- The paper introduces a self-play framework where agents generate semantically equivalent/inequivalent Haskell programs verified via Liquid Haskell.
- The method employs adversarial training with SEQ and SINQ tasks, yielding significant Pass@1 improvements on HumanEval and MBPP benchmarks.
- The approach enhances semantic reasoning transferable to EquiBench and cross-domain code analysis while highlighting challenges in proof synthesis.
Introduction and Problem Setting
"Improving LLM Code Reasoning via Semantic Equivalence Self-Play with Formal Verification" (2604.17010) presents a semantic self-play framework tailored to address major limitations in LLM-based code generation: the inability to robustly reason about program equivalence, especially when test suites are insufficient or do not capture semantic subtleties. The authors target Haskell as a substrate due to its purity, expressive type system, and the presence of tools like Liquid Haskell, which enable SMT-backed, machine-checkable equivalence proofs for non-trivial functional programs. The core of their approach is an adversarial game between two agents, Alice (generator) and Bob (evaluator), thereby establishing a curriculum in which model capabilities are pushed to higher semantic abstraction through verified SEQ (equivalence) and SINQ (inequivalence) instances.
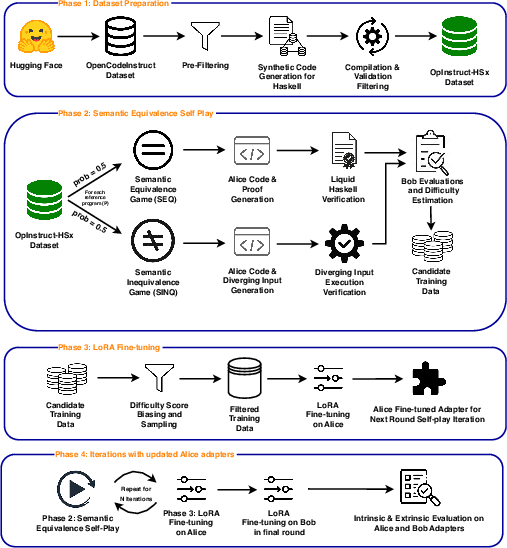
Figure 1: Overview of the semantic self-play framework for improving code reasoning in LLMs via Haskell.
The self-play design enforces a rigorous, proof-driven loop where equivalence and inequivalence—rather than superficial syntactic differences or unit test outcomes—are the goal of training. The framework leverages synthetic data augmentation and formal verification to create high-signal, low-noise supervision at scale, a marked improvement over noisy web-mined and testset-driven approaches.
Dataset Curation: OpInstruct-HSx
A critical bottleneck for code reasoning research in non-mainstream languages is the lack of high-quality, validated data. The authors introduce OpInstruct-HSx, a ≈28k-sample dataset of strictly validated and executable Haskell programs, synthesized via LLM-based translation and multi-stage filtering from large-scale Python sources. The pipeline ensures GHC-compilability, type-correct input synthesis, and runtime viability—uncommon characteristics for existing datasets.

Figure 2: Full Pipeline for the OpInstruct-HSx dataset generation.
This resource enables controlled experiments both in synthetic (SEQ/SINQ) game setups and transfer to downstream benchmarks, cementing its value for LLM training and evaluation targeting semantic reasoning and program analysis.
Self-Play Mechanism and Fine-Tuning Strategy
The framework operates with two central tasks:
- SEQ (Semantic Equivalence): Given program P, Alice must generate variant Q and a valid Liquid Haskell proof π such that ∀x,P(x)=Q(x), maximizing instance difficulty.
- SINQ (Semantic Inequivalence): Alice produces Q and an explicit input where outputs diverge, directly providing a counterexample.
Both SEQ and SINQ branches enforce strong correctness via formal verification or execution, respectively. All generated (P,Q) pairs undergo dual vetting: successful proof (for SEQ) or counterexample execution (for SINQ). Difficulty calibration is implemented by having Bob evaluate instances, with retention favored for high-difficulty, misclassified cases. The training loops for both agents incorporate supervised fine-tuning (SFT), emphasizing rejection sampling and curriculum bias toward more challenging examples. This is deployed across several SEQ/SINQ regime combinations to disentangle the effects of data quantity, diversity, and proof-driven supervision.
Experimental Results and Evaluation
Intrinsic Training Dynamics
Difficulty statistics show that the adversarial loop effectively increases challenge level over self-play rounds. Alice consistently synthesizes harder program variants for Bob, as evidenced by the increase in average and upper-quartile difficulty scores.
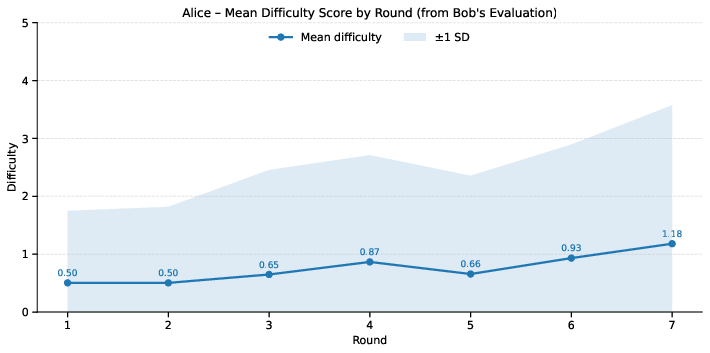
Figure 3: Mean and standard deviation for the difficulty scores for Alice's generated instances from a fixed untrained Bob over 7 rounds.
HumanEval and MBPP Transfer
Training yields substantial improvement in Haskell code generation and robustness, with both agents displaying increased Pass@1 and a notable reduction in compilation errors on HumanEval and MBPP.
- Bob, HumanEval: +8.7pp Pass@1 (17.7%→26.4%)
- Alice, MBPP: +7.6pp Pass@1 (26.7%→34.3%)
This demonstrates successful transfer of equivalence-trained representations beyond the self-play data distribution to realistic downstream code synthesis settings.
EquiBench Benchmark
Semantic discrimination skills acquired through Haskell SEQ/SINQ transfer most strongly to EquiBench's variable renaming (OJ_V) and algorithmic refactoring (OJ_A) subsets, supporting the claim that equivalence reasoning and abstraction improve general program understanding.
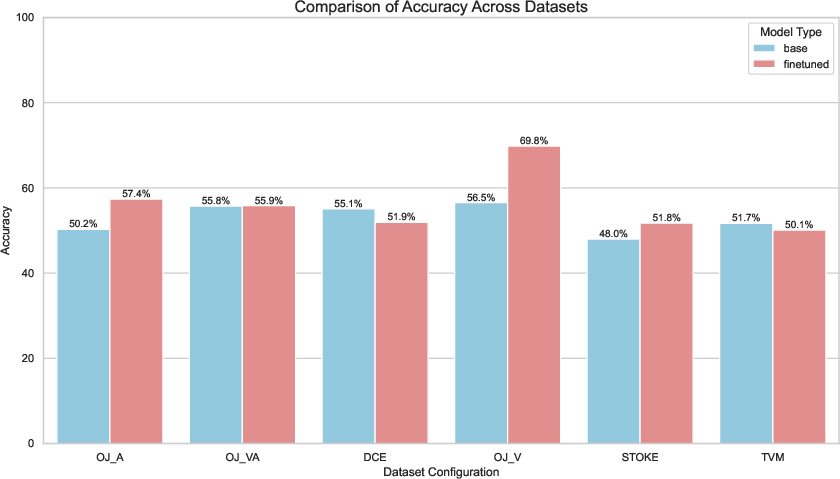
Figure 4: Accuracy comparison between base and fine-tuned Bob models across EquiBench dataset configurations.
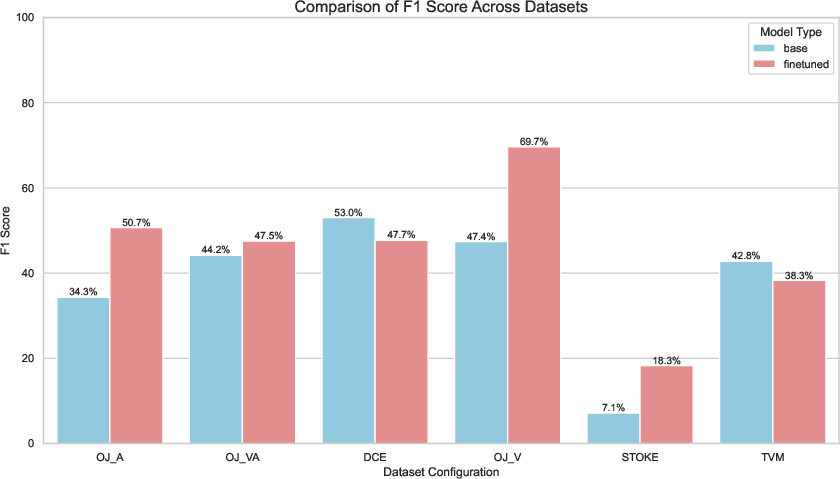
Figure 5: F1 score comparison between base and fine-tuned Bob models across EquiBench dataset configurations.
Low-level equivalence tasks (DCE, STOKE, TVM) do not see similar gains, illustrating the boundary set by the high-level, functional, and type-safe focus of Haskell and the verification pipeline.
Cross-domain Code Analysis
Fine-tuned Bob shows consistent accuracy/recall/F1 improvement on PySecDB security commit discrimination (Python), underlining that the skills gained are not narrowly overfit to Haskell syntax but correspond to deeper semantic representations. Conversely, on low-level C (CodeXGLUE), Bob's performance remains at chance, consistent with the limitations of the framework.
Supervision Type Ablation
Ablation across SEQ- and SINQ-only regimes demonstrates a unique contribution of equivalence (proof-based) supervision—even with far fewer training samples, models with SEQ training outperform samples trained only on counterexample-driven SINQ. Strictly counterexample-based training cannot substitute the high-level abstraction skill conferred by proof supervision.
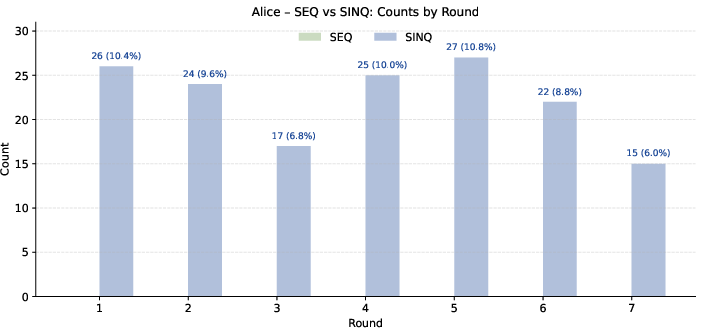
Figure 6: Counts and proportions of validated Alice generations by round.
Limitations
The framework's main limitation is the proof synthesis bottleneck. The relatively weak generative model struggles to produce valid Liquid Haskell proofs at scale, meaning that training data is overwhelmingly SINQ-dominated and the number of SEQ instances is drastically limited. This restricts the upper bound for semantic reasoning achievable by Bob and highlights the dependency on model capacity and advances in automated theorem proving. Furthermore, the structural constraints of Haskell and Liquid Haskell limit coverage—non-terminating constructs, partials, or behaviors requiring deep algebraic rewriting are generally out of reach.
Implications and Future Directions
The results show that self-play with formal equivalence supervision can drive robust symbolic reasoning and generalization in LLMs—a path distinct from test coverage, and more conducive to reliable program synthesis, optimization, refactoring, and vulnerability analysis. In the near term, this suggests that verification-augmented adversarial fine-tuning can serve as a strong regularizer for LLMs, especially in high-trust settings (e.g., safety, cryptography, critical code). Scaling regime diversity (multi-language, imperative logic, effectful semantics) and model capacity will likely further erode remaining performance gaps.
Key directions for advancement include:
- Mitigating proof synthesis bottlenecks—using larger models, chain-of-thought prompting, or hybrid neuro-symbolic proof engines.
- RL-based optimization, where reward is more tightly coupled to proof validity and instance difficulty rather than SFT proxy losses.
- Extension to memory, side-effect, or bit-level tasks via logical backends in C, Rust, or Python.
- Creation of open, robust benchmarks for equivalence reasoning, as demonstrated with OpInstruct-HSx.
Conclusion
The semantic self-play framework establishes a new baseline for endowing LLMs with verifiable program equivalence reasoning, outperforming purely counterexample- or test-driven approaches in high-level functional domains. Equivalence supervision by proof confers significant generalization ability, while adversarial difficulty calibration promotes robust, transferable code understanding. The approach demonstrates clear practical promise for high-assurance code generation and theoretical value for neuro-symbolic alignment, though improvements in proof generation (model scale and training methodology) and extension to more expressive semantic spaces remain critical frontiers.

