- The paper introduces TokCode—a transmitter-side token encoder that preemptively mitigates semantic degradation under high packet loss (reducing performance gaps by up to 77.3%).
- It leverages parameter-efficient LoRA adaptation of large foundation models to optimize token sequences in the sentence semantic domain while preserving codebook compliance.
- Experimental evaluations in image transmission demonstrate that TokCode outperforms naive and receiver-only methods, ensuring robust semantic fidelity in extreme environments.
Token Encoding for Semantic Recovery: A Technical Analysis
Semantic communication frameworks are increasingly critical for robust and bandwidth-efficient transmission in extreme wireless scenarios—satellite, underwater, and marginalized terrestrial environments—where traditional communication mechanisms are hampered by severe channel constraints and high packet loss rates. Classical tensor-based systems offer substantial noise resilience but are less parsimonious in representation compared to token-based schemes, which leverage shared codebooks (e.g., derived from large foundation models) to achieve high efficiency by communicating discrete, semantically rich tokens.
The fragility of token-based systems manifests acutely in lossy, harsh wireless channels, where random packet erasures can excise critical token indices and cause irrecoverable semantic drift or degradation at the receiver. This paper proposes TokCode, a transmitter-side token encoding architecture for semantic recovery that operates without inflating transmission overhead and is agnostic to the need for additional receiver complexity.
The authors instantiate their token communication system in the image transmission scenario, employing generative models to reconstruct images from compact, text-prompt tokens. By anticipating the destructive effects of packet loss, TokCode semantically transforms source token sequences into loss-robust yet codebook-compliant equivalents, before transmission. This approach formalizes the semantic recovery problem as maximizing the expected semantic similarity (via cosine similarity in a learned multimodal feature space, e.g., CLIP) between the source and reconstructed content over stochastic channel realizations.
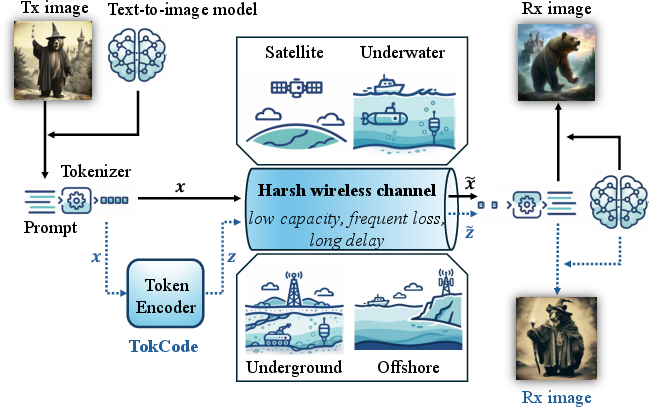
Figure 1: Token communication system for image transmission over harsh wireless channels. Solid and dashed lines indicate the conventional and TokCode's signal paths, respectively.
TokCode Framework and Optimization Methodology
The TokCode framework applies a semantic token encoder at the transmitter, operationalized as a function γ(x;Θ) mapping an N-length token vector to another vector in the same codebook, thereby preserving compatibility with downstream foundation models at the receiver. The central design principle—aggressive semantic-level protection of critical content—is motivated by the observation that naive token mapping leaves reconstructed meaning highly sensitive to arbitrary token deletions.
To circumvent the prohibitive cost and complexity of end-to-end training through generative and feature-extraction models, TokCode leverages parameter-efficient adaptation of pre-trained text foundation models, particularly employing LoRA (low-rank adaptation) to modify only a small fraction of the T5-XXL decoder's weights. This approach is computationally tractable, preserves the priors encoded during pretraining, and introduces minimal additional parameters relative to the base model.
Critical to the practical realization of TokCode is the algorithm SFMA (Sentence-semantic-guided Foundation Model Adaptation). Instead of backpropagating through the full text–image–feature stack (e.g., T5 → PixArt-Sigma → CLIP), SFMA minimizes a surrogate objective in the sentence embedding domain—specifically the similarity between original and received prompt embeddings, as measured by Sentence-T5. The optimization incorporates a norm regularization term to stabilize training dynamics. Straight-through estimation is employed to allow gradients to propagate through the sequence of softmax-sampled logit vectors, effectively bridging the gap between tokenized discrete outputs and differentiable model operations.
Evaluation and Comparative Analysis
The authors extensively benchmark TokCode against several receiver-side restoration baselines: (1) naive transmission, (2) T5-based masked token infilling, and (3) LLM-based prompt inference (using Llama3-8B-Instruct), under a packet interleaving and loss channel emulating realistic harsh conditions.
Visual comparisons (Figure 2) under p=40% packet loss demonstrate that TokCode substantially mitigates semantic distortion compared to both naive and receiver-end restoration strategies. Notably, critical content (e.g., subject identity or scene attributes) is more frequently preserved in the images synthesized from TokCode-protected tokens, with baseline methods exhibiting severe breakdown and LLM-based recovery tending to introduce uncontrolled semantic drift.

Figure 2: Rx-generated image comparison at p=40%. Rows from top to bottom correspond to lossless prompt, baseline, T5-based infilling, LLM-based prediction, and our proposed TokCode. Each sample corresponds to a test sample.
Quantitatively, TokCode reduces the gap towards an approximate optimum—where the sender knows the channel loss pattern and greedily preserves a maximally informative token subsequence—by 29.5% at p=40% loss and 77.3% at p=60% loss (measured in sentence similarity, Sentence-T5 domain). In the image domain (CLIP-based similarity), TokCode similarly approaches the upper bound and systematically outperforms receiver-side schemes, validating the incorporation of transmit-side semantic redundancy.
Critically, these gains are achieved with no increase in token sequence length and no transmission-side knowledge of receiver feedback or packet loss indices—a realistic operational constraint for one-way or high-latency links in extreme environments.
Theoretical and Practical Implications
A primary theoretical contribution is the demonstration that sentence-domain objectives can serve as effective surrogates for image-domain semantics in the context of robust code design for generative communication scenarios. The operational decoupling of encoder optimization from end-to-end generative models enables tractable adaptation of massive neural systems in resource-constrained settings.
Practically, TokCode's plug-and-play transmitter adaptation enables deployment without the need to coordinate codebooks or retrain downstream models—an appealing property for distributed or cross-vendor systems leveraging pretrained LLMs and generative diffusion models. The method's ability to preempt the unrecoverable loss of key semantic content via intelligent tokenization constitutes a significant step toward deployable, loss-robust semantic communication protocols for 6G and beyond.
Future Directions
Prospective extensions include:
- Exploration of variable-length or redundant token encodings, allowing for adaptive overhead under dynamically varying channel conditions.
- Extension to multi-modal content and non-textual symbol spaces.
- Integration of source-side, channel-aware policies using causal feedback or side-information.
- Theoretical analysis of information-theoretic limits induced by token-based semantic encoding under specific loss processes.
Conclusion
TokCode exemplifies a strategic shift in robust semantic communications: proactively shaping transmitted token sequences at the transmitter, instead of relying solely on receiver-end inference, to afford strong semantic resilience in severe wireless environments. By adapting a text foundation model via lightweight LoRA reparameterization and optimizing in the sentence-semantic domain, the approach achieves significant, quantifiable improvements in downstream generative fidelity and theoretically opens new pathways for the co-design of semantic encoders and modern generative models.