results
LaSCD was evaluated across CHAIR, POPE, HallusionBench, and VideoHallucer benchmarks, as well as general multimodal datasets such as MME and MM-Vet. Key empirical findings:
- CHAIR: LaSCD achieves up to 19.8% and 34.7% reduction in hallucination over vanilla LLaVA-1.5 and Qwen-VL-Chat, respectively.
- POPE: Delivers up to +7.9% accuracy and +7.3% F1 improvement under Random, Popular, and Adversarial settings.
- Video Hallucination: Generalizes robustly to video-LLMs, outperforming all baselines with significant margins.
- General Capabilities: Maintains or improves scores on broad benchmarks (MME, MM-Vet, LLaVA-Bench) without tradeoff on general visual-language understanding, unlike prior mitigation pipelines which often degrade non-hallucination metrics.
Ablation studies confirm the necessity of Laplacian-based layer selection, the superiority of high-frequency structural signals over attention magnitude, and the efficiency of single-pass logit mixing.
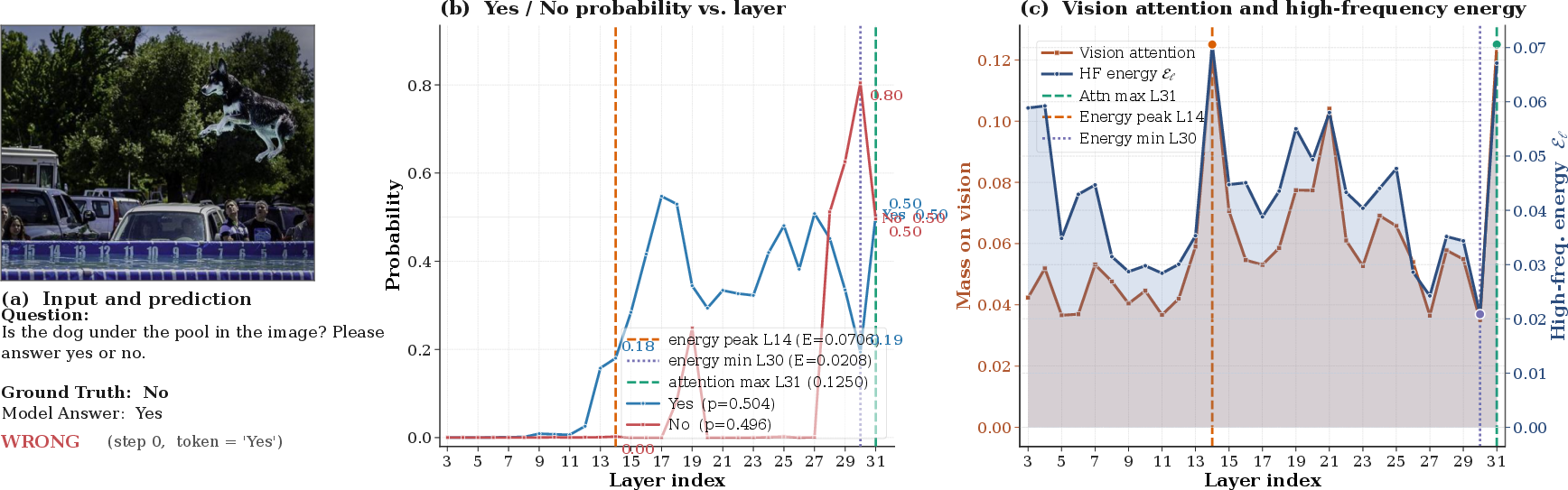
Figure 4: Case study illustrating layer-wise attention structure and effects of LaSCD during hallucination.
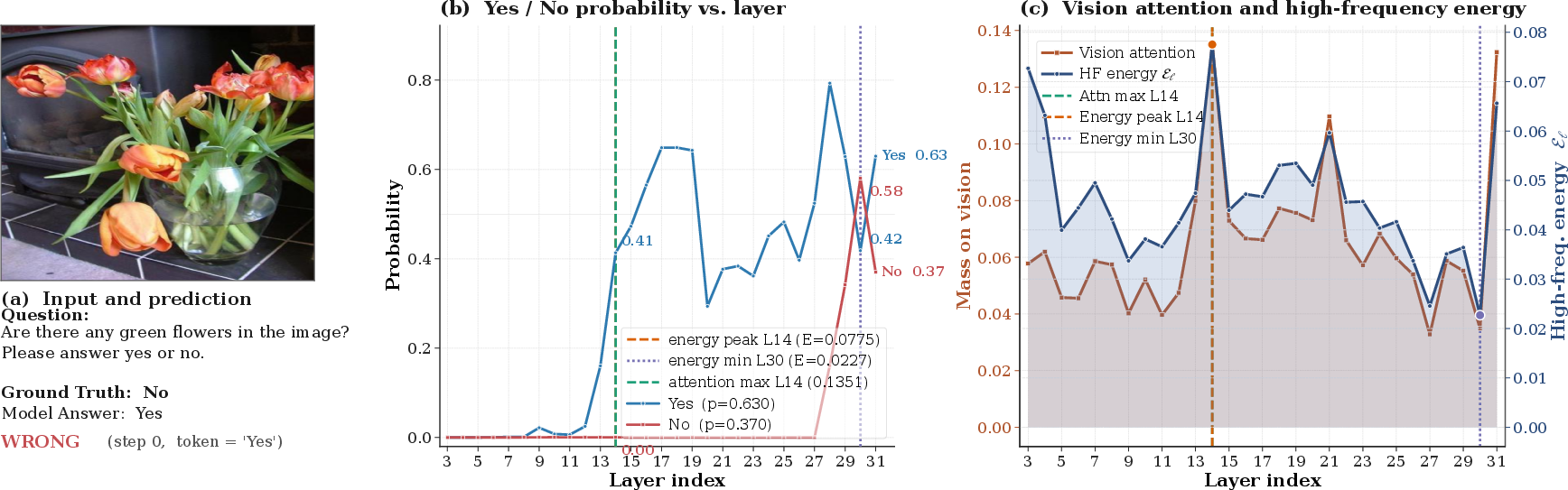
Figure 5: Additional case demonstrating transient ground-truth recovery at minimum-energy layer during decoding.
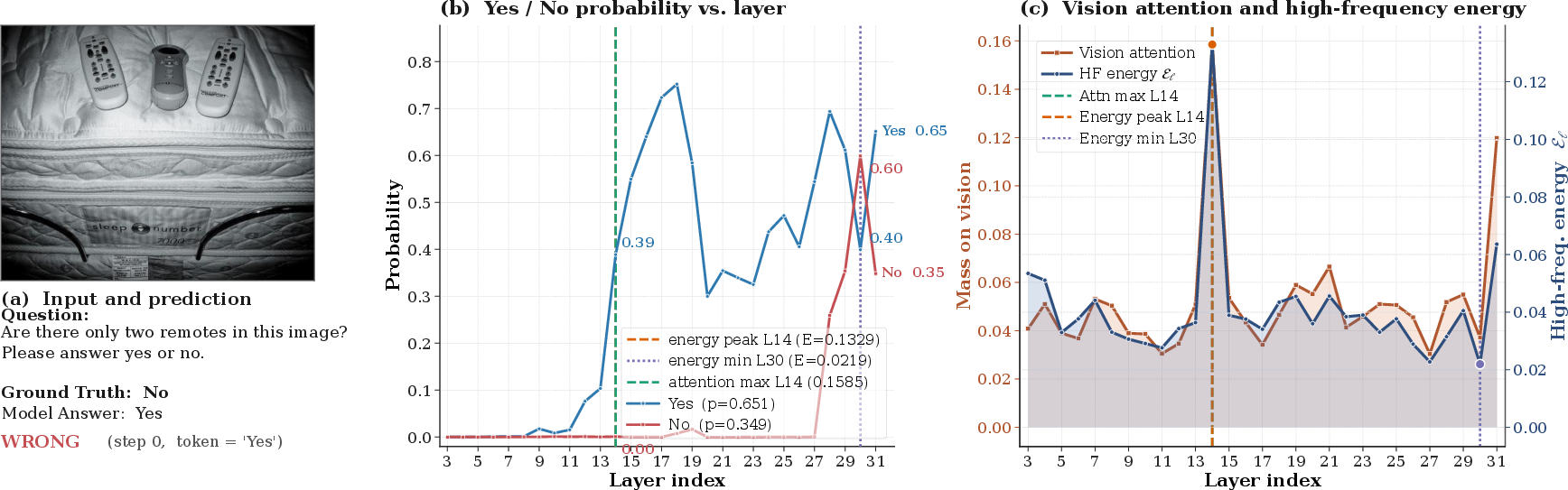
Figure 6: Layer-resolved hallucination progression and LaSCD intervention on another multimodal input.
Complexity and Theoretical Justification
LaSCD introduces minimal complexity—only O(∣L∣HNv) for Laplacian energy computation and logit merging on each decoding step. Theoretical analysis supports the geometric principle that spatially fragmented or high-curvature attention correlates with hallucination, while region-coherent grounding has bounded Laplacian energy.
Implications and Future Directions
The results establish that hallucination in MLLMs is fundamentally a structural phenomenon, not merely a consequence of under-attending to visual evidence. LaSCD demonstrates that targeted suppression based on spectral analysis facilitates more faithful decoding with negligible computational overhead. Practically, this opens avenues for reliable MLLM deployment in safety-critical contexts (healthcare, autonomous systems), where hallucination is unacceptable.
Theoretically, structural attention signals offer a framework for probing internal commitments and failures in multimodal autoregressive models. Potential future developments include extending spectral-layer contrast to more compositional reasoning tasks, supporting larger-scale architectures, and integrating structure-aware signals into backbone training for improved grounding.
Conclusion
The paper provides an authoritative diagnosis of hallucination in multimodal LMs, establishing that high-frequency visual attention structure is a critical signal for internal error localization. LaSCD translates this insight into an efficient, training-free decoding paradigm that achieves state-of-the-art hallucination mitigation while preserving general capabilities. This spectral approach lays a foundation for further mechanistic interrogation and robust deployment of MLLMs (2605.11559).