- The paper introduces an iterative retrieval system that diagnoses evidence gaps to refine query responses across multi-session conversational memory.
- It integrates IRIS and LaceMem—combining dual-path retrieval with a layered memory hierarchy—to significantly enhance temporal and multi-hop reasoning.
- Experimental validation shows improved judge accuracy (up to 87.3%) and a 4.5× reduction in latency, proving its efficacy on complex, cross-session queries.
Evidence-Gap-Driven Retrieval for Long-Term Conversational Memory: EviMem
Motivation and Architectural Limitations
The challenge of long-term conversational memory in LLM-based agents is primarily the retrieval of evidence distributed across multi-session interaction histories. Conventional retrieval approaches—single-pass pipelines with static queries—fail on temporal and multi-hop questions requiring cross-session synthesis and reasoning. This deficiency is rooted in the open-loop nature of retrieval: queries are constructed before any evidence is examined and lack iterative refinement driven by evidence sufficiency. For multi-session or temporal questions, semantic drift and forced top-K selection lead to the accumulation of noisy, insufficient evidence, crippling downstream reasoning.
Several iterative retrieval frameworks attempt to address these shortcomings but lack explicit gap diagnosis mechanisms. Existing approaches, such as chain-of-thought re-query (IRCoT), content-driven refinement (Iter-RetGen, FLARE), document-level sufficiency (Self-RAG, CRAG), and meta-agent orchestration (MIRIX), focus on generated outputs or passage-level signals. None systematically diagnose what evidence is missing from the cumulative retrieval set at granularity sufficient for cross-session reasoning. Consequently, query refinements are unguided, often leading to blind iteration rather than targeted gap-filling.
EviMem System: IRIS and LaceMem Integration
EviMem introduces a closed-loop retrieval architecture explicitly driven by evidence-gap diagnosis, composed of two mutually enabling subsystems: IRIS (Iterative Retrieval via Insufficiency Signals) and LaceMem (Layered Architecture for Conversational Evidence Memory).
LaceMem Memory Hierarchy
LaceMem structures conversational history into a three-layer coarse-to-fine hierarchy—Index, Edge, and Raw. The Index layer consists of atomic semantic tuples (subject, predicate, object, event_time) extracted from each speaker turn, enabling granular evidence search and gap detection. The Edge layer encodes multi-hop graph links, both within-turn and semantic similarity edges, to support associative recall across sessions. The Raw layer stores verbatim dialogue, ensuring grounding of generated answers.
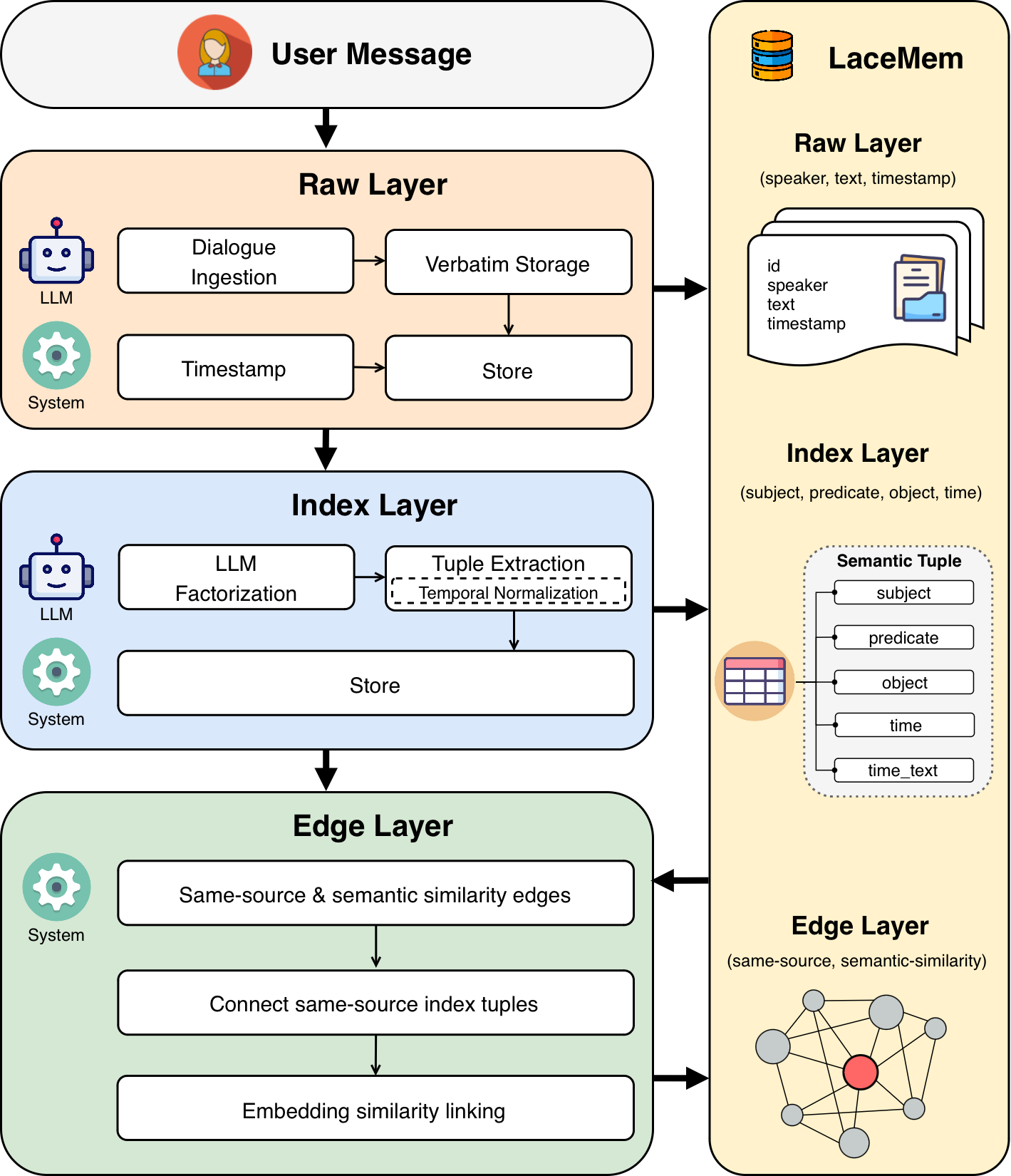
Figure 1: LaceMem memory architecture: three-layer hierarchy for search, multi-hop expansion, and grounded answer generation.
This architecture facilitates efficient search (Index), relational expansion (Edge), and high-fidelity context retrieval (Raw), supporting precise evidence tracking and retrieval at scale.
IRIS Iterative Retrieval Framework
IRIS operates as an explicit evidence-gap-driven iterative loop. Each iteration comprises:
- Dual-path retrieval: One path anchored to the original question and a second refinement path driven by explicit diagnoses of missing information.
- Entity fact tracking: Per-entity buffers accumulate retrieved facts, flagging underrepresented entities invisible to query-level evaluation.
- Sufficiency evaluation: An LLM classifies the evidence set as EXACT, INFERRABLE, or PARTIAL, assigns confidence, and delivers a natural-language diagnosis specifying missing evidence.
- Query refinement: The gap diagnosis, rather than a draft answer, drives the next iteration's query, anchoring on the original question to prevent drift.
The loop terminates when tiered sufficiency is achieved or the maximum iteration budget is exhausted, enforcing abstention when evidence remains inadequate.
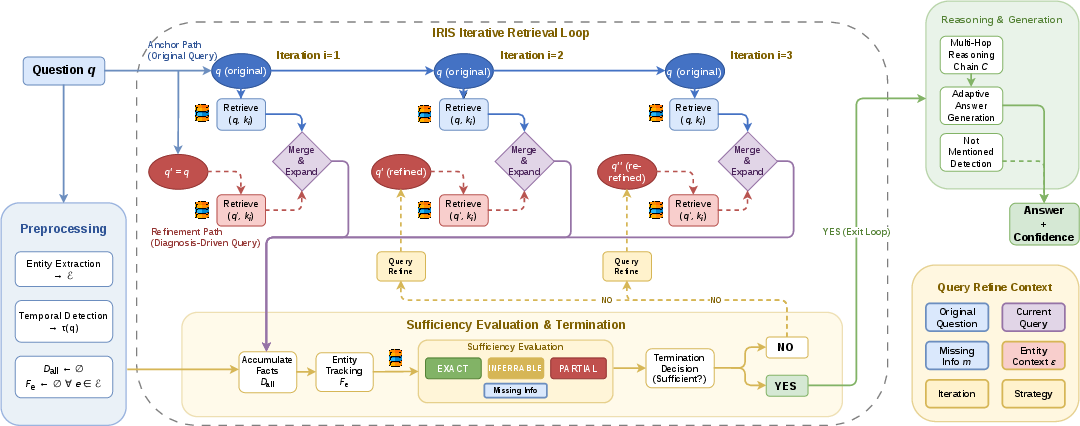
Figure 2: EviMem's IRIS pipeline: iterative dual-path retrieval, sufficiency evaluation, and diagnosis-driven query refinement built on LaceMem memory.
Experimental Validation and Numerical Highlights
Evaluated on LoCoMo, a multi-session conversational memory benchmark, EviMem exhibits robust improvements on complex question categories:
- Temporal reasoning: Judge Accuracy improves from 73.3% (MIRIX) and 58.8% (single-pass) to 81.6%.
- Multi-hop synthesis: Accuracy grows from 65.9% (MIRIX) to 85.2%.
- Overall latency: EviMem operates at 9.54s per question, yielding a 4.5× reduction relative to MIRIX's multi-agent orchestration (42.71s).
These improvements scale with retrieval difficulty: gains are modest for single-hop questions, pronounced for temporal and multi-hop categories with evidence cross-session dispersion. F1 and ROUGE-L scores show substantial lexical recall improvements (+56% vs. MIRIX), confirming that iterative evidence-gap filling enhances answer precision.
Ablation studies isolate the contributions of IRIS and LaceMem:
- Adding tiered sufficiency to the loop prevents premature termination, especially on multi-hop questions (Judge Accuracy rises from 80.1% to 87.3%).
- The Edge layer's graph expansion is indispensable for coherent cross-session evidence assembly (Multi-hop accuracy: 43.2% without Edge, 85.2% with Edge).
- Entity-aware refinement and explicit "not mentioned" detection further enhance performance on adversarial questions.
Independent judge validation demonstrates that EviMem's improvements are robust across LLM backbones and embedding models. Sufficiency classifier precision is 94.6% when committing to the exact tier, with high monotonicity between confidence and oracle sufficiency (ρ=0.93). Diagnosis-driven refinement consistently improves per-iteration retrieval metrics over generic re-query baselines.
Implications and Future Directions
EviMem substantiates that explicit evidence-gap diagnosis, tightly integrated with structured memory hierarchies, is critical for reliable long-term conversational memory in LLM agents. Practically, the system converts retrieval from an open-loop, undirected process to a closed-loop, targeted gap-filling mechanism. This leads to superior accuracy on temporally and relationally complex queries, efficient computation scaling with question difficulty, and minimizes hallucinations via explicit abstention when evidence is insufficient.
Theoretically, the results advocate for explicit sufficiency modeling at the evidence set level, rather than document or passage granularity, paired with memory architectures offering fine-grained, compositional indexing and expansion. Future research is motivated by the need to support online, incremental memory construction for streaming conversational settings and cross-session synchronization.
For AI agents, this trajectory opens avenues for autonomous reasoning over distributed, evolving conversational knowledge—enabling robust memory that is explainable, actionable, and faithful to available evidence.
Conclusion
EviMem's combination of evidence-gap-driven iterative retrieval and layered conversational memory achieves notable improvements in solving long-term, temporally and relationally complex conversational queries. The primary insight is that explicit gap diagnosis and targeted iterative retrieval, grounded in structured memory, are essential for overcoming the limitations of single-pass and implicit-feedback memory systems in LLM-based agents (2604.27695).