- The paper introduces SportsTime benchmark with 14,326 QA pairs to evaluate temporally compositional reasoning in sports videos.
- It presents Chain-of-Time Reasoning (CoTR), integrating timestamp-overlay and temporal-reward RL for improved step-wise evidence alignment.
- Experimental results show a +4.0% accuracy gain and high temporal anchoring, addressing current models' limitations in evidence integration.
Introduction
Temporal compositional reasoning in long-form videos presents core challenges for multimodal language and vision models, particularly in dynamic domains such as sports. The paper "Towards Temporal Compositional Reasoning in Long-Form Sports Videos" (2604.22226) addresses key limitations in existing Multimodal LLMs (MLLMs) by introducing SportsTime, a large-scale, open-ended QA benchmark with temporally grounded reasoning annotations, and Chain-of-Time Reasoning (CoTR), a method explicitly tailored for step-wise temporal evidence integration. The work advances the systematic evaluation and modeling of long-horizon, evidence-grounded reasoning by enabling both fine-grained process supervision and robust model optimization.
SportsTime Benchmark: Construction and Properties
The SportsTime benchmark is constructed as a long-form, multi-sport dataset supporting open-ended, compositional QA with explicit temporal evidence chains.
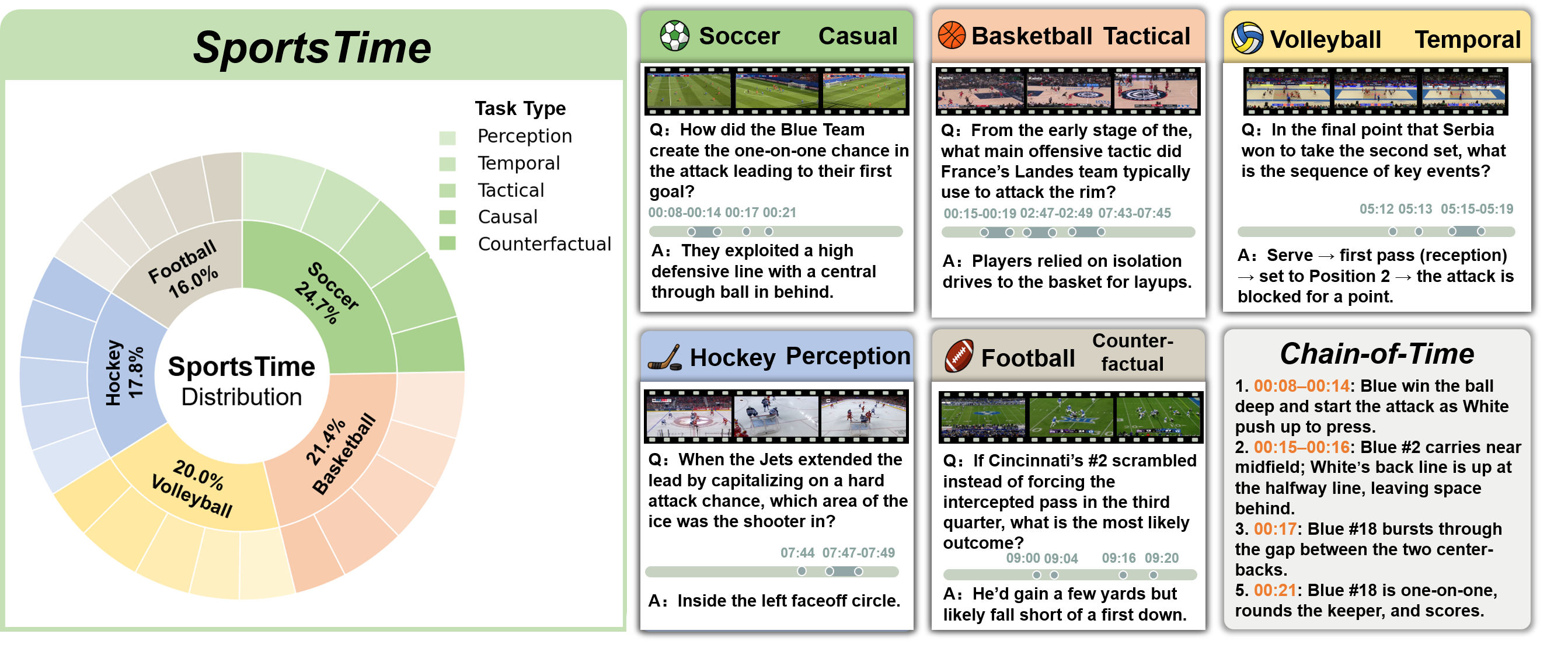
Figure 1: Overview of the SportsTime benchmark covering five sports and five reasoning types, with Chain-of-Time examples.
The data set comprises 14,326 QA pairs and over 50,000 annotated evidence steps, covering diverse sports (soccer, basketball, American football, ice hockey, volleyball), variable video durations (10-minute highlights and 50-minute full games), and multiple task categories (perception, temporal, tactical, causal, counterfactual). Each QA sample is associated with a reasoning step chain, with each step grounded to an annotated timestamp or span. This structure supports rigorous fine-grained evaluation and model supervision.
The annotation pipeline is semi-automatic, leveraging expert-curated templates and LLM-assisted candidate generation, followed by dual-stage human review for temporal precision and sports-domain fidelity.
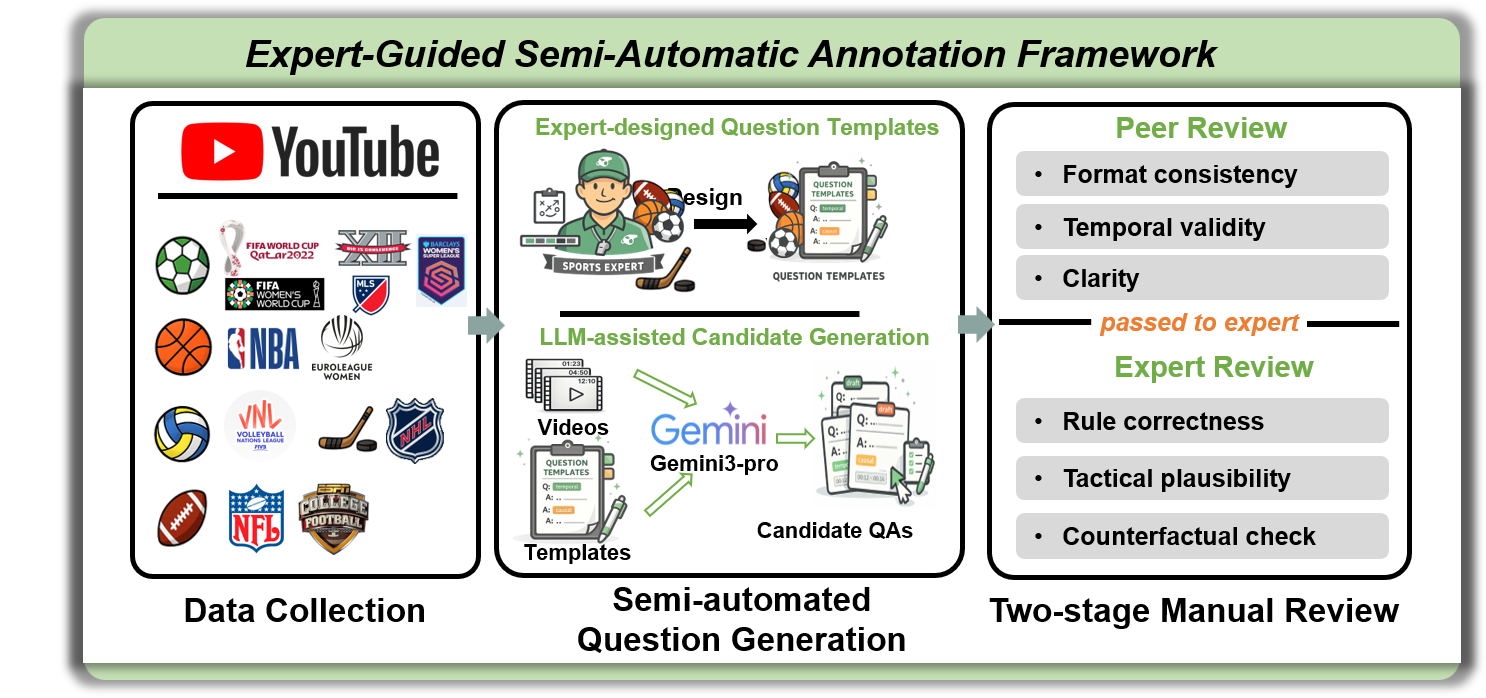
Figure 2: Overview of our expert-guided semi-automatic annotation pipeline for temporally grounded SportsTime QA pairs.
SportsTime surpasses prior benchmarks by targeting multi-event, long-horizon reasoning and providing step-aligned temporal supervision, enabling explicit verification of model reasoning at each inference stage.
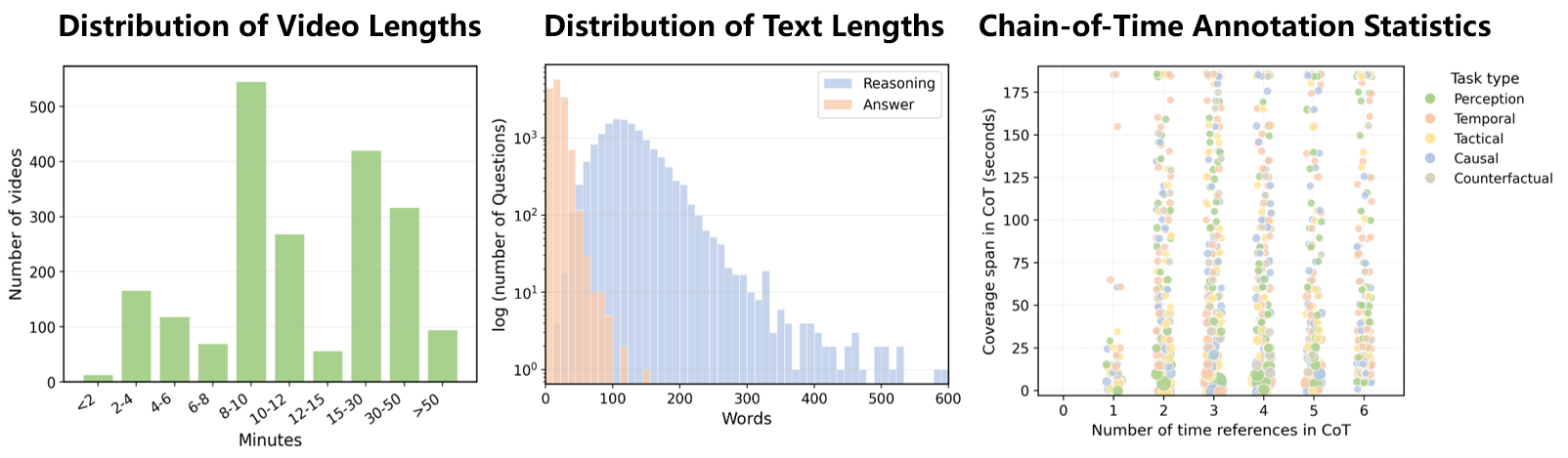
Figure 3: Summary of SportsTime statistics: video lengths, word counts in reasoning chains and answers, and temporal evidence chain properties.
Chain-of-Time Reasoning: Framework and Optimization
CoTR is a modular approach for long-form video reasoning with a focus on explicit, verifiable, and compositional temporal grounding.
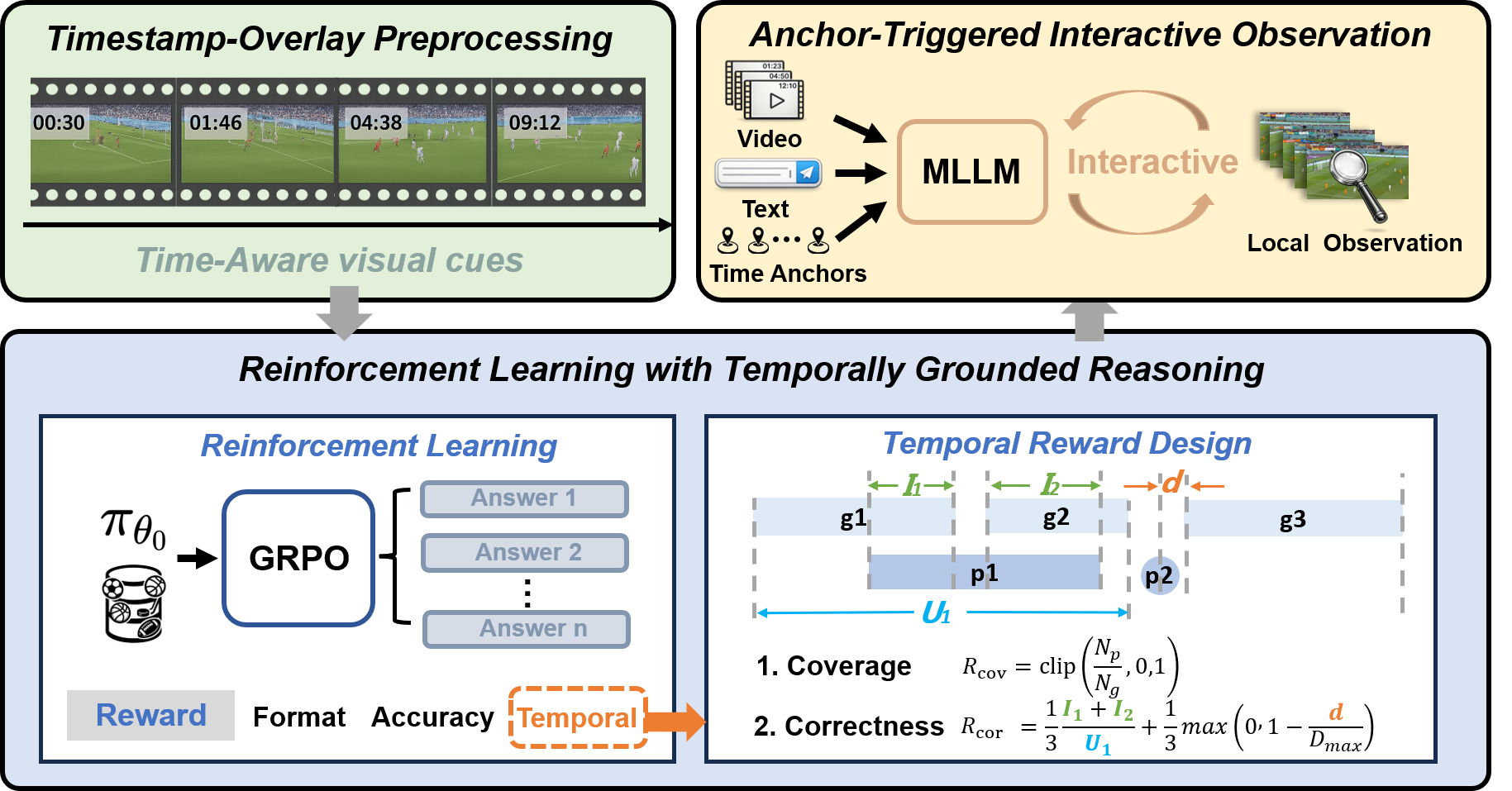
Figure 4: Overview of the Chain-of-Time Reasoning Framework, incorporating temporally grounded evidence composition.
Key architectural properties:
- Timestamp-overlay preprocessing: During training, explicit mm:ss timestamps are burned into video frames to transform temporal reference detection into a direct visual/text OCR problem, significantly increasing the fidelity of temporal anchoring.
- Step-wise temporal annotation: Each reasoning step is mapped to either a precise temporal point or span, facilitating iterative, evidence-guided decoding.
- Temporal-reward reinforcement learning (tr-GRPO): CoTR optimizes the backbone policy using Group Relative Policy Optimization, with reward signals formulated from both answer correctness and temporal anchor alignment. Separate terms encourage both step coverage (maximizing temporal anchor presence per step) and anchor accuracy (using IoU/distance metrics).
- Anchor-observe-infer inference: At test time, predicted temporal anchors are used to retrieve short, local video clips; intermediate claims are iteratively verified and revised with respect to retrieved evidence, rather than relying on global scene aggregation or language priors. This mechanism heightens step-wise grounding and reduces the risk of temporal or compositional hallucination.
Experimental Results and Analysis
The baseline evaluation with current state-of-the-art MLLMs on SportsTime reveals substantial performance gaps: top commercial models (GPT-5, Gemini-2.5-Pro) achieve at most 40.72% average accuracy, with open-source variants trailing further behind. Both proprietary and open-source models exhibit chronic underperformance on questions requiring evidence integration over long, sparse event horizons.
CoTR provides consistent, significant improvements over strong open-source MLLMs, with more than +4.0% average accuracy gain and notably higher scores on tactical (+3.45%), causal (+3.20%), and counterfactual (+6.04%) tasks.
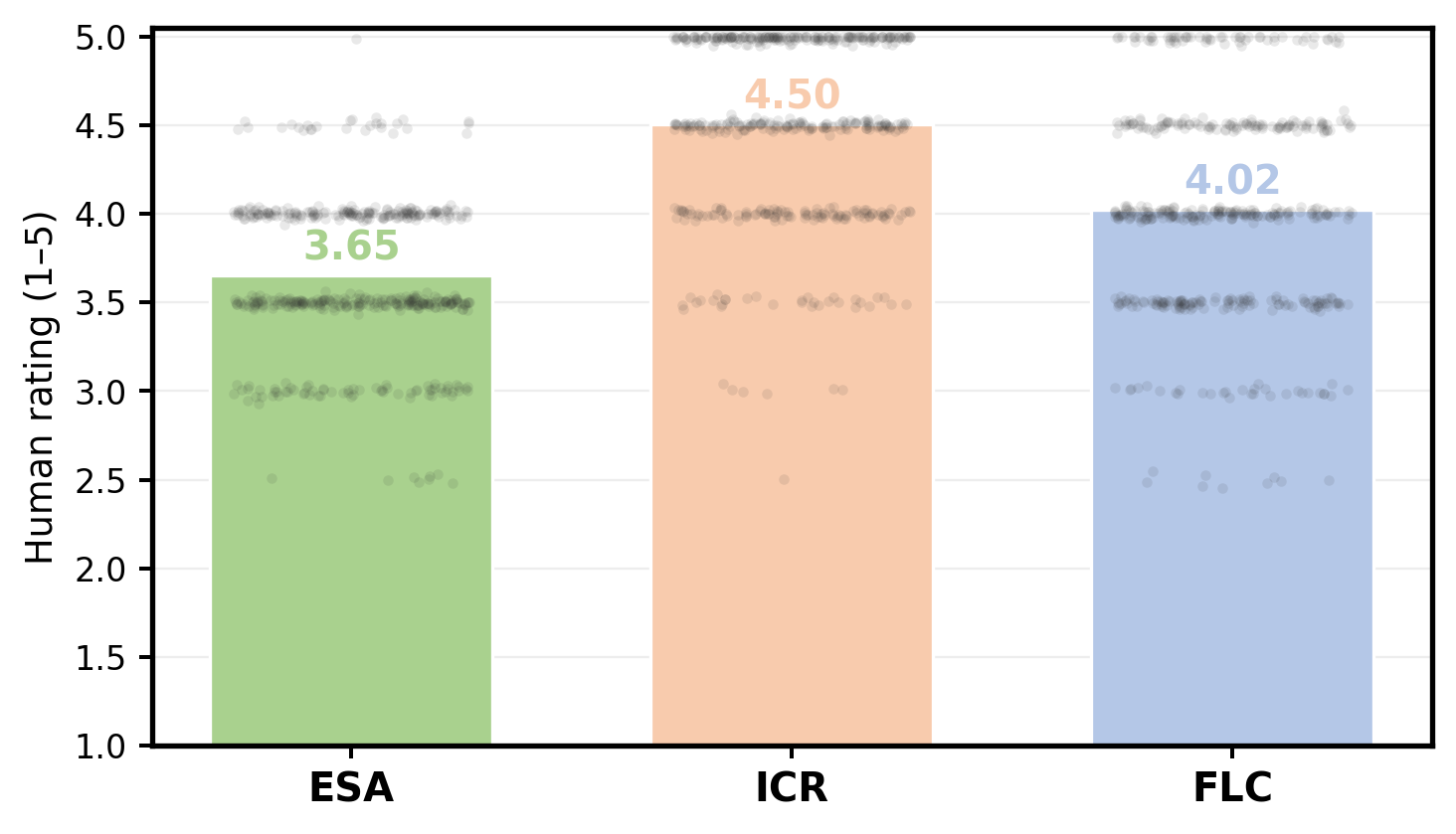
Figure 5: Comparative analysis of answer accuracy and temporal evidence quality under differing optimization regimes.
The SGA evaluation demonstrates that, compared to control methods (zero-shot, prompt-based, or SFT/RL without temporal reward), tr-GRPO and anchor-observe-infer increase not only answer accuracy, but also the proportion of steps containing explicit evidence (95.76%) and the alignment quality of temporal anchors (mIoU 0.78, [email protected] 56.89%). The improvement is corroborated by human raters, who report high faithfulness and logical consistency scores for generated chains.
A series of ablations confirm that each system component — timestamp-overlays, temporal-reward RL, and anchor-based interactive evidence retrieval — are individually necessary for optimal overall and temporal grounding performance. Simply increasing frame budgets or video length does not bridge the compositional temporal reasoning gap.
Broader Implications and Future Directions
The explicit chain-of-time approach concretely surfaces two central limitations in current long-video model architectures:
- Language- and prior-driven shortcuts dominate without step-wise evidence supervision, resulting in severe temporal hallucinations and misgrounded assertions, particularly in low-signal/high-noise video segments typical in real sports games.
- Temporal compositional reasoning benefits disproportionately from architectural integration of step-wise anchor alignment and iterative evidence search, as opposed to single-shot or loosely-supervised answer generation.
Practically, SportsTime and CoTR enable more robust, auditable systems in professional sports analytics by supporting verifiable decision traces for tasks such as tactical breakdown, counterfactual scenario generation, and complex event detection. Theoretically, the work demands that subsequent model designs more tightly couple temporal signal extraction and compositional inference, potentially by custom visual-LLM bridges that connect time, space, and language (cf. recent proposals such as VideoAgent and LongVT).
The explicit chain-of-time modeling paradigm and the SportsTime benchmark can generalize to adjacent domains (medicine, surveillance, robotics) where temporally sparse but critical events drive downstream tasks.
Conclusion
"Towards Temporal Compositional Reasoning in Long-Form Sports Videos" establishes SportsTime as the new standard for benchmarking verifiable temporal reasoning in realistic, open-ended sports settings and introduces Chain-of-Time Reasoning as an effective optimization and inference protocol for explicit, reliable, and compositional evidence alignment. These advances anchor the next phase of research on long-horizon, multi-event video understanding.

