- The paper introduces a unified diffusion Transformer with dynamic token injection to align speech, music, and sound effects from text instructions.
- It employs a multi-stage curriculum learning strategy that achieves state-of-the-art performance in TTS and TTM while delivering competitive TTA results.
- Joint multi-modal training enhances cross-domain generalization, simplifying deployment across diverse audio generation applications.
UniSonate: Unified Instruction-Based Generation of Speech, Music, and Sound Effects
Introduction and Motivation
The landscape of generative audio modeling has long been defined by strict task boundaries: text-to-speech (TTS), text-to-music (TTM), and text-to-audio (TTA) each rely on distinct control paradigms and model architectures. These constraints hinder the development of a single, general-purpose audio generation model that can operate from natural language instructions across speech, music, and unstructured sound effects. UniSonate (2604.22209) addresses this gap with a unified probabilistic framework employing a conditional flow-matching Multimodal Diffusion Transformer (MM-DiT), enabling reference-free, high-fidelity generation of all three modalities using only text-based instructions.
Unified Architecture and Dynamic Token Injection
At the architectural core of UniSonate is the dual-stream MM-DiT, combining a semantic text stream (instructions and content sequences) with an audio latent stream (Mel-VAE compressed acoustic representations). The critical innovation lies in the Instruction-Content Alignment paradigm and the introduction of dynamic token injection.
- Instruction-Content Alignment: Speech and music, inherently structured, leverage discrete content tokens (phonemes/notes) paired with natural language instructions. In contrast, sound effects, lacking structure, receive a string of learnable [SFX] tokens. The number of these tokens is dynamically set to represent temporal extent, effectively projecting unstructured SFX into a pseudo-linguistic sequence.
- Joint Attention Layers: The MM-DiT fuses semantic and acoustic modalities via cross-attention, enabling global style and fine-grained structural control within a single model.
- Acoustic Representation: All audio forms are encoded to a continuous latent space using a Mel-VAE at a 44.1kHz sampling rate for generative consistency and efficiency.
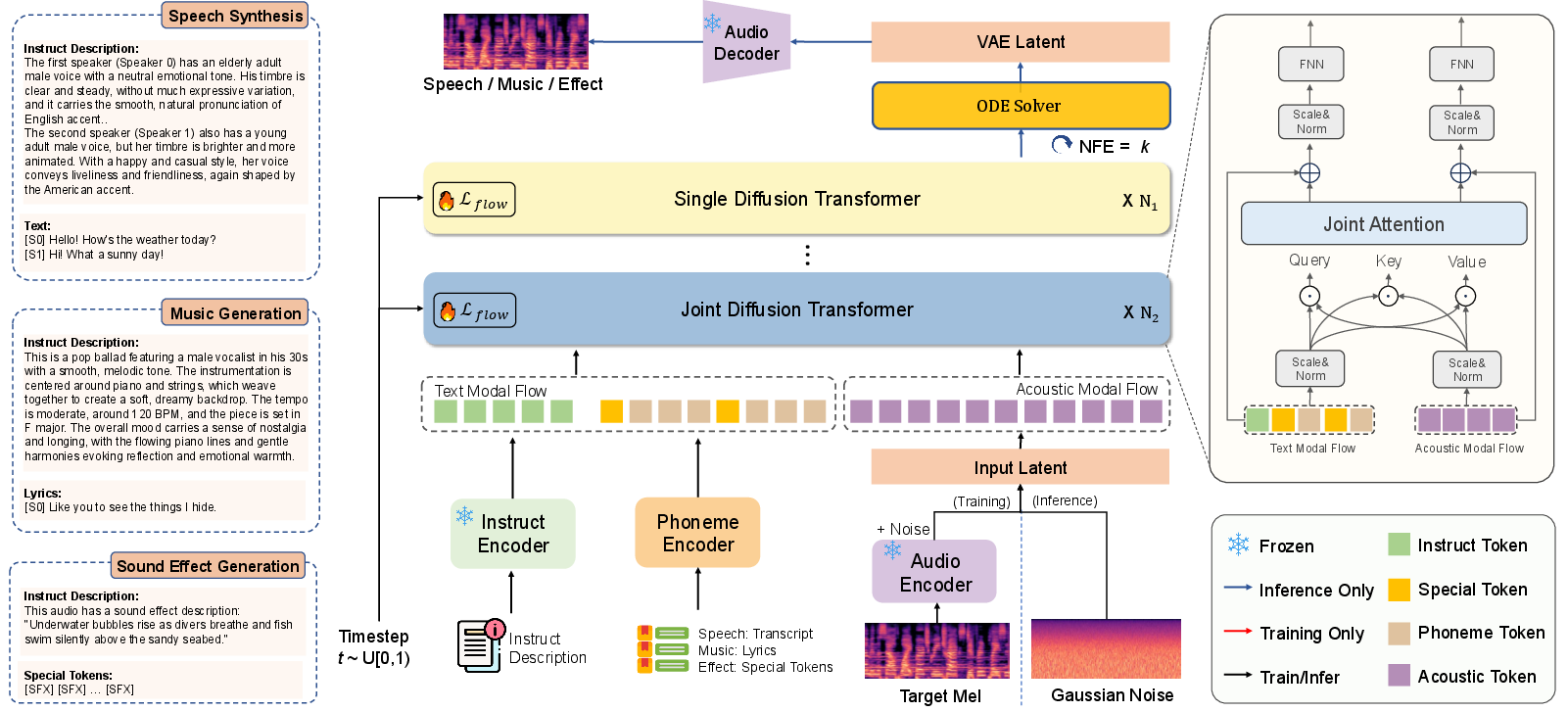
Figure 1: The overall architecture of UniSonate, showing dual-stream diffusion, dynamic token injection, and modality-agnostic instruction-content alignment.
Dynamic token injection ensures architectural homogeneity across modalities. For TTS and TTM, content tokens enable monotonic alignment (phoneme-to-audio); for SFX, repeated [SFX] tokens form a temporal anchor, allowing step-wise progression via attention mechanisms without modifying downstream layers or requiring modality-dependent processing.
Multi-Stage Curriculum Learning and Optimization Stability
Unifying highly structured modalities (TTS, TTM) with unstructured SFX introduces significant optimization conflicts. UniSonate overcomes this by multi-stage curriculum learning:
- Stage 1 focuses exclusively on speech, anchoring the model in precise, temporally-aligned articulation.
- Stage 2 introduces music, leveraging semi-structured alignment and expanding long-range temporal modeling.
- Stage 3 incorporates SFX, exposing the MM-DiT to unstructured environmental audio.
This staged approach prevents catastrophic forgetting and negative cross-modal transfer, typical pitfalls when naively mixing data with divergent structural statistics.
Result Highlights and Comparative Analysis
Capability coverage and generalization: UniSonate is the first model to demonstrate state-of-the-art instruction-based performance in both TTS and TTM while simultaneously maintaining competitive fidelity in TTA—a strong claim substantiated by quantitative evaluation.
- TTS: 1.47% English and 1.25% Chinese WER, surpassing dedicated baselines (e.g., F5-TTS, CosyVoice2).
- TTM: SongEval structural coherence of 3.18 (outperforming InstructAudio), highest Musicality MOS (3.01).
- TTA: FAD of 4.21, on par with specialized models like AudioLDM-L and Stable Audio in generating diverse sound effects.
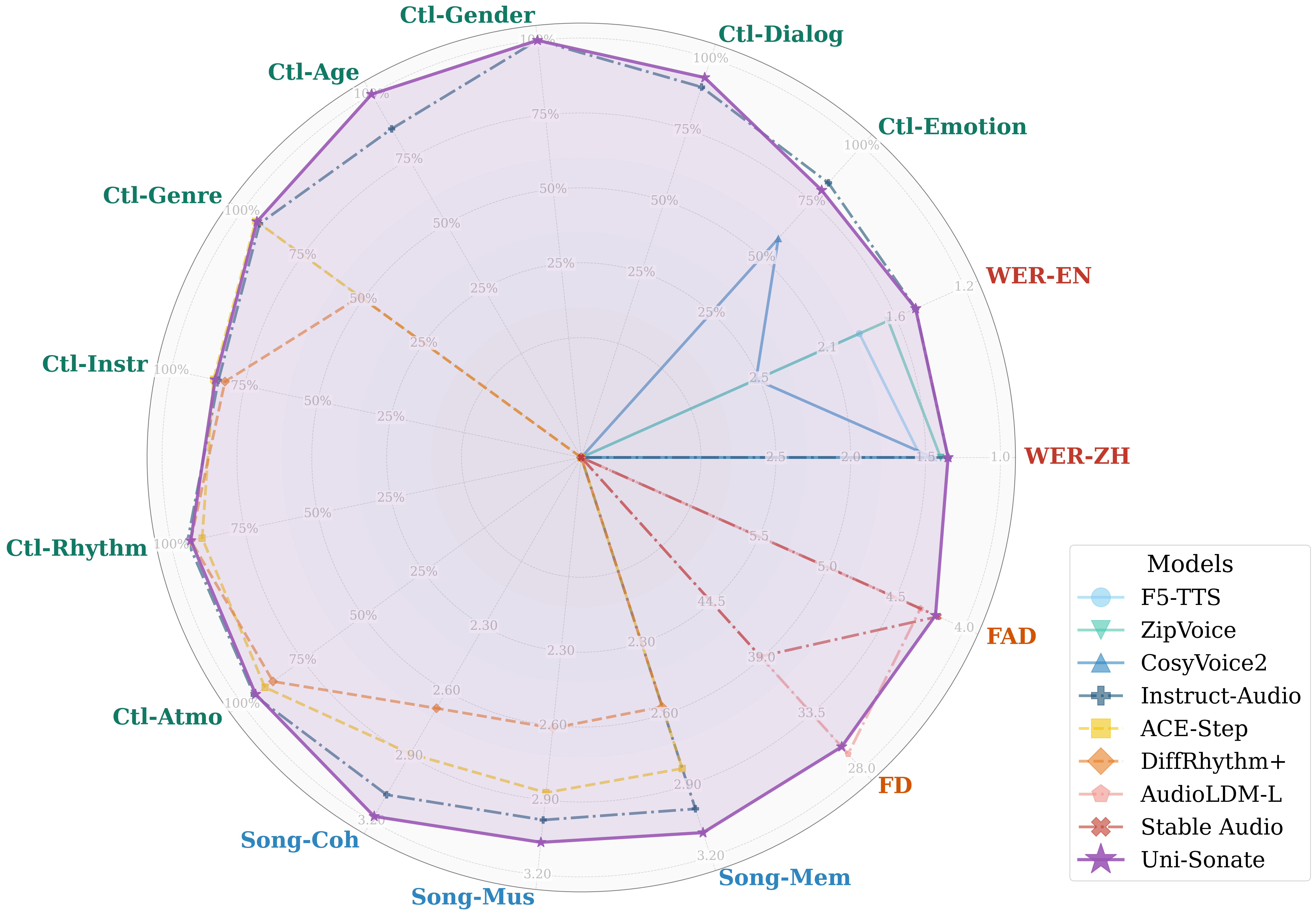
Figure 2: Holistic evaluation establishing UniSonate's superior cross-modal capability, with strong instruction-following and coherence in speech/music, and credible performance on unstructured sound effects.
Positive transfer analysis: Ablation studies reveal that joint multi-domain training enhances both speech intelligibility (WER reduction from 2.24% to 1.47%) and music structural attributes (SongEval Cohesion increase from 3.11 to 3.18) compared to single-task variants. Exposure to a broad acoustic modality spectrum improves the internal representations learned by the shared encoder, enabling robust generalization and prosodic flexibility.
Implications and Theoretical Significance
From a practical perspective, UniSonate enables pipeline simplification: content creators, virtual assistants, and generative audio frameworks can leverage a unified API for TTS, TTM, and SFX, eliminating the need for task-specific models or data formatting. Reference-free operation with text-only instructions streamlines deployment in dialogue-over-music, soundscape synthesis, and autonomous content creation scenarios.
Theoretically, UniSonate demonstrates the feasibility of joint latent sequence modeling for structured and unstructured audio generation with minimal architectural branching. The dynamic projection of unstructured events into sequence space may inspire analogous approaches in multimodal generative modeling (e.g., video, audio-visual sync), where structural disparities impede unification.
Limitations and Future Directions
Despite strong performance, the model exposes limitations:
- SFX gap: UniSonate's FAD lags behind SOTA dedicated SFX models, indicative of a trade-off between unity and specialization in highly unstructured domains.
- Long-form coherence: Context windows (2–20s) limit the maintenance of narrative and musical consistency in long-form synthesis.
- Instruction ambiguity: Text-only instructions induce one-to-many mapping ambiguity in generation, occasionally sacrificing user-intended specificity.
- Inference cost: Flow-matching diffusion sampling requires multiple denoising steps, contributing to high computational load.
Addressing these will likely involve hierarchical modeling for long-context synthesis, specialized architecture branching for complex SFX diversity, and the integration of user feedback or preference modeling for enhanced instruction disambiguation. Advances in efficient diffusion sampling and model quantization are also critical for real-time application.
Conclusion
UniSonate (2604.22209) sets a new standard for unified audio generation, achieving instruction-driven synthesis of speech, music, and sound effects within a coherent, reference-free framework. Through dynamic token injection, staged curriculum learning, and multimodal diffusion, it demonstrates strong cross-modal generalization, positive transfer, and competitive task-specific performance. The approach will likely inform future work on foundational multimodal generative models and complex contextual audio synthesis.

