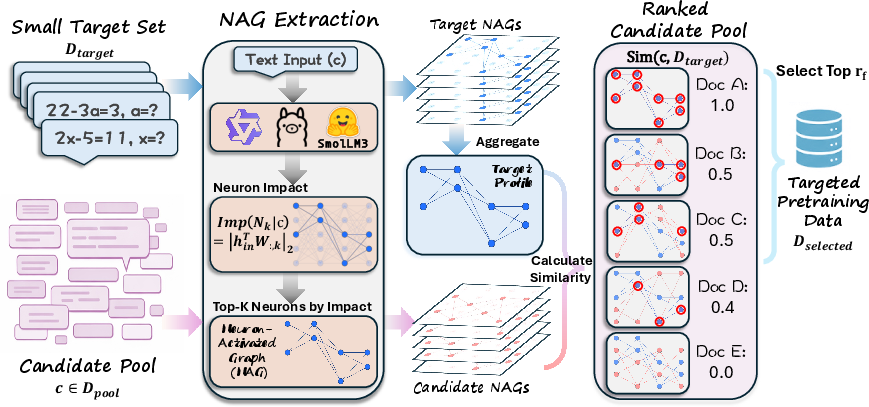
- The paper presents a neuron-centric pretraining data selection method that leverages sparse neuron activation profiles to directly guide data curation.
- It employs per-input neuron impact quantification across layers to construct graphs that match candidate data with target task profiles.
- Empirical results show up to a 5.3% accuracy improvement and enhanced efficiency across diverse benchmarks.
Neuron-Activated Graphs for Target-Oriented Pretraining Data Selection
Motivation and Problem Setting
The effectiveness of LLM pretraining is fundamentally influenced by the alignment between the pretraining data distribution and a targeted downstream domain or task. Conventional selection paradigms, predominantly based on global data ``quality'' heuristics or black-box embedding similarity, fail to provide interpretable, highly task-aligned data curation. These approaches are limited by their reliance on shallow metrics or features that often disregard the intricate distribution of internal model dynamics central to the acquisition of domain- or task-specific capabilities.
This work proposes a neuron-centric paradigm for pretraining data selection, Neuron-Activated Graph (NAG), which leverages per-input sparse neuron-activation profiles as the principal selection feature. NAG forgoes black-box distillation in favor of model-based interpretability: selection is driven by quantifiable, localized neuron impact on inference computations for a given target set and candidate data.
As the authors motivate, such a framework directly aligns the selection process with the functional backbone'' of neural computation required to support a task, addressing a known gap between heuristicquality'' and actual task induction.
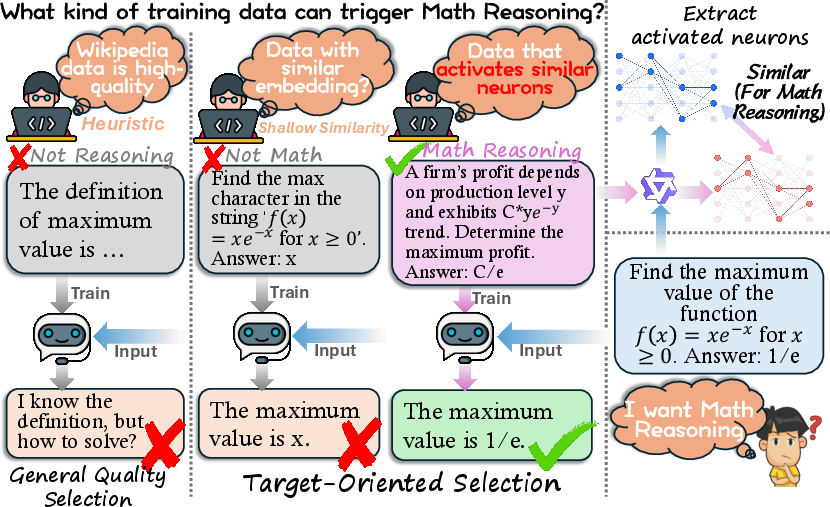
Figure 1: General-purpose data selection (left) and prior target selection (middle left) fail to align model-layer specificity to downstream needs. NAG selection (middle right) admits neuron-level task alignment, generalizing across distinct domains.
Methodology
Neuron Impact Quantification
NAG begins by measuring neuron impact for each input. For a given neuron (column of a projection matrix in Transformer modules, both in FFN and attention sublayers), the impact of deactivation is defined as the ℓ2-norm difference in the layer's output with and without the neuron. The formulation is lightweight, eschewing expensive final-output loss proxies in favor of a validated local surrogate. By extracting maximal impact across the sequence and aggregating across all layers, the method identifies a sparse subset of high-impact “activated” neurons for each instance.
Construction and Use of Neuron-Activated Graphs
These per-instance high-impact neurons are formalized as the NAG: for each input, each layer contributes the indices of K top-impact neurons, forming a layered, sparse graph. Data selection then proceeds by:
Unlike classifier-based or embedding-proxy approaches, NAG is training-free (when using an off-the-shelf LLM) and interpretable. The selection can be adapted to both single-task and multi-task target settings. Integration with existing classifier-based quality signals (e.g., FineWeb-Edu) is also feasible by rank aggregation.
Empirical Results
Main Findings
Across six challenging benchmarks spanning reasoning, factual QA, and commonsense domains, the NAG selection method provides robust benefits:
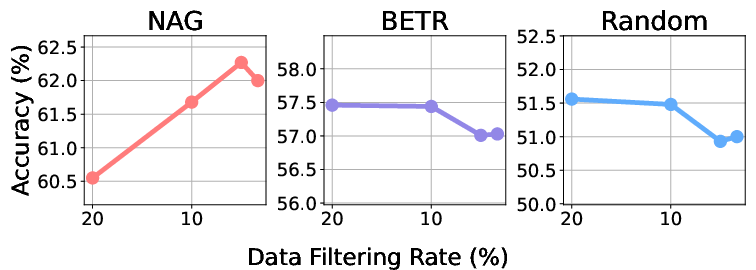
- Main accuracy improvements: NAG-based selection yields a strong mean improvement of 4.9% absolute accuracy over random data curation and outperforms advanced quality-based and task-matching baselines by 1–5% (notably +5.3% on HellaSwag).
- Multi-target robustness: In a scenario where multiple benchmarks are used as simultaneous targets, performance with direct mixture remains strong (e.g., +3.1% over random, +0.6% over FineWeb-Edu), whereas other target-oriented selectors often degrade significantly.
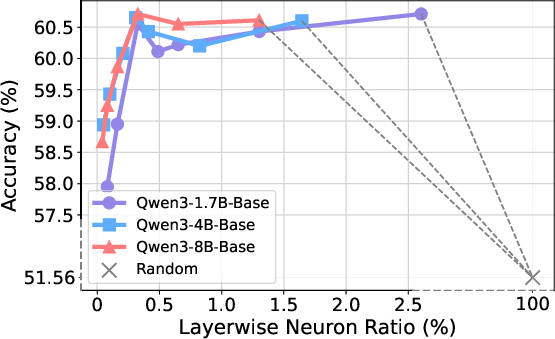
- Model-agnosticism: Comparable gains are observed when constructing NAG with Qwen3-1.7B-Base, Llama-3.2-3B, or SmolLM3-3B (accuracy gains persist in the 4.7–5.0% range).
The additive utility of NAG when combined with quality classifiers further demonstrates that task-discriminative signals captured by NAG are orthogonal to more global data quality proxies.
Compute and Efficiency
NAG-based selection yields compute multipliers of 1.27–2.42× versus baselines—the compute required to reach a fixed accuracy is reduced proportionally. Extraction costs are amortized, as only a single forward pass per document is required for NAG feature computation, with reuse across arbitrary downstream targets.
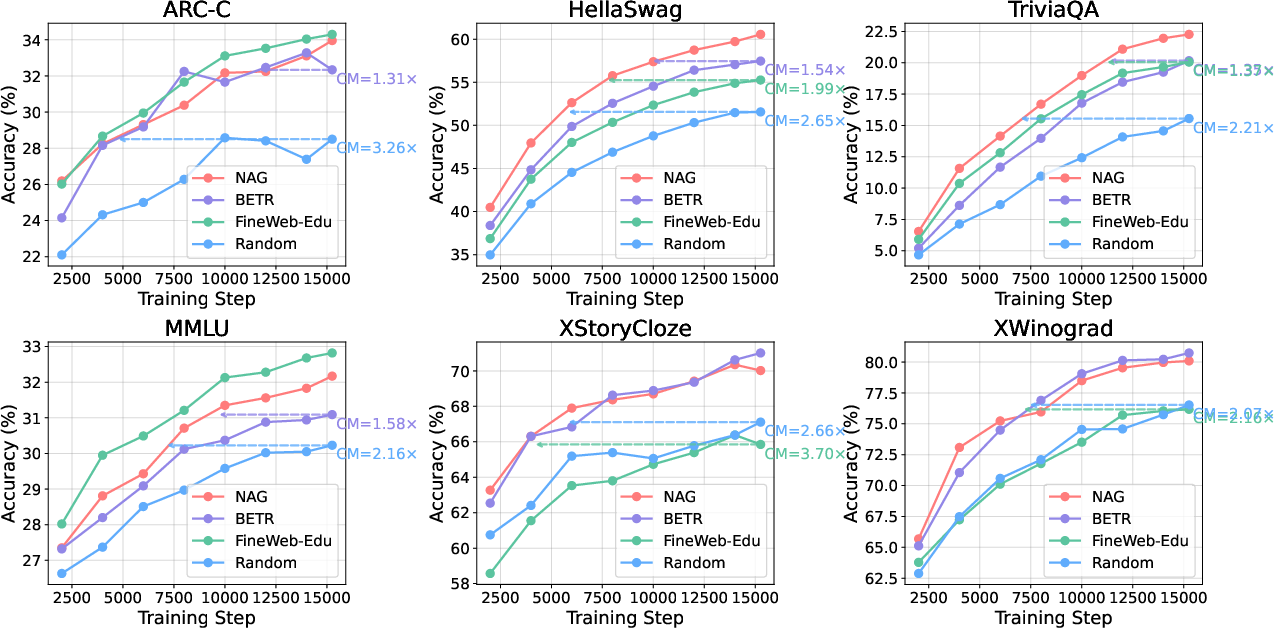
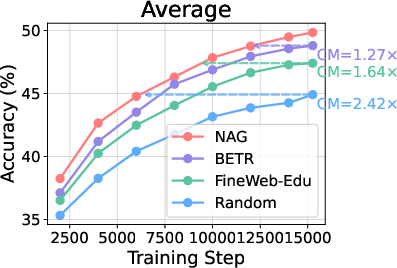
Figure 3: Compute multipliers (i.e., training efficiency improvements) of NAG selection relative to baselines across several benchmarks, with CM >1 indicating greater efficiency.
Analysis: Mechanisms and Interpretability
Task Decomposition and Neuron Importance
The ablation study finds that deactivating as little as 0.12% (20 neurons per layer) of the model selected by NAG induces a catastrophic 23.5% mean accuracy drop, while random neuron deactivation is negligible. This supports the hypothesis that NAG isolates the functional backbone actually responsible for the targeted capability.
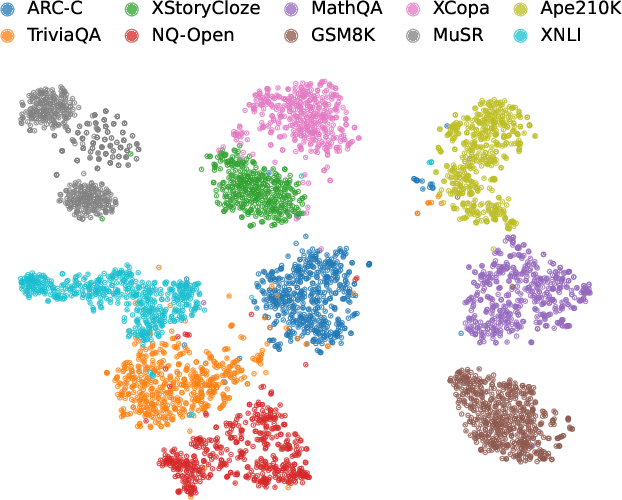
Figure 4: Clusters formed from NAG features strongly correspond to ground-truth task divisions, demonstrating that NAG encodes task-discriminative information.
Design Choices: Neuron Type, Layer, Sparsity
Theoretical and Practical Implications
This work demonstrates that neuron-level structural features—well beyond surface text similarity or task-agnostic ``quality'' heuristics—yield highly selective, efficient, and interpretable data curation for task-aligned pretraining. By characterizing data through the lens of sparse, layer-distributed computational pathways, one directly aligns the data selection mechanism with the underlying representational and procedural substrate for the target task.
The practical implication is a robust, training-free selection process transferrable across model scales and architectures (including smaller extraction models), compatible with real-world multi-target settings, and composable with existing pipelines. Theoretical insights flow toward a more granular understanding of which precise model subsystems (neurons) are required for task generalization, and how these can be targeted through pretraining data.
Methodological advances may extend toward even finer-grained, sparsity-controlled pathway manipulation (neurons, mechanisms, even attention heads). Applications beyond data selection—e.g., model editing, modularity analysis, targeted domain adaptation—are well-motivated by these findings.
Conclusion
The Neuron-Activated Graph framework establishes a new standard for target-oriented pretraining data selection, grounded in sparse, interpretable neuron activity. It closes the loop between the selection procedure and the emergent circuit structure underlying task competence, outperforming both heuristic and learned black-box alternatives. Future research will refine NAG pathway modeling, explore scaling to even larger LLMs and diverse corpus compositions, and integrate more advanced algorithmic strategies for multi-target mixture. The direct use of model-internal computational structure for steering data curation opens a promising direction for both practical model development and the scientific study of LLM internal representations.
References
For a complete reference list supporting all technical content and claims, see (2604.15706).