- The paper introduces a novel framework that aligns recurrent policy hidden states with PMP co-states using a dedicated co-state loss for robust learning under partial observability.
- It rigorously maps standard recurrent architectures like GRUs and CT-RNNs to optimal control formulations, enabling action selection through Hamiltonian minimization.
- Empirical evaluations on DMControl benchmarks reveal that NCP-regularized models improve sample efficiency and stability, especially in challenging continuous control tasks.
Neural Co-state Policies: Structuring Hidden States in Recurrent Reinforcement Learning
Introduction and Theoretical Foundation
This paper introduces Neural Co-state Policies (NCP), a framework that explicitly connects the hidden states of recurrent reinforcement learning (RL) policies to the co-states described by Pontryagin’s Minimum Principle (PMP) from optimal control. In contrast to conventional approaches where recurrent neural networks (RNNs) serve as black-box integrators of environmental history, the NCP formulation asserts that recurrent policy hidden states should, ideally, encode the co-state variables that are fundamental in Hamiltonian formulations of optimal control. The practical motivation is robust policy learning under partial observability—common in continuous control domains—where agents must act on incomplete, noisy observations and rely on internal memory for optimal decision making.
The authors rigorously establish a mathematical mapping from the hidden states of standard recurrent architectures (CT-RNNs, GRUs) to PMP co-states, showing that with suitable structural and algorithmic alignment, the readout layer of these networks can be viewed as minimizing the control Hamiltonian at each timestep. Nevertheless, standard reward maximization objectives do not guarantee that this alignment is achieved in practice. To address this gap, the authors introduce an auxiliary co-state loss based on the Hamilton-Jacobi-Bellman (HJB) equation, aligning the internal dynamics of the network with the necessary optimality conditions for control.

Figure 1: Schematic of NCPs, where recurrent states are regularized to track optimal co-state dynamics according to the minimum principle; the policy readout implements Hamiltonian minimization.
NCP Framework and Architectural Mapping
The NCP class is specified as a coupled dynamic system where the internal state h(t) evolves according to parameterized dynamics mirroring those of theoretical co-states λ(t). Action outputs are determined by minimization of a surrogate Hamiltonian function, parameterized through learned projections of the internal memory state. Crucially, the paper demonstrates that standard architectures (CT-RNNs, GRUs) already possess the affine structure required to represent such latent co-state processes.
More formally, for an environment with state x, observation y, and control u, the recurrent update equations are mapped to the co-state ODEs of PMP. The input weights represent the state-cost gradient, recurrent weights capture the system dynamics Jacobian, and the action readout layer performs Hamiltonian minimization. This mapping provides a principled justification for certain architectural choices in recurrent RL, and grounds the design of more transparent and theoretically-informed memory processes.
Co-state Loss: Bridging RL and Optimal Control
Standard actor-critic RL methods (e.g., PPO with GAE for variance reduction) optimize policies solely for return, leaving hidden states unconstrained in how they track environmental structure. The NCP approach introduces an additional co-state loss, leveraging the fact that the critic's value function gradient with respect to the observation gives an estimate of the optimal co-state. Specifically, the cosine similarity between the hidden state ht and the critic-derived target λ^t=∇y~Vϕ(y~t,ht) is minimized:
Lco-state=Et[1−∥ht∥2∥λ^t∥2ht⋅λ^t].
This loss directs the internal memory to remain aligned with the evolving optimality conditions of control, facilitating learning of more robust and interpretable recurrent policies.
Empirical Evaluation
The NCP framework is evaluated on diverse tasks from the DeepMind Control Suite under severe partial observability, induced by stochastic masking of the entire observation vector at each timestep (with p=0.5). Performance is compared between standard recurrent policies and NCP variants (NC-GRU, NC-CTRNN).
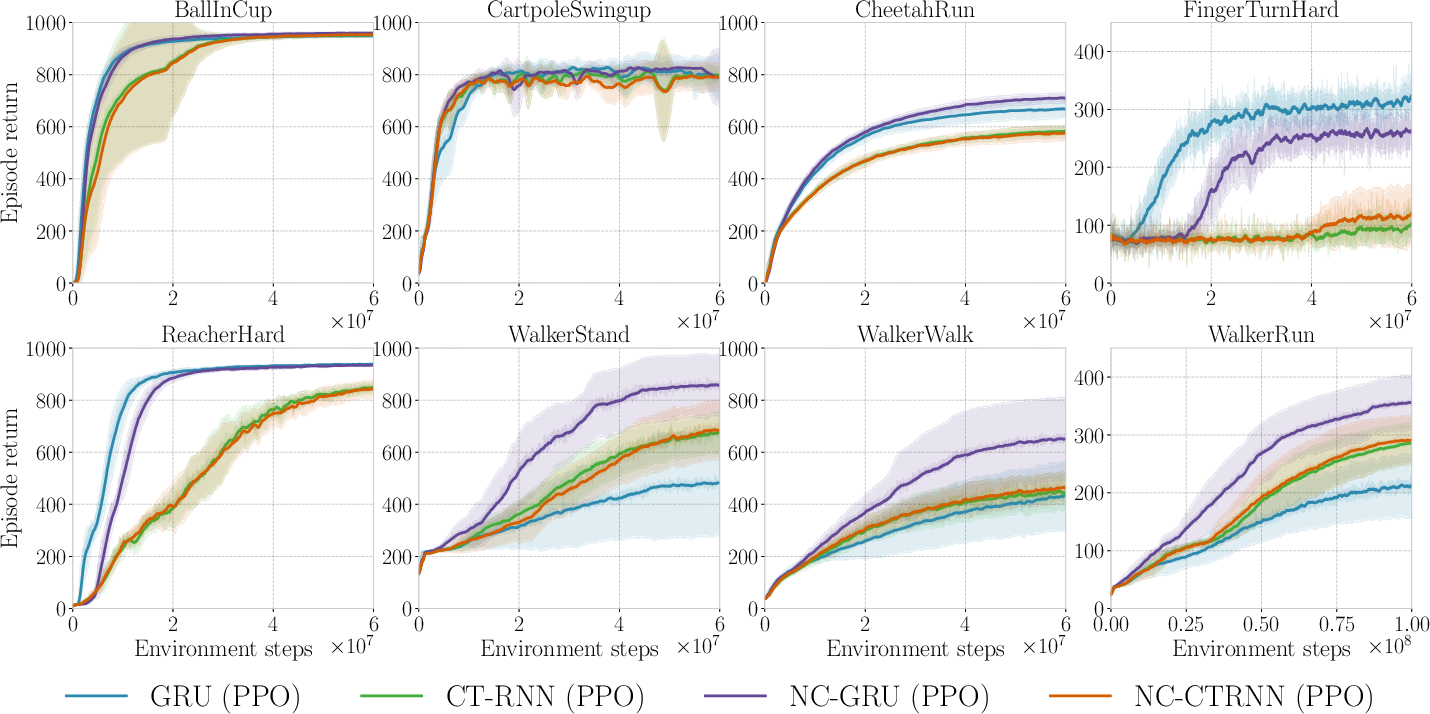
Figure 2: Learning curves on DMControl benchmarks under 50% sensor dropout show NCP-regularized GRUs exhibit improved final return and stability on locomotion tasks, with competitive convergence on simpler tasks.
On simpler environments such as CartpoleSwingup and BallInCup, all architectures learn successfully, though NCP-regularized models converge slightly slower due to the regularization. On more complex locomotion tasks (e.g., WalkerStand, WalkerWalk, WalkerRun, CheetahRun), the NC-GRU outperforms standard GRU baselines both in terms of sample efficiency and final asymptotic performance. Results on FingerTurnHard reveal a marginal performance drop with strong co-state loss, reflecting the limitations of the co-state estimation process under extreme noise or manipulation requirements.
Ablation on the co-state loss coefficient reveals that an intermediate penalty (c3=0.05) yields the highest return and co-state alignment, with excessive penalization (λ(t)0) degrading performance, suggesting a trade-off between regularization and representational flexibility.
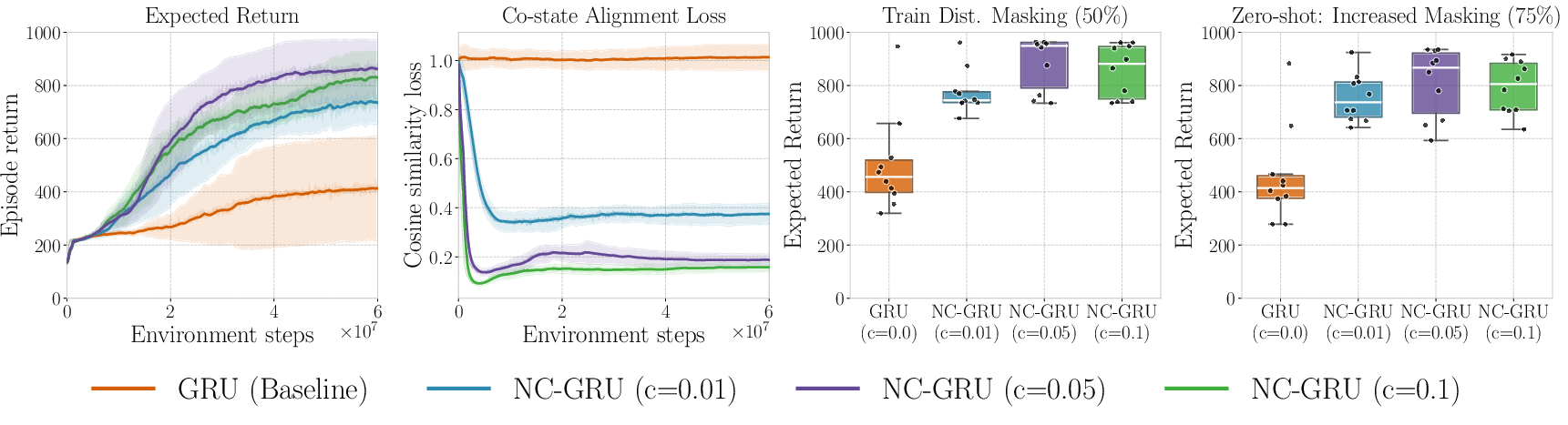
Figure 3: Ablation illustrates the effect of the co-state loss strength: optimized coefficients maximize expected return and latent alignment; the NCP also maintains a higher median performance in OOD masking conditions (75% dropout), linking robustness to improved training-time returns.
In zero-shot OOD experiments (increased from 50% to 75% masking at test time), all models suffer performance degradation, but NCPs retain the higher median return established during training. This indicates that the principal benefit of co-state regularization is not general robustness to arbitrary masking, but elevation of the operating point within the training distribution—a level of robustness inherited by OOD evaluation.
Implications, Limitations, and Future Directions
The theoretical unification of RL memory and PMP co-states offers substantial implications for both interpretability and algorithm design in continuous control. By anchoring black-box latent states in the mathematics of optimal control, policy design becomes more principled, enabling architectural innovations such as theoretically-optimal readout layers customized to specific cost functions (quadratic, bang-bang, fuel-optimal, etc.). The explicit formulation supports extensions to Bayesian methods for managing epistemic uncertainty by maintaining ensembles of value gradients, which could further increase robustness and sample efficiency, as detailed in the appendices.
Practical limitations include the reliance on stable, accurate estimation of co-state targets via the value gradient, which is inherently noisy due to function approximation and partial observability. The bounded nature of conventional network activations also introduces deviations from unconstrained PMP dynamics, potentially limiting the exactness of the mathematical tracking. The framework is readily generalizable, however, to more expressive recurrent memory structures (LSTM, oscillatory models) and environments requiring more sophisticated readout layers for non-smooth (e.g., time- or fuel-optimal) control.
Conclusion
Neural Co-state Policies provide a rigorous, control-theoretic lens for the design and interpretation of recurrent memory in deep RL. By explicitly regularizing hidden states to follow PMP optimality conditions, this framework enables the construction of robust, partially interpretable policies for continuous control under extreme observation constraints. The empirical findings demonstrate marked gains in sample efficiency, stability, and robust performance on challenging locomotion benchmarks. The framework opens new research avenues in policy-structure alignment, uncertainty-aware RL, and the theoretical analysis of RNN-based control agents (2605.05373).