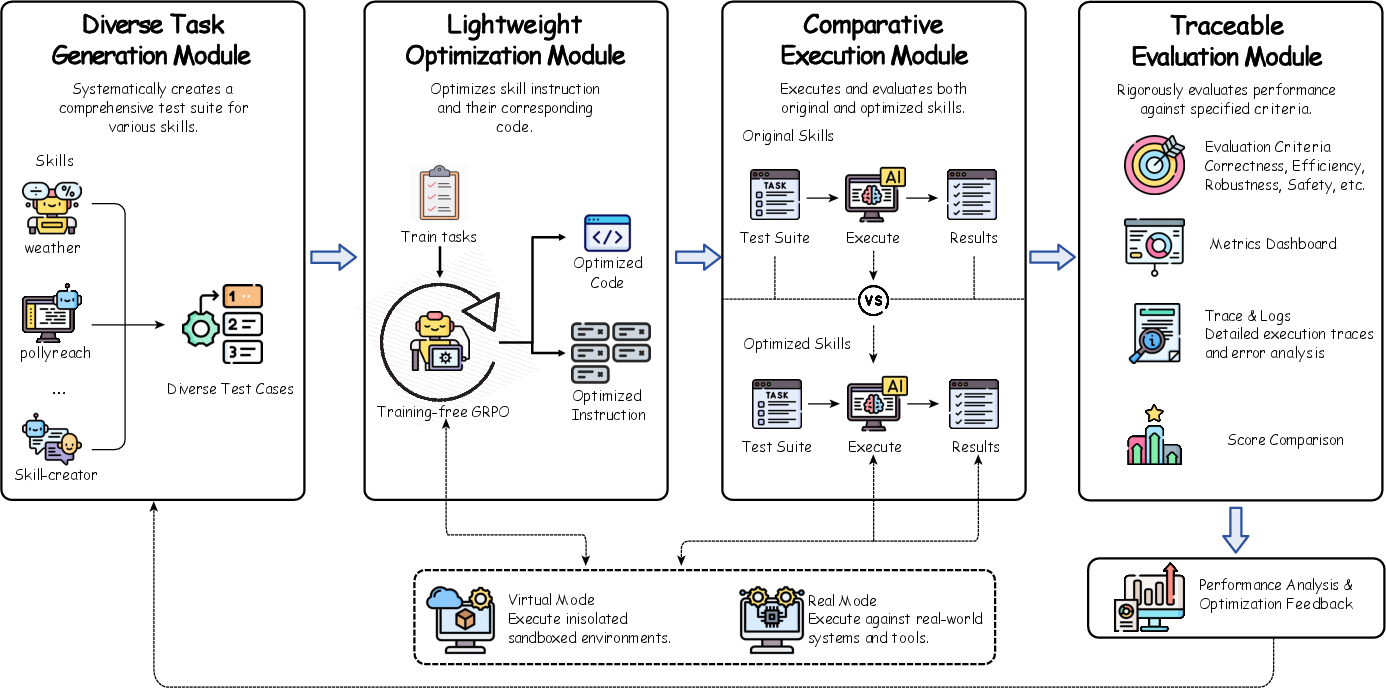
- The paper presents a fully automated framework that leverages Training-Free GRPO to probe, optimize, and evaluate LLM skills without human intervention.
- It integrates diverse task generation, lightweight optimization, comparative execution, and traceable evaluation for systematic skill refinement.
- Empirical results on Skill-X show a dramatic increase in skill score (0.37 to 0.84) and pass rates (+54.43%), highlighting the approach's effectiveness for complex tasks.
Skills-Coach: Automated Skill Optimization via Training-Free GRPO
Context and Motivation
The proliferation of skill-based modular architectures in LLM-driven agents has resulted in a fragmented ecosystem: while tens of thousands of individual skills exist, coverage of complex or specialized functional requirements remains incomplete, with integration bottlenecks impeding scalable deployment. The paper "Skills-Coach: A Self-Evolving Skill Optimizer via Training-Free GRPO" (2604.27488) directly addresses the autonomous self-evolution of skills, formalizing the optimization challenge and proposing a fully automated pipeline to efficiently probe, optimize, and evaluate skill boundaries without human intervention.
Skills-Coach Architecture
Skills-Coach implements a comprehensive modular framework comprised of four synergistic components, each designed for a distinct stage in the skill evolution cycle:
Empirical Evaluation on Skill-X
To benchmark Skills-Coach, the authors created Skill-X, a suite of 48 diverse skills sourced from prominent developer platforms. This dataset encompasses both instruction-only and code-inclusive skill types, supporting robust cross-domain evaluation. The empirical setup involves three optimization epochs per skill, 12 training and 8 test tasks per skill, and stringent execution in real mode with standardized scoring and pass thresholds.
Strong numerical results are reported: average skill score increased from 0.37 to 0.84 post-optimization (127% relative improvement); pass rate rose from 33.59% to 88.02% (+54.43%). Both instruction-only and code-inclusive skill types demonstrated >50% increase in pass rates. Notably, improvements in advanced tasks exceeded those in standard tasks, highlighting the framework’s efficacy for complex, boundary-pushing scenarios.
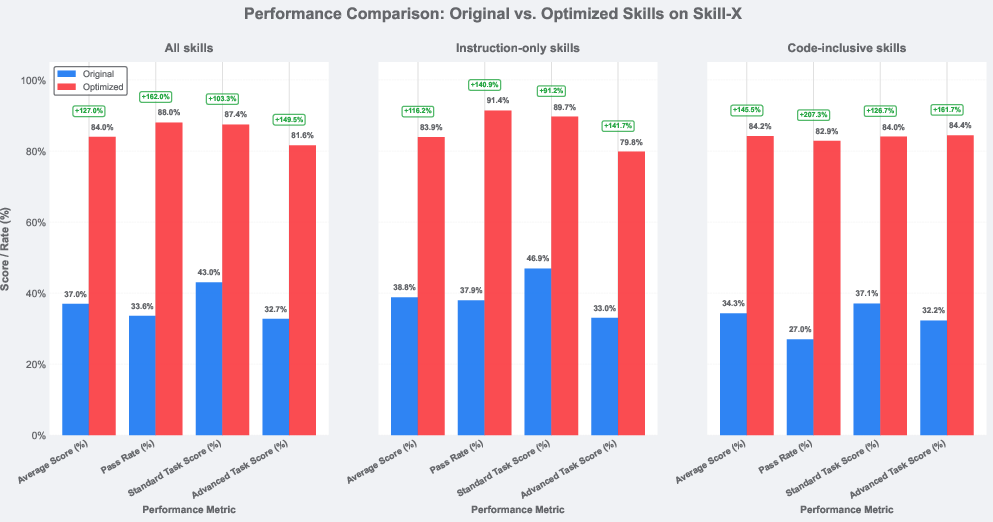
Figure 2: Performance comparison demonstrating substantial gains in skill score and pass rate across Skill-X after Skills-Coach optimization.
Per-Skill Optimization Analysis
Granular analysis reveals that optimization yields maximal benefit for underperforming skills, with 23 skills showing exceptional improvements (+0.5 or greater in score), including several whose scores increased from 0.0 to 1.0 and pass rates from 0%-100%. For skills already at intrinsic optimality, marginal gains become negligible, confirming the necessity to strategically prioritize optimization resources for maximal impact.
Task Generation and Evaluation
The task generation module delivers systematic coverage of standard, advanced, and boundary tasks, with automated criteria ensuring precise and objective evaluation. The assessment of the Pollyreach skill serves as a representative case: basic tasks probe standard command functionality, while advanced tasks demand complex logic and robustness, including format validation and edge-case handling.

Figure 3: Generated standard versus advanced test cases for Pollyreach, capturing progression from functional to robustness evaluation.
Summary reports generated by the evaluation module provide multidimensional analytics, supporting iterative optimization and strategic decision-making for skill retention and further refinement.
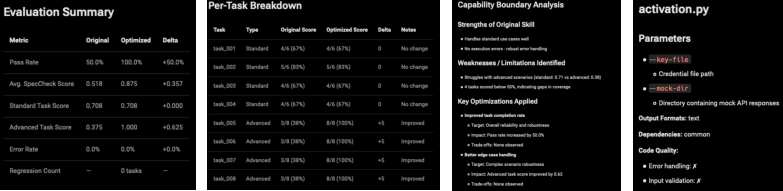
Figure 4: Key contents from the Pollyreach summary report, visualizing metric improvements and capability boundary analysis.
Training-Free GRPO and Optimization Efficiency
The core optimization strategy employs Training-Free GRPO, obviating the need for gradient-based parameter updates and large datasets. This enables rapid optimization—minutes compared to hours—and supports effective iterative refinement with minimal overfitting risk, enhancing both generalization and cross-domain transfer.
Implications and Future Directions
Skills-Coach’s methodology for autonomous skill self-evolution has significant implications for the scalability and robustness of LLM agent deployments. By systematizing the exploration and refinement of capability boundaries, the framework addresses fragmentation in skill ecosystems and reduces dependency on manual maintenance. The substantial empirical gains, especially for complex, code-inclusive skills, are indicative of the power of introspective LLM-driven optimization pipelines. Future developments may focus on hierarchical skill composition, dynamic ecosystem orchestration, and integration with broader agent feedback loops, ultimately advancing the autonomy and reliability of intelligent applications.
Conclusion
Skills-Coach delivers a formalized, modular pipeline for agent skill self-evolution powered by Training-Free GRPO. The framework achieves substantial performance improvements across multiple dimensions of skill capability, particularly for advanced and code-centric tasks. Its fully automated architecture, robust evaluation, and strong empirical validation position it as a key step toward scalable, comprehensive skill ecosystems in LLM-based agents. The research establishes objective guidelines for resource allocation in skill optimization and lays the foundation for further advances in agent skill autonomy and integration.