A Replicability Study of XTR
Abstract: The XTR (conteXtual Token Retrieval) algorithm is a modification to ColBERT retrieval that avoids the costly step of fully gathering and reranking the candidates' embeddings by imputing their missing similarity scores from the initial token retrieval step. The original work proposes a modified training objective as necessary for effective XTR retrieval, arguing that standard ColBERT token scoring is unsuitable for imputation. In this paper, we replicate both the XTR retrieval algorithm and its modified training objective, and extend the evaluation to knowledge-distillation (KD) training and efficient retrieval engines (PLAID and WARP). We confirm the token-level matching characteristics claimed in the original work, but fail to replicate XTR's overall effectiveness advantage over ColBERT under a controlled comparison. We further show that XTR's training modification has a concrete mechanistic consequence for modern retrieval engines: by flattening ColBERT's characteristically peaked token score distribution, XTR training yields more discriminative centroid scores and thus more efficient IVF-based retrieval under PLAID and WARP. The utility of XTR training is therefore not limited to the low-$k'$ regime originally studied, but extends to any deployment setting where IVF-based engines are used. These findings offer practitioners concrete guidance on how and when to use XTR as their multi-vector retriever.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper checks whether a newer, faster way to search through text called XTR really works as well as its original creators claimed. It compares XTR to a popular search method called ColBERT and looks at how to train and use these systems to make search both accurate and fast.
What questions did the researchers ask?
The researchers focused on five simple questions:
- Can we recreate (replicate) the XTR method and its special training idea using our own code and data?
- Is XTR actually more accurate than ColBERT, as earlier work suggested?
- How does XTR behave when we give it fewer “hints” to start with (meaning, when we retrieve fewer matching pieces at the start)?
- Does XTR’s special way of training change how the model scores word-to-word matches in a useful way?
- Do these changes make search faster in real-world search engines that use clustering tricks (called PLAID and WARP)?
How did they do it?
Think of searching like this:
- Each document and each query (the user’s question) is broken into many small pieces, like words or word parts (called tokens).
- Each token gets turned into a tiny “fingerprint” made of numbers (an embedding) that captures its meaning.
- ColBERT scores a document by, for each query token, finding the single most similar document token and adding all those best-match scores together. That’s powerful, but slow if you have to load all tokens from every possible document.
Here’s what XTR changes:
- Instead of loading every token from each candidate document, XTR first quickly retrieves only the top k′ matching tokens for each query token across the whole collection.
- For the document tokens it didn’t load, XTR “guesses” their scores using a safe estimate: the smallest score among the retrieved tokens for that query token. This avoids loading lots of data and makes search much faster.
Training differences:
- Normal ColBERT training learns to score all token matches.
- XTR’s training simulates the fast search setting by only allowing the top k_train matches per query token to contribute to learning; everything else is dropped. This teaches the model to focus on the most retrievable matches, which is closer to what happens at search time.
Search engines tested:
- The team tested basic nearest-neighbor search (like ScaNN) and modern, faster engines called PLAID and WARP.
- PLAID and WARP speed up search by grouping token embeddings into clusters (think “buckets”). At query time, they only look into the most promising buckets. This makes speed depend on how clearly the model’s scores separate good buckets from bad ones.
Data and evaluation:
- They evaluated on common search benchmarks (like BEIR and LoTTE) and measured standard metrics such as nDCG@10, Recall@100, and MRR@10.
- They trained both “classic” models (contrastive learning) and “teacher–student” models (knowledge distillation), where a smaller “student” learns from a stronger “teacher” model.
What did they find?
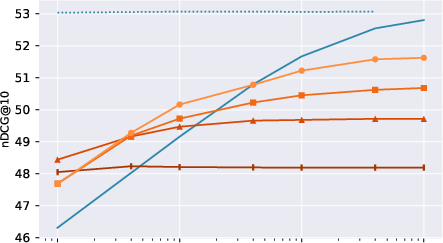
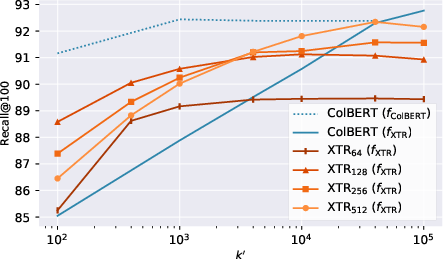
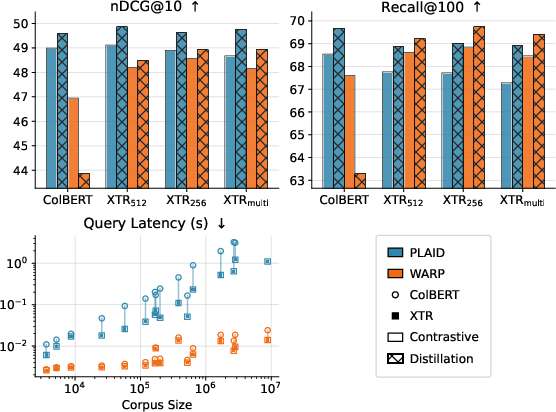
- XTR wasn’t strictly more accurate than ColBERT
- When they ran a careful, controlled comparison, they couldn’t reproduce the original claim that XTR is more accurate overall. In their tests, ColBERT often kept a small accuracy edge.
- Even so, ColBERT models could use XTR’s faster scoring method and still keep most of their accuracy when the initial token budget k′ was large.
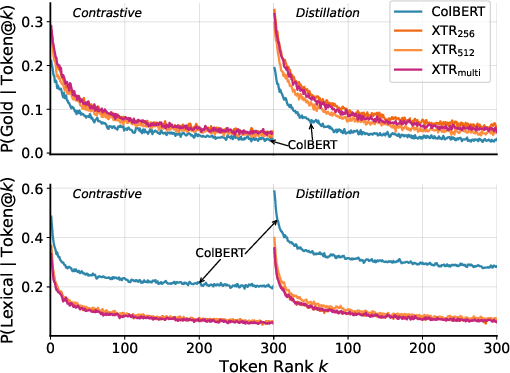
- XTR training improves how tokens are retrieved
- Models trained with XTR’s special objective were better at pulling in relevant tokens from relevant documents, especially when k′ (the number of tokens retrieved at the start) was small.
- XTR-trained models relied less on exact word matching and more on meaning, which helps handle synonyms and different phrasings.
- This made XTR more robust when using a small starting budget (a speed-sensitive situation).
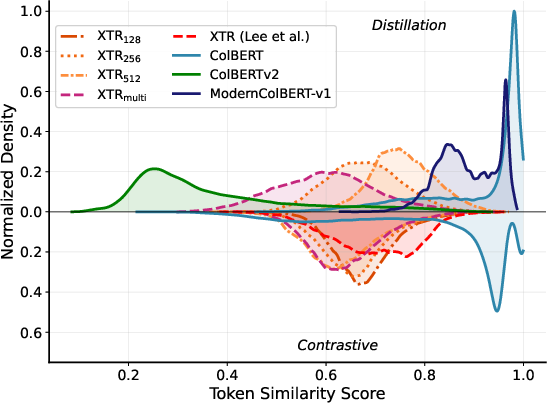
- The shape of scores matters a lot for speed
- ColBERT’s token scores tend to be very “peaked” near the top—many tokens look very similar and high-scoring.
- XTR training “flattens” this score distribution a bit, making it easier to tell good clusters from bad ones.
- In fast engines like PLAID and WARP that search via clusters, clearer separation means fewer clusters to search, fewer candidate documents, and much lower latency.
- In practice, XTR-trained models ran much faster on WARP and also helped PLAID, even when accuracy was similar.
- Tweaking XTR’s “guessing” strategy didn’t change much
- They tried different ways to “guess” the missing scores for non-retrieved tokens. Using the minimum retrieved score worked as well as or better than other options in their tests.
- Mixing XTR and ColBERT reranking wasn’t very helpful
- They tried using fast XTR scoring first and then re-scoring the top documents with full ColBERT, hoping to boost accuracy. This barely improved results, suggesting the main limits aren’t in the guessing step alone.
Why does this matter?
- If you need maximum accuracy and can afford more compute, ColBERT still has a slight edge in many cases.
- If you need speed—especially with modern, cluster-based engines like PLAID and WARP—training with XTR’s objective helps a lot. It shapes token scores in a way that makes these engines more efficient without a big accuracy drop.
- XTR’s benefits aren’t just for “tiny starting budgets” (small k′). The training changes also help any setup that uses clustered (IVF-based) engines.
Bottom line
- XTR’s training doesn’t magically make retrieval more accurate than ColBERT across the board.
- But it does change how token matches are scored in a useful way, making fast search engines more effective and often much faster.
- Practical guidance: If your system uses engines like PLAID or WARP and you care about latency, train with XTR’s objective. If you’re purely chasing peak accuracy and time isn’t a big issue, ColBERT may still be slightly better. In many real systems, XTR training provides a strong speed–quality trade-off.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unanswered questions left by the paper that future researchers can address:
- Incomplete large-scale evaluation: ColBERT+PLAID was not evaluated on MS MARCO due to computational constraints, leaving unclear whether the observed efficiency and effectiveness trends hold on the largest, most realistic corpora.
- Fairness and sensitivity of engine hyperparameters: WARP parameters were increased (e.g., n_probes=32, t'≈100k) while PLAID used more conservative defaults; a systematic, iso-latency/iso-QPS comparison across engines and settings is missing.
- Generalization of findings across ANN backends: Results rely on ScaNN (config I) and PLAID/WARP (config II); it remains unclear how conclusions transfer to other token-ANN indexes (e.g., HNSW, FAISS IVFPQ/HNSW, SPANN) and their parameterizations.
- Stability of XTR training across k_train and batch regimes: XTR_128 diverged under KD in config II; the paper does not quantify stability regions or provide guidelines for k_train vs. batch size, negatives, and temperature choices.
- Teacher dependence in distillation: Only one teacher/setup is examined; how different teachers (quality, calibration, ranking behavior) and distillation objectives (e.g., listwise, margin-based, temperature schedules) affect XTR vs. ColBERT remains untested.
- Initialization effects: Models were initialized from BGE-small (config I) and ModernBERT-base (config II); how backbone size, pretraining corpus, and prior retrieval tuning influence XTR’s efficiency/quality trade-offs is not explored.
- Objective design beyond hard masking: XTR_train zeroes out non-retrieved token scores and normalizes by Z; alternatives (e.g., soft/relaxed top-k, straight-through estimators, differentiable sparse retrieval, curriculum over k_train, learned token gates) are not evaluated.
- Mechanistic link between training and centroid separability: The paper observes flatter token-score distributions with XTR and posits better IVF centroid discrimination, but lacks a formal objective-geometry-efficiency analysis or a predictive metric for engine efficiency.
- Regularization for engine-friendliness: There is no exploration of explicit regularizers (e.g., contrastive centroid-margin, entropy/temperature control, anti-collapse constraints) to shape centroid score separability without sacrificing effectiveness.
- Learned/improved imputation for XTR: Only hand-crafted imputations (min, mean, percentile, power-law, zero) are tried; learned imputers, per-query calibrations, or corpus-conditioned priors for missing scores are not explored.
- Hybrid scoring policies: The paper briefly tests XTR→ColBERT reranking and finds negligible gains at k''≤16k; adaptive per-query scheduling of k', k'', and selective residual loading (e.g., risk-aware or confidence-based) is not studied.
- Token retrieval budget adaptation: k' is treated as a static knob; dynamic per-query k' allocation (based on score dispersion, early-stop criteria, or query difficulty) is untested.
- Under-explored index precision trade-offs: PLAID uses 2-bit residuals; the effect of residual precision (1–4 bits), centroid codebooks, and quantizer choices on the XTR vs. ColBERT gap is not systematically ablated.
- Tail-latency and throughput under realistic workloads: The evaluation reports mean latency/QPS; tail latency (p95/p99), batch effects, and multi-tenant deployment behavior are not measured.
- Memory footprint and build-time costs: The work focuses on query-time latency but does not report index size, memory bandwidth utilization, or indexing/build-time costs across engines and models.
- Effect of tokenization and markers: The paper omits [Q]/[D] markers and uses fixed token limits (queries: 32–64; docs: 300); the impact of markers, token limits, and tokenization choices on XTR’s retrieval and engine efficiency is not analyzed.
- Long-document and multi-hop scenarios: Documents are truncated to 300 tokens; how XTR scales to longer documents, multi-field passages, or multi-hop retrieval remains unanswered.
- Domain and language generalization: Evaluations cover a BEIR subset and LoTTE (English); robustness to other domains (biomedical/legal), multilingual corpora, and low-resource settings is not studied.
- Query-type sensitivity: There is no breakdown by query length, ambiguity, or difficulty (head vs. tail queries), leaving it unclear where XTR training provides the largest net benefit.
- Robustness to lexical shift and adversarial mismatches: While XTR reduces lexical dependence, there is no robustness evaluation under vocabulary shift, paraphrase-heavy queries, or adversarial lexical perturbations.
- Relation between anisotropy and efficiency: The paper shows anisotropy alone does not predict engine efficiency; identifying better predictive geometry/statistical metrics and validating them across models/datasets remains open.
- Calibration of pruning thresholds: Engine pruning thresholds are set heuristically; methods to automatically calibrate thresholds from score distributions to control candidate set size vs. quality are not presented.
- Cross-collection training and transfer: Models are trained on MS MARCO and evaluated on diverse collections; systematic studies on cross-collection fine-tuning, zero-shot transfer, and catastrophic forgetting are missing.
- Reproducibility of original XTR training: Since the original training code was unavailable and third-party implementations had bugs, exact reproducibility of the original objective and nuances (e.g., Z normalization choices) remains unresolved.
- Interaction with joint PQ/encoder training: Prior work (e.g., joint PQ) is mentioned but not combined with XTR; whether engine-aware joint training further improves centroid separability and latency is untested.
- Scaling to larger encoders: Only base-scale encoders are explored; whether XTR’s efficiency/quality advantages persist or improve with larger backbones (e.g., large/XL) is unknown.
- ANN indexing for token retrieval in config II: Token-level analyses in config II still use ScaNN; whether token retrieval behaviors (p_gold, lexical match rates) are consistent across different ANN token indexes is not verified.
Practical Applications
Immediate Applications
The following applications leverage the paper’s replicated findings, analyses, and released tooling to improve current retrieval systems and research workflows.
- XTR-trained models for IVF-based engines to cut latency and cost
- Sectors: software/search, e-commerce, enterprise knowledge search, healthcare/biomed (literature), legal e-discovery, customer support
- What to do: Train or fine-tune multi-vector retrievers with the XTR training objective (masking with k_train) and deploy on centroid/IVF engines like PLAID or WARP. The paper shows XTR training flattens token-score distributions, yielding more discriminative centroid scores and smaller candidate sets, thus lower query latency.
- Tools/workflows: PyLate-based training/serving; FastPlaid and xtr-warp-rs backends; GPU-accelerated indexing; 2-bit residuals (PLAID) and tuned n_probes, t' (WARP).
- Assumptions/dependencies: Works best with IVF-style engines; requires tuning n_probes and cluster thresholds; assumes sufficient training data and KD improves stability/effectiveness; hardware availability (GPUs) for indexing/search.
- Near-term efficiency upgrade for existing ColBERT stacks using XTR retrieval
- Sectors: software/search, RAG platforms, internal enterprise search
- What to do: For high k′ settings (e.g., 40k tokens retrieved per query token), use f_XTR with ColBERT-trained models to avoid full embedding gathers while maintaining most of ColBERT’s effectiveness (per paper, >99% in some settings).
- Tools/workflows: Swap ColBERT MaxSim reranking with XTR’s imputation scoring when token retrieval dominates latency; keep full reranking optional for top-k′′ documents if needed.
- Assumptions/dependencies: Effectiveness gains do not consistently exceed ColBERT; small or moderate k′ can reduce effectiveness; monitor recall and nDCG; sensitive to engine and index parameters.
- Retrieval layer acceleration for LLM-RAG pipelines
- Sectors: software/AI platforms, developer tooling, customer support, documentation search
- What to do: Replace traditional MaxSim-first retrieval in RAG with XTR-trained models on WARP for the first-stage retrieval. The paper shows substantial speedups (WARP vs PLAID geometric mean ~16× QPS), with XTR-trained models achieving superior latency due to better centroid separability.
- Tools/workflows: Integrate with LangChain/LlamaIndex retrieval modules; PyLate training; PLAID/WARP backends with tuned n_probes; KD to improve effectiveness at fixed latency.
- Assumptions/dependencies: Requires IVF engines; trade-offs between latency and effectiveness still apply; ensure distillation teacher quality; tune k_train for target latency regime.
- Practitioner guidance for parameterization and deployment
- Sectors: software/search engineering, MLOps
- What to do: Apply the paper’s guidance on k_train/k′ trade-offs:
- Higher k_train improves effectiveness at larger k′ but increases sensitivity when k′ is small.
- XTR training particularly helps low-k′ robustness and improves centroid discriminability for IVF engines.
- Tools/workflows: Add configuration knobs for k_train in training and k′/n_probes in serving; ship defaults per dataset scale and SLA.
- Assumptions/dependencies: Requires per-corpus tuning; XTR does not universally outperform ColBERT in effectiveness; set monitoring to track regressions.
- Diagnostics and monitoring for centroid separability and score-shape health
- Sectors: MLOps, search quality engineering
- What to do: Monitor token-level score distributions and centroid candidate-set sizes to detect “peaked” score pathologies that inflate IVF candidate sets and latency. Track metrics like effective dimensionality, mean pairwise cosine, and bimodality of centroid scores.
- Tools/workflows: Add “centroid separability report” into retriever CI/CD; integrate with PLAID/WARP logs; leverage the paper’s analysis methods.
- Assumptions/dependencies: Requires telemetry at token/centroid level; normalizes across datasets and engines; complements rather than replaces relevance metrics.
- Cost and energy savings in cloud search operations
- Sectors: cloud platforms, green AI initiatives, enterprise search
- What to do: Migrate to XTR-trained models on WARP or PLAID to reduce GPU time per query and memory bandwidth (smaller candidate sets, fewer decompressions), cutting operational costs and carbon footprint.
- Tools/workflows: Profile QPS and GPU utilization pre/post migration; adopt KD for effectiveness retention at lower probe counts.
- Assumptions/dependencies: Savings depend on corpus size, engine parameters, and hardware; ROI increases with scale.
- Reproducible research and benchmarking
- Sectors: academia, industry research labs
- What to do: Use the PyLate-integrated XTR training and released models for replicable experiments, ablations (imputation methods, k_train choices), and engine comparisons (ScaNN vs PLAID vs WARP).
- Tools/workflows: PyLate, FastPlaid, xtr-warp-rs; datasets like BEIR and LoTTE; KD pipelines with min-max normalization and learnable temperature.
- Assumptions/dependencies: Reproducibility depends on matching hardware, index configs, and careful bug avoidance (paper corrected issues in prior open-source implementations).
- Domain search improvements under tight SLAs
- Sectors: healthcare (evidence retrieval), legal (e-discovery), finance (research search), government portals
- What to do: For large corpora and strict latency SLAs, deploy XTR-trained models with IVF engines to maintain recall at lower k′ and achieve faster answers.
- Tools/workflows: Deploy per-dataset tuned n_probes and k′; use KD with high-quality teachers to improve nDCG@10 without large latency increases.
- Assumptions/dependencies: Effectiveness is dataset-dependent; regulatory domains may require interpretability/traceability—retain logs and optionally re-rank critical results.
Long-Term Applications
The following opportunities require further research, scaling, or productization beyond what is immediately deployable from the paper.
- Adaptive hybrid retrieval schedulers (dynamic XTR ↔ ColBERT switching)
- Sectors: software/search, RAG, high-frequency query platforms
- What: Develop controllers that dynamically allocate token retrieval budgets and decide when to impute (XTR) vs. perform full MaxSim given early signals (e.g., centroid score separability, query intent, SLA pressure).
- Potential products: An engine-agnostic “retrieval budget optimizer” plugin for PLAID/WARP that balances latency-quality targets in real-time.
- Assumptions/dependencies: Requires new algorithms and policies; must monitor query-dependent variability; careful evaluation to avoid quality regressions.
- Improved training objectives and imputation heuristics to narrow the XTR–ColBERT gap
- Sectors: IR research, AI platforms
- What: Explore learned or adaptive imputation for missing token scores (beyond min/percentile/power-law), and loss functions that directly optimize centroid separability or score bimodality while preserving effectiveness.
- Potential tools: Differentiable approximations for imputation; regularizers for score-shape; curriculum on k_train schedules; shape-aware KD.
- Assumptions/dependencies: Needs robust benchmarks and ablations; effectiveness improvements may be corpus-specific.
- Score-shape regularization for IVF retrieval
- Sectors: IR research, MLOps tooling vendors
- What: Introduce explicit regularization to avoid overly peaked token similarity distributions that harm IVF candidate pruning and latency.
- Potential products: “Separability-aware” training plugin for multi-vector retrievers; offline score-shape auditing suite.
- Assumptions/dependencies: Must avoid hurting relevance; requires portable metrics across engines and corpora.
- Widespread integration with search platforms (OpenSearch, Vespa, Elastic)
- Sectors: enterprise search, e-commerce, developer tools
- What: Productize XTR-trained multi-vector retrieval with IVF backends as first-class features in managed search platforms, offering low-latency, high-recall multi-vector retrieval.
- Potential products: Managed “XTR-ready” indices, auto-tuned n_probes/k′, and KD-based model templates.
- Assumptions/dependencies: Requires engineering integration and GPU/accelerator support; sustained maintenance for parameter auto-tuning across workloads.
- Cross-lingual and domain-specialized XTR training recipes
- Sectors: healthcare, legal, finance, multilingual search
- What: Extend XTR training and KD schemes to non-English and specialized corpora, aligning token-level behavior (less lexical dependence, better contextual matching) to domain needs.
- Potential products: Domain-tuned XTR model families with engine presets per domain; teacher rerankers customized to domain.
- Assumptions/dependencies: Access to high-quality, domain-specific KD teachers and datasets; domain effectiveness validation.
- On-device or privacy-preserving multi-vector retrieval
- Sectors: mobile, privacy/security, personal knowledge bases
- What: Leverage the efficiency gains from XTR-style training and IVF engines to enable lightweight or edge retrieval without server-side embedding gathers, reducing bandwidth and exposure.
- Potential products: On-device IVF retrievers for personal search; hybrid client-server retrieval with minimal token transfers and imputation.
- Assumptions/dependencies: Requires compact models and quantization; memory constraints on device; careful privacy-by-design evaluation.
- Energy-aware and policy-aligned procurement for “Green IR”
- Sectors: public sector, sustainability initiatives
- What: Use efficiency evidence (e.g., XTR-trained models on IVF engines) to guide procurement and policy favoring lower energy-per-query systems for public portals and open data platforms.
- Potential tools: Energy/QPS dashboards; procurement criteria frameworks referencing separability metrics and candidate-set sizes.
- Assumptions/dependencies: Requires standardized measurement of energy use; balancing fairness, transparency, and retrieval quality in public deployments.
- Federated and cross-silo retrieval at scale
- Sectors: large enterprises, regulated industries
- What: Apply IVF-based XTR-trained retrieval across siloed indices to keep per-silo latency low and aggregate results efficiently, especially when full embedding gathers are impractical.
- Potential products: Federated IVF routers with per-silo n_probes tuning; unified relevance calibration via KD.
- Assumptions/dependencies: Consistent schema and scoring across silos; fairness and compliance checks for aggregation.
Notes on feasibility:
- XTR training improves efficiency under IVF engines broadly; however, pure effectiveness (e.g., nDCG@10) does not consistently exceed ColBERT under controlled comparisons. Adopt based on efficiency goals, SLAs, and the specific engine.
- Distillation improves performance and can sharpen or widen score distributions differently across models; monitor both relevance and score-shape metrics.
- Default engine parameters (e.g., WARP’s n_probes) may be overly conservative; tuning is necessary to realize benefits.
Glossary
- anisotropic quantization: A quantization scheme that scales and rotates dimensions to better match data variance, often improving compression fidelity over isotropic (uniform) schemes. "The index also employs single-codebook (global) anisotropic quantization with a quantization threshold of 0.1."
- approximate k-nearest-neighbor search: Fast, heuristic methods for retrieving items near a query point in vector space without exact distance calculations. "approximate -nearest-neighbor search"
- BEIR benchmark: A standard suite of heterogeneous retrieval datasets for evaluating information retrieval systems. "Across our experiments we evaluate on a subset of the BEIR benchmark"
- bi-encoders: Models that encode queries and documents independently into vectors, enabling offline indexing and fast retrieval. "maintaining the offline indexability of bi-encoders."
- centroid interaction: Using cluster centroids of token embeddings to cheaply approximate interactions for candidate generation and coarse scoring. "uses centroid interaction for cheap candidate generation"
- ColBERT: A late-interaction retrieval architecture that encodes queries and documents independently and computes fine-grained token-level similarities. "ColBERT encodes queries and documents independently"
- contrastive loss: A learning objective that brings matched pairs closer and pushes mismatched pairs apart in embedding space. "Models are trained with a contrastive loss with in-batch negatives"
- cross-encoder: A model that jointly encodes the query and document together, typically more expressive but computationally expensive. "cross-encoder joint attention"
- effective dimensionality: A measure of how many dimensions are meaningfully used by embeddings, related to isotropy/anisotropy. "effective dimensionality (1.8 vs.\ 3.7)"
- embedding anisotropy: When embeddings concentrate in a narrow subspace of the unit sphere, reducing score discriminability. "Embedding anisotropy provides a useful but incomplete lens"
- in-batch negatives: Negative examples drawn from other items within the same training batch for contrastive learning efficiency. "in-batch negatives"
- InfoNCE-style contrastive loss: A specific contrastive objective (InfoNCE) that uses a softmax over positives and negatives for representation learning. "a modification to the InfoNCE-style contrastive loss used to train ColBERT."
- IVF-based retrieval: Retrieval over an inverted file (IVF) index that assigns vectors to coarse clusters (centroids) and probes a subset to find candidates efficiently. "more efficient IVF-based retrieval under PLAID and WARP."
- KL objective: A distillation loss based on Kullback–Leibler divergence to match a student’s scores to a teacher’s scores. "with a KL objective to match a teacher's"
- knowledge distillation (KD): Training a smaller/faster “student” model to mimic a larger “teacher” model’s outputs. "extend the evaluation to knowledge-distillation (KD) training"
- late interaction: A retrieval paradigm that delays interaction between query and document representations until after independent encoding, enabling token-level matching. "late interaction falls behind in terms of efficiency."
- MaxSim: ColBERT’s scoring operator that, for each query token, takes the maximum similarity over all document tokens and sums across query tokens. "Relevance is scored via the MaxSim operator"
- MRR@10: Mean Reciprocal Rank at 10, a ranking metric that averages the reciprocal rank of the first relevant result, truncated at 10. "MRR@10 for MS MARCO"
- multi-vector retriever: A retrieval system that represents queries/documents with multiple vectors (e.g., token-level) rather than a single vector. "how and when to use XTR as their multi-vector retriever."
- nDCG@10: Normalized Discounted Cumulative Gain at 10, a graded relevance ranking metric truncated at the top 10 positions. "nDCG@10"
- PLAID: An engine for ColBERT-like models that uses clustered term representations (centroids) to retrieve and progressively prune candidates efficiently. "PLAID builds on this with a multi-stage pipeline"
- product quantization (PQ): A vector compression technique that splits vectors into subspaces and quantizes each with its own codebook. "PQ index"
- residual compression: Representing vectors as a centroid plus a low-bit residual vector to reduce storage and speed up retrieval. "introduces residual compression"
- ScaNN: A scalable nearest neighbor search library/algorithm for efficient vector retrieval. "ScaNN index for token retrieval."
- WARP: An efficient engine for multi-vector retrieval that adapts PLAID-like optimizations to XTR-style retrieval. "WARP, a followup work to XTR"
- XTR (conteXtual Token Retrieval): A retrieval algorithm modifying ColBERT by imputing missing token similarities to avoid loading full document embeddings. "The XTR (conteXtual Token Retrieval) algorithm"
Collections
Sign up for free to add this paper to one or more collections.