SpatialEvo: Self-Evolving Spatial Intelligence via Deterministic Geometric Environments
Abstract: Spatial reasoning over three-dimensional scenes is a core capability for embodied intelligence, yet continuous model improvement remains bottlenecked by the cost of geometric annotation. The self-evolving paradigm offers a promising path, but its reliance on model consensus to construct pseudo-labels causes training to reinforce rather than correct the model's own geometric errors. We identify a property unique to 3D spatial reasoning that circumvents this limitation: ground truth is a deterministic consequence of the underlying geometry, computable exactly from point clouds and camera poses without any model involvement. Building on this insight, we present SpatialEvo, a self-evolving framework for 3D spatial reasoning, centered on the Deterministic Geometric Environment (DGE). The DGE formalizes 16 spatial reasoning task categories under explicit geometric validation rules and converts unannotated 3D scenes into zero-noise interactive oracles, replacing model consensus with objective physical feedback. A single shared-parameter policy co-evolves across questioner and solver roles under DGE constraints: the questioner generates physically valid spatial questions grounded in scene observations, while the solver derives precise answers against DGE-verified ground truth. A task-adaptive scheduler endogenously concentrates training on the model's weakest categories, producing a dynamic curriculum without manual design. Experiments across nine benchmarks demonstrate that SpatialEvo achieves the highest average score at both 3B and 7B scales, with consistent gains on spatial reasoning benchmarks and no degradation on general visual understanding.
First 10 authors:


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
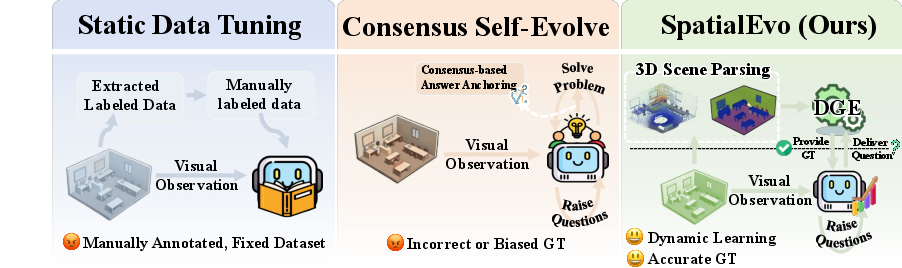
This paper introduces SpatialEvo, a new way to teach AI to understand 3D spaces (like rooms) better. Instead of relying on humans to label tons of data, SpatialEvo lets the AI learn by “playing” with a perfect 3D referee that can check answers exactly using the true geometry of the scene. This helps the AI get smarter over time without copying its own mistakes.
What questions did the researchers ask?
The paper focuses on three simple but important questions:
- How can we help an AI keep improving at 3D spatial reasoning (things like distance, size, direction) without needing expensive human-made labels?
- Can we avoid “bad teaching signals” that happen when models agree on the wrong answer?
- If a computer can compute the true answer from the 3D scene itself, can that become a reliable teacher that never lies?
How did they do it? (Methods explained simply)
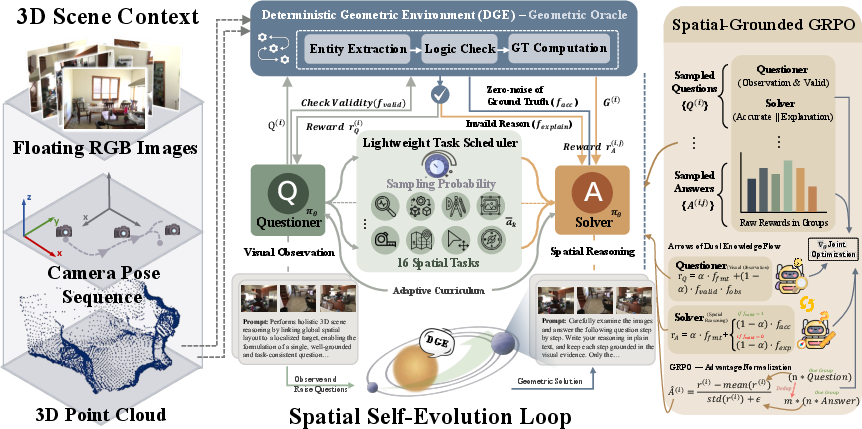
Think of a 3D scene (a room) as a dot-to-dot model in space (a “point cloud”), plus information about where a camera was and which way it pointed (“camera poses”). From this, a computer can calculate exact facts: how far objects are, which way the camera moved, which object is closer, etc.
SpatialEvo has three main parts:
- The Deterministic Geometric Environment (DGE):
- It checks whether a question is valid (does the object exist? is the view clear enough?).
- It computes the exact ground truth answer directly from the 3D data.
- One AI model with two roles: Questioner and Solver
- As the Questioner: it looks at the images and asks good, physically valid questions about the scene.
- As the Solver: it answers those questions.
- The DGE checks the questions and grades the answers.
- A smart practice planner (Scheduler) Like a coach, it notices which types of questions the model is weak at, then gives more practice in those areas. This creates a natural “curriculum” that adapts as the model improves.
How learning works (analogy): It’s like a student practicing geometry with a perfect answer key. The student also writes their own practice questions. A coach focuses practice on weak spots. The student gets points (rewards) for asking valid, well-grounded questions and for giving correct answers. If the student asks a bad or impossible question, they’re told why—and they learn from that too.
Key terms in everyday language:
- Point cloud: a 3D dot map of the room.
- Camera pose: where the camera was and which direction it faced.
- Deterministic: the answer is fixed and exact (like 2 + 2 = 4).
- Reinforcement learning: learning by trying, getting feedback, and improving.
- GRPO: a training method that updates the model based on relative rewards, like scoring multiple attempts and nudging the model toward the better ones.
What did they find, and why is it important?
Main results:
- Better scores across many tests: SpatialEvo achieved the highest average performance on 9 different benchmarks with both small (3B) and medium (7B) model sizes. It got especially strong gains on spatial reasoning tasks (like measuring distances, sizes, directions, and camera motion).
- No loss in general skills: While getting better at spatial tasks, the model did not get worse at general visual understanding.
- The physics referee matters most: When the authors replaced the DGE’s exact answers with the common “majority vote from models” approach, performance dropped a lot—especially on geometry-heavy tasks. This shows that exact, physics-based feedback is crucial.
- The two-role setup helps: Removing the Questioner or the Solver reduced performance. Having the model both ask and answer, with DGE checking, leads to better learning.
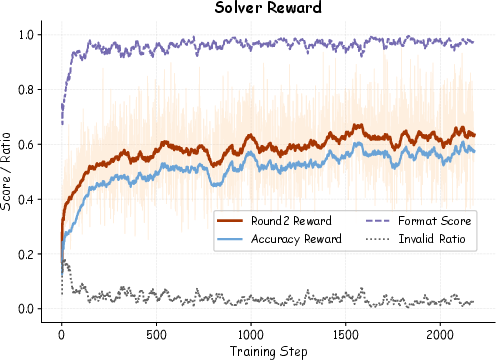
- Learning from mistakes helps: Even when a question is invalid, making the Solver explain why it’s invalid improves understanding of the rules.
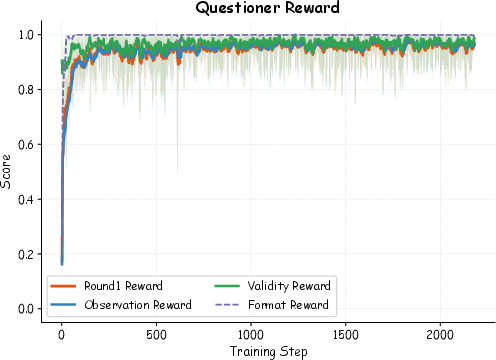
- The coach (Scheduler) works: Focusing practice on weak areas led to steady improvement across training rounds.
Why this matters:
- Most “self-improving” AI methods use the model’s own guesses to create labels, which can repeat and reinforce its mistakes.
- Here, ground truth comes from the actual 3D geometry—so the training signal is clean and reliable.
- That means the model can keep getting better without expensive human labels or bad feedback loops.
What could this change?
- Smarter embodied AI: Robots and AR/VR assistants that can navigate and understand rooms more reliably (e.g., “How far is the closest chair?” “Is the kitchen to the left of the living room?” “Did the camera move forward or turn right?”).
- Scalable training: You can turn any 3D scene dataset into a “teacher” without manual annotation. This makes it easier and cheaper to build strong spatial reasoning systems.
- Better curricula for AI: Adaptive practice that targets weaknesses could become a standard way to train models on complex skills.
- Stronger reasoning foundations: Using exact physical laws as feedback may help future models avoid common reasoning traps, especially in tasks where precise geometry matters.
In short
SpatialEvo teaches AI to reason about 3D spaces by replacing guesswork with physics. A perfect geometric “referee” provides exact answers, the model plays both quiz master and contestant, and a smart coach assigns practice where it’s needed most. The result is better spatial understanding, fewer errors, and a training process that scales without heavy human labeling.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, intended to guide future research.
- Robustness to imperfect 3D assets: How does performance degrade with realistic reconstruction noise, pose drift, mis-calibration, sparse point clouds, or missing semantics? Provide controlled noise-injection ablations and quantify sensitivity per task.
- Dependence on semantic annotations: DGE assumes reliable object categories and segmentations; what happens when semantics are incomplete, mis-labeled, or open-vocabulary? Explore zero-shot category handling and robustness to detection errors.
- Static-scene assumption: DGE is designed for static indoor scenes; how to extend deterministic ground-truth computation to dynamic objects and nonrigid scenes, or outdoor/large-scale environments with long trajectories and moving agents?
- Generalization without 3D assets: Many domains lack point clouds/poses at training time. Can SpatialEvo pretrain with DGE and transfer to settings with only RGB? What proxies (e.g., differentiable SLAM, NeRFs, or synthetic simulators) can replace DGE while preserving stability?
- LLM-based entity parsing noise: Entity extraction relies on a lightweight LLM, introducing non-deterministic parsing errors. Quantify parser error rates, their impact on reward/learning, and compare against rule-based or constrained parsers.
- LLM-judged rewards contradict “zero-noise”: Observation- and explanation-quality scores come from an LLM judge. Measure judge reliability, variance across LLMs, and the extent to which judge noise biases policy updates; explore self-consistency, rubric-calibrated scoring, or human-calibrated gold sets.
- Ambiguity in natural language mapping: How robust is the DGE pipeline to paraphrases, coreference, colloquialisms, and under-specified questions? Provide stress tests for linguistic variation and clarify how ambiguities are resolved or rejected.
- Numerical tolerances and degeneracy filters: The paper defers tolerance thresholds and degeneracy rules to the appendix; assess sensitivity to these settings, potential biases introduced by filtering “hard/ambiguous” cases, and their effect on real-world generalization.
- Task coverage gaps: The 16 tasks omit important spatial competencies (e.g., support/containment relations, affordances, occlusion completion, free-space/topology beyond pairwise, symmetry, functional layouts, and physical stability). Specify extensions to DGE and validate them empirically.
- Evaluation on embodied control: Results focus on QA-style benchmarks; does learned spatial competence improve closed-loop navigation/manipulation in simulators or real robots? Benchmark in embodied tasks with action feedback and latency constraints.
- Domain shift and visual conditions: Since the model only sees RGB while DGE uses high-fidelity geometry, does supervision transfer under lighting changes, motion blur, heavy clutter, or sensor artifacts? Test across varied capture conditions and devices.
- Scheduler design and stability: The task-adaptive scheduler uses historical accuracy only. Analyze convergence properties, potential oscillations, and compare with learning-progress, uncertainty-, or diversity-aware schedulers; report sensitivity to hyperparameters (e.g., minimum exploration δ).
- Credit assignment under shared parameters: A single model plays both roles; analyze interference vs. synergy between questioner and solver gradients, and compare to decoupled networks, role-specific adapters, or alternating-update strategies.
- RL stability and sample efficiency: GRPO details (KL control, variance reduction, clipping) are lightly specified. Report training stability across seeds, sample complexity vs. baseline SFT/RL, and ablations on group sizes n, m.
- Computational cost and scalability: Quantify wall-clock, GPU hours, and geometric verification overhead per scene; characterize scaling behavior with larger backbones, more scenes, and longer video sequences.
- Reward hacking risks: Despite gating, can the questioner exploit DGE/LLM judges (e.g., trivially valid but low-utility questions) or can the solver overfit to systematic quirks? Provide audits for exploitative behaviors and countermeasures (adversarial checks, diversity penalties).
- Fairness and statistical rigor of comparisons: Baselines differ in task coverage and training paradigms; report multiple seeds, confidence intervals, and matched-coverage comparisons to ensure claims are statistically robust.
- Data leakage and overlap: Using ScanNet/ScanNet++ as DGE sources raises potential overlap with evaluation benchmarks. Disclose exact scene splits/IDs and verify no leakage; test on disjoint datasets (e.g., Matterport3D, Replica, Habitat).
- Interpretation and explainability: The DGE stores intermediate geometric states, but these are not used to train or evaluate interpretability. Can these be converted into supervisable rationales or visualizations that improve model transparency and trust?
- Handling continuous answers and discretization: Many tasks discretize continuous geometry (e.g., directions, distances). Detail binning/tolerance policies and study how discretization choices affect learning and evaluation.
- Multilingual generalization: The pipeline assumes English prompts/questions; assess cross-lingual parsing, mapping to geometric rules, and DGE compatibility with multilingual question generation.
- Bridging the RGB–geometry gap: The model is trained with only RGB while the “oracle” uses high-fidelity geometry. Investigate whether adding depth/normal tokens or learned 3D priors improves transfer from DGE supervision to RGB-only inference.
- Extension to differentiable feedback: DGE is non-differentiable; explore differentiable geometric surrogates or learned critics that approximate DGE to provide denser gradients while preserving correctness.
- Persistent failure modes: VSI-Bench scores remain far from saturation and some benchmarks (e.g., SpatialViz/STARE) show mixed trends. Provide per-task confusion matrices, error taxonomies, and targeted interventions on the hardest categories.
- Reproducibility details: The paper references appendices for prompts, thresholds, and rules; ensure public release of prompts, rule code, scene splits, and exact LLM versions. Report sensitivity to LLM choice/temperature and random seeds.
Practical Applications
Overview
This paper introduces SpatialEvo, a self-evolving framework for 3D spatial reasoning that replaces noisy model-consensus labels with exact, programmatically computed ground truth from a Deterministic Geometric Environment (DGE). A single vision-LLM alternates between “questioner” and “solver” roles while a task-adaptive scheduler focuses learning on weak skills. The approach covers 16 spatial task categories (e.g., distances, directions, camera pose relations) using multi-view images while relying on point clouds and camera poses only for computing training signals—not for inference.
Below are practical applications that leverage these findings, methods, and innovations. Each item notes target sectors, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
These can be piloted or deployed now with existing 3D capture pipelines (e.g., phones with ARKit/ARCore, RGB-D cameras, LiDAR) and standard VLM infrastructure.
- Robotics and automation (indoor navigation/manipulation)
- Use cases: Robot navigation in homes/hospitals/warehouses; pose-aware pick-and-place; obstacle distance estimation; depth-order planning; visibility checks.
- Sectors: Robotics, logistics, manufacturing, healthcare operations.
- Tools/products/workflows:
- “DGE-powered robot curriculum”: Use on-robot multi-view videos + SLAM/LiDAR maps as inputs to DGE; auto-generate validated spatial QAs; train VLM policies via GRPO; deploy solver for runtime spatial reasoning.
- ROS2 integration: A node exposing “ask-the-scene” APIs (e.g., “distance to pallet,” “direction to docking station,” “is object A in view of camera 3?”).
- Assumptions/dependencies: Accurate camera poses and reasonably dense maps; semantic categories available for referenced objects; privacy-safe data capture in facilities; runtime may need multi-view images.
- AR/VR/MR assistants and measurement
- Use cases: On-device room measurement; relative direction prompts; depth-order queries for occlusion-aware overlays; interior design guidance (“Is the couch at least 1.5 m from the TV?”).
- Sectors: Consumer apps, interior design, real estate, retail.
- Tools/products/workflows:
- Mobile SDK plug-in: “SpatialEvo-Answers” that takes a short room scan and answers constrained spatial questions.
- AR authoring tool: Natural-language scene interrogation for content placement and collision checks.
- Assumptions/dependencies: Device-level camera pose tracking (ARKit/ARCore) and quick scans; stable object category mapping.
- AEC (Architecture, Engineering, Construction) and digital twins
- Use cases: As-built verification (room size, clearances); object placement checks (distances/orientation); camera coverage planning; progress tracking via measured deltas.
- Sectors: Construction tech, facility management, smart buildings.
- Tools/products/workflows:
- “DGE QA layer” for BIM/digital twins: Automated question generation + deterministic verification for clash checks and compliance rules (e.g., clearance standards).
- Site QA console: Project managers ask natural-language spatial questions against scans; solver returns grounded answers and evidence.
- Assumptions/dependencies: Sufficiently accurate scans (mobile LiDAR or photogrammetry), reliable pose estimation; standardization of object labels across projects.
- Retail and inventory analytics
- Use cases: Planogram compliance (shelf spacing, facing counts); aisle width checks; camera-to-shelf geometry for loss-prevention analytics.
- Sectors: Retail ops, in-store analytics, robotics in retail.
- Tools/products/workflows:
- “Spatial compliance auditor”: Batch ingestion of store scans; DGE-autogenerated questions for compliance metrics; solver outputs pass/fail and quantitative measures.
- Assumptions/dependencies: Periodic store scans; consistent taxonomy for products/fixtures; handling occlusions.
- Security and camera network design
- Use cases: Relative camera pose estimation; view overlap/coverage analysis; blind-spot detection; camera-to-region checks.
- Sectors: Physical security, smart facilities.
- Tools/products/workflows:
- Camera planner: Use site scans to query coverage (“Is corridor fully visible from cameras A/B?”); propose reconfigurations based on deterministic geometry.
- Assumptions/dependencies: Accurate camera extrinsics (or calibrated via scan); well-posed regions of interest.
- Healthcare facility logistics
- Use cases: Bed/equipment spacing verification; sterile field clearance; equipment room planning; robot portering route checks.
- Sectors: Healthcare operations, medtech robotics.
- Tools/products/workflows:
- “Spatial safety checklist”: Deterministic QA over OR/ICU scans for required distances and orientations; solver produces interpretable evidence (e.g., keypoints, trajectory segments).
- Assumptions/dependencies: Strict privacy procedures for scans; high geometric accuracy in constrained clinical spaces.
- Software and developer tooling
- Use cases: Deterministic unit tests for spatial VLMs; continuous integration with exact ground truth; dataset bootstrapping without manual labels.
- Sectors: Software/AI tooling, ML ops.
- Tools/products/workflows:
- DGE-Engine open-source library: Python/C++ APIs for programmatic ground-truth computation (distance, direction, pose).
- “Benchmark-as-a-service”: Reproducible, deterministic evaluation suites for spatial tasks across models and releases.
- Assumptions/dependencies: Access to 3D assets during training/evaluation; CI/CD hooks in model release pipelines.
- Education and research training
- Use cases: Interactive geometry/spatial reasoning tutors; lab exercises with deterministic feedback; curriculum research with task-adaptive scheduling.
- Sectors: Education, academic research.
- Tools/products/workflows:
- Classroom labs: Students acquire small scene scans; questioner generates problems; solver answers with interpretable intermediates; DGE verifies.
- Research: Extend DGE rule sets, study curriculum emergence, compare to noisy pseudo-labeling baselines.
- Assumptions/dependencies: Access to scanning-capable devices; curated task rule sets for coursework.
- Insurance, claims, and real estate
- Use cases: Property measurement; claim damage extent via distances/areas; MLS listings with verified room dimensions and relative layout Q&A.
- Sectors: Insurance, proptech.
- Tools/products/workflows:
- “Spatial veracity report”: Deterministic checklists computed from scans; export to claims/underwriting systems; consumer-facing Q&A in listings.
- Assumptions/dependencies: Reliable consumer scans; process controls for fraud and privacy; standard measurement tolerances.
Long-Term Applications
These require further research, scaling, or integration (e.g., broader domains, on-device efficiency, privacy-preserving learning, standardization).
- Continual self-evolving embodied agents
- Vision: Robots that continuously scan their environments, auto-generate DGE-validated curricula, and self-improve spatial skills over time without human labels.
- Sectors: Home robotics, industrial automation, healthcare robotics.
- Tools/products: “Always-learning” RL stacks with GRPO + DGE; weak-spot schedulers that adapt to deployment sites.
- Dependencies: Safe on-device/self-hosted training; compute/energy constraints; robust online SLAM; safety governance for self-improving agents.
- Universal spatial intelligence across sensors and domains
- Vision: Extend DGE to outdoor and dynamic scenes (traffic, construction sites), multi-sensor fusion (LiDAR, radar, thermal), and moving-object reasoning.
- Sectors: Autonomous driving, smart cities, defense, mining.
- Tools/products: DGE-Outdoor modules (road topology, dynamic actor geometry); temporal rule sets for motion constraints.
- Dependencies: High-quality calibrated sensor suites; dynamic object modeling; handling non-rigid and non-Lambertian effects.
- Standardized, deterministic evaluation and certification
- Vision: Policy and industry standards that mandate DGE-like deterministic tests for spatial AI in safety-critical settings (hospitals, factories, public spaces).
- Sectors: Regulatory bodies, safety certification, procurement.
- Tools/products: Conformance suites; certification labs with reference scenes; procurement checklists specifying deterministic ground-truth requirements.
- Dependencies: Cross-industry agreement on task taxonomies, tolerances, and scene repositories; privacy/compliance frameworks for scan data.
- Digital twin governance and auditability
- Vision: City- or enterprise-scale digital twins with built-in geometric oracles for audit trails (e.g., who queried what, when, with deterministic evidence).
- Sectors: Smart infrastructure, utilities, transportation hubs.
- Tools/products: “Audit-ready” twin platforms; immutable logs of DGE-verified answers; explainable QA overlays.
- Dependencies: Scalable storage of high-fidelity geometry; data retention policies; robust access control and PII protections.
- Safety-aware AR glasses with real-time spatial QA
- Vision: On-headset assistants that answer precise spatial questions and enforce safety envelopes (e.g., “stay 2 m from edge”) with deterministic checks.
- Sectors: Field service, construction, warehousing.
- Tools/products: Optimized on-device solver; streaming DGE approximations using incremental mapping; latency-aware task scheduling.
- Dependencies: Efficient SLAM and mapping on-device; low-latency inference; battery and thermal budgets.
- Human–robot spatial collaboration via natural language
- Vision: Teams of humans and robots negotiating shared spatial tasks (lifting, alignment, handover) through natural-language questions verified by geometry.
- Sectors: Manufacturing, logistics, assistive robotics.
- Tools/products: Multimodal dialogue stacks where robot queries are validated by DGE; joint task planners guided by deterministic spatial facts.
- Dependencies: Precise shared frames, dynamic obstacle handling, high-frequency updates; alignment with human intent and safety norms.
- Privacy-preserving, federated spatial self-evolution
- Vision: On-device DGE computation and GRPO training with only model updates shared, enabling large-scale self-improvement without sharing raw scans.
- Sectors: Consumer devices, healthcare, finance, sensitive facilities.
- Tools/products: Federated RL + secure aggregation; synthetic scene perturbation for privacy.
- Dependencies: Efficient on-device training; differential privacy guarantees; robust aggregation across heterogeneous fleets.
- Marketplaces of “deterministic curricula”
- Vision: Exchange platforms for DGE rule sets and scene packs that target specific competencies (e.g., “tight-clearance navigation,” “multi-camera reasoning”).
- Sectors: EdTech, ML vendors, robotics integrators.
- Tools/products: Curated curriculum bundles; capability badges based on deterministic benchmarks.
- Dependencies: Licensing of scene data; consistent metadata and ontologies; fair-use guidelines.
- Cross-domain transfer to other deterministic-feedback tasks
- Vision: Apply the questioner–solver + GRPO + adaptive scheduler recipe to domains with executable ground truth (program synthesis, CAD/CAM, physics simulation).
- Sectors: Software engineering, design automation, scientific computing.
- Tools/products: “Executable-oracle” training stacks; automated problem generation with exact checkers.
- Dependencies: High-fidelity simulators or compilers as oracles; carefully defined rule sets; scalable reward computation.
Notes on Feasibility and Dependencies
- Data prerequisites: DGE requires accurate point clouds and calibrated camera poses to compute ground truth; for certain tasks, semantic labels and frame indices are needed.
- Quality controls: Robust degeneracy filtering and numerical tolerances are needed to handle sensor noise, occlusion, and sparse regions; these are built into DGE but must be configured per domain.
- Compute and integration: GRPO-based RL and multi-view processing demand non-trivial compute; integration with SLAM/photogrammetry pipelines and robotics stacks (e.g., ROS2) is required.
- Privacy and compliance: Scans of homes, workplaces, or clinics must meet privacy and governance requirements; consider on-device processing and federated training for sensitive environments.
- Generalization bounds: Current results are strongest for indoor scenes; extending to outdoor/dynamic contexts will require expanded rule sets and assets.
- Ontology and semantics: Consistent object category vocabularies improve entity parsing and rule applicability; cross-project/enterprise taxonomy alignment may be necessary.
Glossary
- Absolute distance: A metric measuring the direct Euclidean distance between entities in a scene. "A question about absolute distance reduces to a nearest-point computation on object bounding boxes;"
- Ablation studies: Experimental analyses that remove or alter components to assess their contribution. "Ablation studies confirm that replacing DGE ground truth with majority-vote pseudo-labels produces the single largest performance drop"
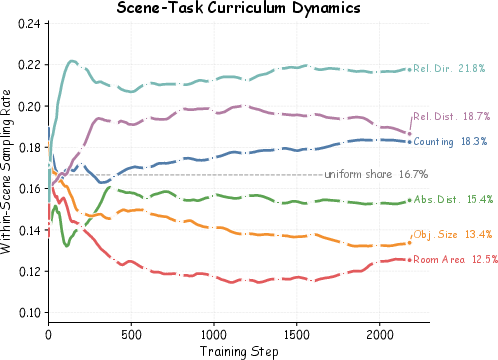
- Adaptive curriculum learning: Automatically adjusting training focus toward harder or weaker areas over time. "driving the emergence of an adaptive curriculum without any human intervention."
- Advantage values: Normalized per-group returns used in policy-gradient RL to reduce variance and bias. "Advantage values are computed independently within their respective groups to eliminate reward-scale bias introduced by inherent difficulty variation across scenes:"
- ARKitScenes: A real-world 3D dataset used for training and evaluation of spatial understanding. "and ARKitScenes~\cite{baruch2021arkitscenes}, comprising approximately 4K source scenes in total."
- Bird's-eye-view augmentation: A data transformation that projects scenes to a top-down view to aid spatial reasoning. "or bird's-eye-view augmentation to reduce annotation costs"
- Bounding box fitting: Estimating tight 3D boxes around objects from point clouds for metric computations. "the DGE directly performs bounding box fitting or plane normal estimation on the scene point cloud"
- Calibrated camera poses: Camera positions and orientations known with metric accuracy for geometric computation. "Given a dense point cloud, calibrated camera poses"
- Camera extrinsic matrices: Matrices encoding a camera’s position and orientation relative to a world frame. "resolving the rotational component between their extrinsic matrices,"
- Camera pose sequences: Ordered sets of camera positions and orientations across frames. "3D point clouds and camera pose sequences"
- Deterministic Geometric Environment (DGE): A programmatic environment that computes exact ground truth from 3D geometry. "centered on the Deterministic Geometric Environment (DGE)"
- Embodied intelligence: Intelligent behavior grounded in perception and action within physical environments. "Spatial reasoning over three-dimensional scenes is a core capability for embodied intelligence"
- Geometric degeneracy filtering: Excluding ambiguous or unstable configurations that hinder reliable reasoning. "geometric degeneracy filtering discards physically unstable, highly ambiguous, or low-training-value edge cases."
- Geometric oracle: A system that returns ground-truth answers via geometric computation rather than model judgment. "serving as the Geometric Oracle within the self-evolution loop."
- Geometric verification rule set: Formal criteria that determine if a spatial question is well-posed and solvable. "designs an atomic geometric verification rule set covering 16 spatial reasoning task categories"
- Global coordinate frame: A common world reference frame used to compute positions and transformations. "in the global coordinate frame."
- GRPO: A grouped policy optimization algorithm used for reinforcement learning with grouped samples. "We adopt the GRPO algorithm to drive the co-evolution of the questioner and solver."
- Majority voting: Aggregating multiple model predictions by selecting the most frequent as a pseudo-label. "through majority voting or self-consistency"
- Model consensus: Using agreement among model outputs to create training signals when labels are absent. "its reliance on model consensus to construct pseudo-labels causes training to reinforce rather than correct the model's own geometric errors."
- Multi-view RGB imagery: Sets of color images captured from different viewpoints of the same scene. "We formulate spatial reasoning as a visual question-answering process grounded in multi-view RGB imagery."
- Perspective projection: Mapping 3D points to a 2D image plane according to camera intrinsics and pose. "requires aligning perspective projection with the scene point cloud."
- Point cloud: A collection of 3D points representing scene geometry. "Given a dense point cloud, calibrated camera poses"
- Pseudo-labels: Labels generated by a model (or models) instead of ground truth, often noisy. "construct pseudo-labels causes training to reinforce rather than correct the model's own geometric errors."
- Pseudo-observation smoothing: A technique to stabilize estimated accuracies over time with limited samples. "via pseudo-observation smoothing to mitigate estimation instability"
- Relative direction: A categorical relation describing directional orientation between entities or cameras. "absolute distance, relative distance, relative direction, and room size estimation"
- Relative distance: A comparative measure of how far entities are from each other. "absolute distance, relative distance, relative direction, and room size estimation"
- Relative rotation matrix: The rotation aligning one camera pose to another. "the DGE then computes the relative rotation matrix and translation vector between the two poses"
- Reinforcement learning: Training by interacting with an environment and optimizing expected rewards. "SpatialEvo trains entirely via online reinforcement learning using the GRPO framework"
- Rigid-body coordinate transformation: Rotations and translations applied to transform coordinates between frames. "Core operators include rigid-body coordinate transformation, point cloud bounding-box fitting and topological analysis,"
- Rotation matrices: Orthogonal matrices representing 3D rotations. "reduces to an arithmetic operation on rotation matrices"
- ScanNet: A large-scale RGB-D indoor dataset for 3D reconstruction and understanding. "ScanNet~\cite{dai2017scannet}"
- ScanNet++: An extended dataset building on ScanNet with richer annotations and reconstructions. "ScanNet++~\cite{yeshwanth2023scannet++}"
- Self-consistency: A method that aggregates multiple sampled solutions from the same model to improve reliability. "through majority voting or self-consistency"
- Self-evolving paradigm: An approach where models improve by generating and learning from their own interactions. "The self-evolving paradigm offers a principled answer."
- Self-play: Training by having different roles of the same (or different) model interact to generate data and feedback. "through iterative self-play, self-evolving models can progressively internalize reasoning paradigms"
- Semantic annotations: Labels assigning meaning (e.g., object categories) to scene elements. "dense point clouds, semantic annotations, and camera pose sequences"
- Spatio-temporal reasoning: Understanding spatial relationships that evolve over time in videos. "benchmarks video spatio-temporal reasoning."
- Supervised fine-tuning (SFT): Refining a model on labeled examples with direct supervision. "without any supervised fine-tuning stage."
- Task-adaptive scheduler: A controller that biases sampling toward tasks where the model underperforms. "A task-adaptive scheduler endogenously concentrates training on the model's weakest categories"
- Topological spatial relations: Qualitative relationships like adjacency or ordering independent of exact metrics. "metric measurement, topological spatial relations, and camera pose reasoning."
- Visual grounding: Linking textual references to specific visual evidence in images. "provides adequate visual grounding for the generated question"
- Visual question answering: Answering natural-language questions about visual inputs. "We formulate spatial reasoning as a visual question-answering process"
- Vision-LLM (VLM): Models that jointly process and reason over visual and linguistic inputs. "Early work sought to enhance the spatial perception of VLMs"
- Zero-noise ground truth: Error-free labels computed directly from geometry rather than learned models. "zero-noise ground truth judge engine."
Collections
Sign up for free to add this paper to one or more collections.