- The paper introduces AnchorMem, a novel LLM memory framework that decouples retrieval from generation by anchoring atomic facts to immutable contexts.
- It demonstrates high performance with up to 50.57% F1 score and a 1.6× speedup over rewriting-based methods, improving long-context and multi-turn interactions.
- The approach preserves detailed contextual integrity, reducing semantic dilution and computational costs while enhancing multi-hop reasoning through associative event graphs.
AnchorMem: Anchored Facts with Associative Contexts for LLM Memory Systems
Motivation and Background
Long-context performance and enduring consistency in LLMs remain fundamentally constrained by their stateless architecture and limited window size. While context window scaling and retrieval-augmented approaches have become standard, these methods incur prohibitive computational costs and remain susceptible to the “Lost-in-the-Middle” phenomenon, which degrades retrieval performance in long-term, multi-turn interactions. Conventional generative memory frameworks—such as A-Mem and Mem0—coordinate LLM-driven “retrieve-and-rewrite” strategies to maintain a tractable historical trace. However, frequent rewriting leads to semantic dilution of contextual details (Figure 1), and graph-based entity indexing introduces retrieval noise due to semantically generic connections.
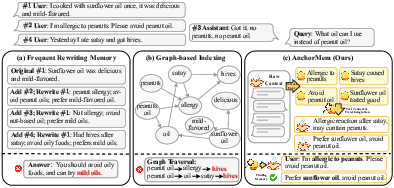
Figure 1: Comparison of memory paradigms, highlighting the contextual blurring from rewriting, noisy graph traversal, and contextual integrity preserved by AnchorMem.
Recent cognitive theory, specifically the involuntary autobiographical memory (IAM) and the Proust Phenomenon, posits that precise cues can holistically reactivate entire episodic histories. Existing LLM memory systems have yet to operationalize this hypothesis at scale, consistently optimizing either for fine-grained retrieval at the cost of context or for broad context with imprecise retrieval.
AnchorMem Framework
AnchorMem is an LLM memory mechanism designed to decouple retrieval from generation by separating atomic fact anchors from the immutable generation context. Its key components are:
- Fact-Context Construction: Each dialog interaction is retained as an immutable context. Simultaneously, atomic facts are extracted via LLM prompting, producing concise, unambiguous indices for retrieval, each surjectively mapped to their raw source context.
- Associative Event Graph (AEG): Beyond atomic anchoring, the framework aggregates semantically associated facts into event clusters. This is accomplished by embedding and clustering facts, integrating them into higher-level event representations using LLM-driven fusion prompts. The AEG encodes n-ary associations, supports pruning and avoids spurious pairwise paths endemic to entity-based graphs.
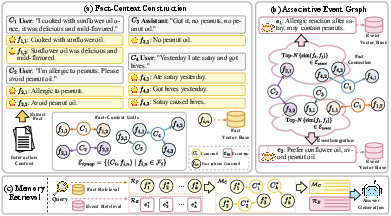
Figure 2: Overview of the AnchorMem framework, illustrating fact-context construction, associative event integration, and the retrieval mechanism.
- Retrieval and Reconstruction: Upon query, AnchorMem performs vector-similarity search against atomic facts and event nodes. Retrievals are mapped through the associative graph to restore the immutable narrative segments, recapturing contextual nuance and enabling composite event coverage in response generation.
Experimental Results
Evaluation was conducted on the LoCoMo benchmark—a corpus designed to stress multi-turn, long-context memory over thousands of tokens and hundreds of turns. AnchorMem was compared against baselines including Naive RAG, HippoRAG 2, Mem0, A-Mem, MemoryOS, and LightMem, with multiple LLM backbones ranging from Qwen2.5-7B-Instruct and 32B-Instruct to GPT-4o-mini.
AnchorMem achieved:
- Best mean F1 on GPT-4o-mini: 49.87% (vs. Mem0∗ at 45.10% and LightMem at 41.71%)
- Best mean F1 on Qwen2.5-32B-Instruct: 50.57% (vs. LightMem at 38.24%)
- Significant accuracy improvements in all task categories, with especially robust performance in Single Hop and Temporal tasks.
- By eschewing rewriting, AnchorMem maintained the fastest end-to-end memory construction performance, with a 1.6× speedup compared to LightMem and large-scale reductions in API call counts and token costs (Table 1).
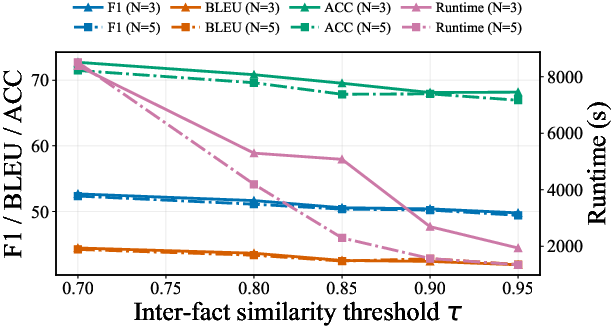
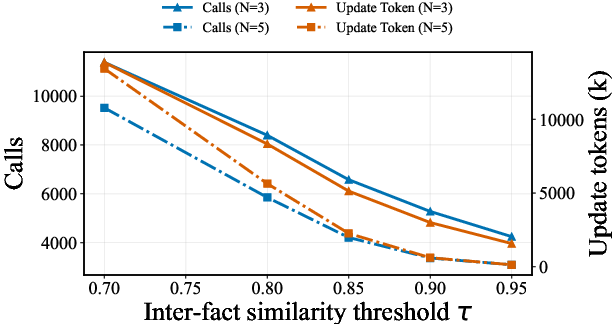
Figure 3: Performance and runtime profiles, demonstrating AnchorMem's efficiency-performance trade-off.
Ablation and Analysis
Ablation analysis underscored the critical role of the immutable context for maintaining answer fidelity; stripping the context collapses accuracy to 30.52%. Removal of the AEG especially hindered multi-hop reasoning, confirming the importance of cross-fact event integration for complex queries. Systematic hyperparameter sweeps on similarity thresholds and neighbor counts revealed computational–semantic trade-offs: denser fact-event associativity increases accuracy at the expense of token and runtime costs, with aggressive redundancy pruning preventing memory bloat as dialog histories scale.
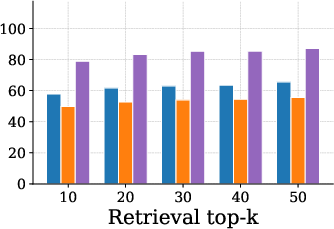
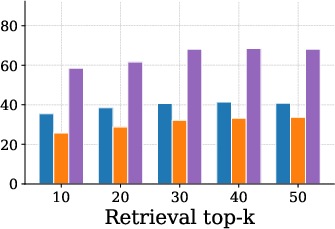
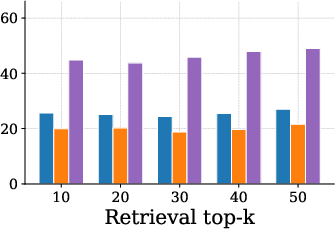
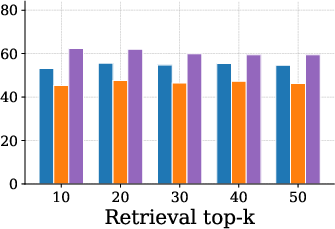
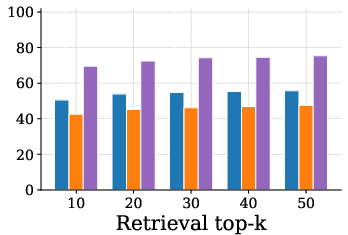
Figure 4: Single Hop task accuracy trend, showing AnchorMem's scaling benefit with increasing retrieval top-k.
Practical and Theoretical Implications
Practically, AnchorMem enables scalable, high-fidelity persistent memory for stateless LLMs, supporting applications in AI agents, conversational assistants, and any long-running system requiring sessional or non-parametric continual adaptation. By grounding retrieval in atomic facts while retaining the original linguistic context, the method mitigates both the computational and semantic drift endemic to rewrite-based or entity-centric architectures. The framework’s modular design supports future extensions with more robust fact extraction, alternate clustering signals, and iterative event graph refinement.
Theoretically, AnchorMem advances the alignment of LLM memory models with cognitive principles underlying episodic recollection and autobiographical indexing, potentially serving as a scalable paradigm for memory systems harmonizing fine-grained access and long-range compositionality.
Conclusion
AnchorMem demonstrates that decoupling retrieval anchoring from generation context—via atomic facts and associative event graphs—yields both numerically strong and computationally efficient memory for LLMs. The system outperforms rewriting and entity-graph baselines on long-context benchmarks and provides a trajectory for cognitively inspired, scalable persistent memory in future foundation models. Further research should target improved anchor reliability, more dynamic event integration, and adaptive mechanisms for semantic drift correction during ongoing interaction.
Reference: "AnchorMem: Anchored Facts with Associative Contexts for Building Memory in LLMs" (2604.17377)

