Habitat-GS: A High-Fidelity Navigation Simulator with Dynamic Gaussian Splatting
Abstract: Training embodied AI agents depends critically on the visual fidelity of simulation environments and the ability to model dynamic humans. Current simulators rely on mesh-based rasterization with limited visual realism, and their support for dynamic human avatars, where available, is constrained to mesh representations, hindering agent generalization to human-populated real-world scenarios. We present Habitat-GS, a navigation-centric embodied AI simulator extended from Habitat-Sim that integrates 3D Gaussian Splatting scene rendering and drivable gaussian avatars while maintaining full compatibility with the Habitat ecosystem. Our system implements a 3DGS renderer for real-time photorealistic rendering and supports scalable 3DGS asset import from diverse sources. For dynamic human modeling, we introduce a gaussian avatar module that enables each avatar to simultaneously serve as a photorealistic visual entity and an effective navigation obstacle, allowing agents to learn human-aware behaviors in realistic settings. Experiments on point-goal navigation demonstrate that agents trained on 3DGS scenes achieve stronger cross-domain generalization, with mixed-domain training being the most effective strategy. Evaluations on avatar-aware navigation further confirm that gaussian avatars enable effective human-aware navigation. Finally, performance benchmarks validate the system's scalability across varying scene complexity and avatar counts.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Habitat-GS: What this paper is about
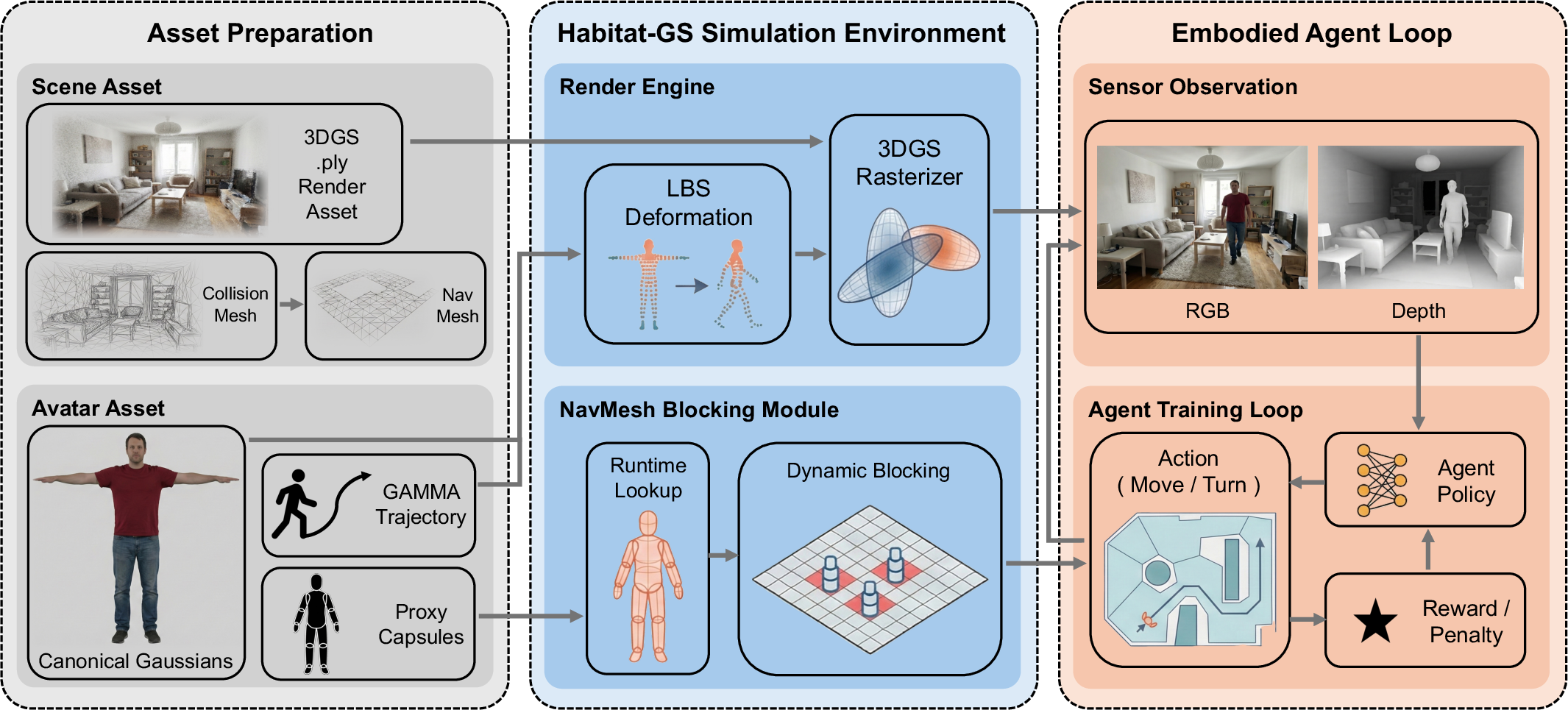
This paper introduces Habitat-GS, a new “virtual world” for training robots that need to move around in homes and other places. Think of it like a high-quality video game built for robots: it shows the robot realistic images and includes moving people, so the robot can practice getting to a target without bumping into anything or anyone. The big upgrade here is a new way to draw scenes and people that looks much more like real life, which helps robots trained in the simulator do better in the real world.
The main questions the paper asks
- How can we make simulated environments look more realistic so that what a robot learns in simulation works better in real life?
- How can we add moving, realistic-looking people into these simulations so robots learn to navigate safely around humans?
- Can we do all this fast enough for large-scale robot training, and on common GPUs?
How the system works (in everyday terms)
Habitat-GS improves a popular simulator (Habitat-Sim) in two big ways:
- More realistic scenes with 3D Gaussian Splatting (3DGS)
- Regular simulators use “meshes,” which are like cardboard models of rooms and objects with pictures glued on. They are fast but often look a bit fake and miss shiny reflections or fine details.
- 3D Gaussian Splatting draws scenes using millions of tiny soft blobs (like a cloud of glowing dust). When viewed together, they create very sharp, realistic images, including tricky effects like reflections.
- The authors built a fast graphics pipeline so these realistic scenes can be shown in real time, which is crucial for training.
- Moving, realistic people (“gaussian avatars”)
- The simulator includes human “avatars” made from those same tiny blobs, so they look much more like real people (wrinkles, hair, clothes) compared to simple 3D meshes.
- The avatars move using a standard “skeleton + skin” animation method (imagine a puppet with bones that bend the surface). The paper uses efficient GPU math to move the avatars smoothly without heavy, slow neural networks during runtime.
- For safety and navigation, the simulator gives each avatar invisible “capsules” (think of them like soft, upright traffic cones chained together along a body) that the robot cannot pass through. This lets the robot plan paths that avoid people.
A key design idea: visual–navigation decoupling
- The photorealistic blobs are used for what the robot “sees” (the camera images).
- A simple walkable map (a “NavMesh,” like a floor plan of where you can move) is used to plan the robot’s path and handle collisions. This works well because the blob-based scenes don’t have solid surfaces you can touch, but you still get very realistic visuals.
What they tested and how (without the heavy jargon)
The authors ran three kinds of experiments:
- Do the new scenes actually look more real? They asked a strong AI vision model to rate screenshots from old-style mesh scenes and new 3DGS scenes on quality, realism, and variety. The 3DGS scenes consistently scored higher.
- Do robots trained in these new scenes navigate better?
- Only mesh scenes (old way)
- Only 3DGS scenes (new way)
- A mix of both (different ratios)
- Robots were then tested in new mesh scenes and new 3DGS scenes they hadn’t seen before to check generalization.
- Can robots learn to avoid people? They added several walking avatars into the scenes and trained robots to reach the goal without colliding or getting too close. Then they tested if this safety behavior works both in 3DGS worlds and in mesh worlds.
They also measured speed and memory use to ensure training remains practical (fast enough, not too memory-hungry).
What they found and why it matters
Here are the main takeaways:
- 3DGS scenes look much more realistic. An AI judge rated them higher than meshes for quality, realism, and diversity. That means the simulated camera images are closer to what a real robot would see.
- Training only on meshes is fast but less robust. Robots learn basic navigation quickly, but they don’t generalize as well because the visuals are too simple compared to the real world.
- Training only on 3DGS builds stronger visual skills but can be slower to converge. With a fixed training budget, the “only 3DGS” robot hadn’t fully caught up yet, even though it showed better realism-driven gains.
- The best strategy is mixed training. Start with some mesh scenes (to learn the basics quickly), then train on more 3DGS scenes (to build visual robustness). This mix produces the most reliable robots across different environments.
- Realistic “gaussian avatars” teach better human-aware navigation. Robots trained around these lifelike, moving people had fewer collisions and fewer personal-space intrusions. Even when tested in lower-quality mesh worlds, the skills carried over—suggesting they truly learned to recognize and avoid people.
- It still runs fast. Even with millions of blobs and several avatars, the simulator runs at real-time speeds on common GPUs, making large-scale training practical.
What this means for the future
- Safer, more reliable service robots: Because the training visuals and human models are more realistic, robots should transfer their skills to the real world more smoothly, especially in human-populated places like homes, offices, and hospitals.
- Better research platform: Habitat-GS is open-source and works with the existing Habitat tools, so researchers can quickly try new ideas with realistic scenes and human avatars.
- Clear limits and next steps: The system is designed for navigation, not for detailed physical interactions like pushing or grasping objects made of blobs. To support manipulation, it would need deeper physics integration. But for the goal of safe, human-aware navigation, this approach is a strong step forward.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Sim-to-real transfer not validated: no deployment or policy transfer experiments on real robots to quantify whether 3DGS training improves real-world navigation performance vs mesh-based training.
- VLM-based quality assessment bias: reliance on Gemini scoring lacks human subject studies or objective image metrics; missing ablations controlling prompt sensitivity, dataset bias, and inter-rater agreement.
- Representation-isolation missing: cross-domain comparisons use different physical scenes across GS and mesh; no evaluation on the same environment represented both as mesh and 3DGS to isolate representation effects.
- Depth fidelity unverified: 3DGS depth is used for RGB-D observations, but its metric accuracy and noise characteristics vs real depth sensors (e.g., ToF/LiDAR) are not validated or calibrated.
- Sensor realism gaps: no modeling of realistic sensor noise, motion blur, rolling shutter, exposure, or auto-white-balance dynamics that influence sim-to-real perception.
- Limited sensor modalities: no support/evaluation for additional modalities (e.g., LiDAR, stereo, event cameras, audio), which often affect navigation policy robustness and transfer.
- Lighting and time-of-day variability: scenes appear static; no dynamic/global illumination, time-of-day, or lighting perturbations to test robustness to illumination shifts.
- Dynamic scene content beyond humans: backgrounds are static 3DGS; no support for dynamic non-human objects (doors, pets, carts) or scene rearrangements affecting navigation.
- Avatar reactivity absent: humans are not interactive—no social feedback (yielding, avoiding, path negotiation), gaze cues, verbal signals, or body-language responses to the agent.
- Limited crowd modeling: GAMMA-driven single-agent trajectories with few avatars; no crowd simulation, group behaviors, flow patterns, congestion, or multi-agent social norms at scale.
- Motion diversity gaps: avatar motions focus on walking; no running, carrying objects, sitting/standing transitions, falls, occlusion-heavy interactions, or diverse gait/age/body-shape distributions.
- Social compliance metrics: evaluation uses collision rate and personal-space intrusion; lacks richer social navigation metrics (e.g., time-to-collision, comfort, legibility, proxemics under different contexts).
- Collision proxy fidelity: capsule-based proxies may under/over-approximate human body occupancy; no quantitative analysis of proxy error vs avatar geometry or its effect on collision/PSI metrics.
- Prediction-aware planning: dynamic NavMesh blocking is reactive; no predictive models of human motion or intent integrated into planning to reduce near-miss and oscillatory behaviors.
- Control-level interaction: step clipping prevents penetration but can induce local minima; no analysis of how often clipping occurs, its effect on learning stability, or alternative continuous-time controllers.
- Physics-manipulation gap: system explicitly does not support force-level interaction; unclear path to enable grasping/pushing of 3DGS assets or mixed GS–mesh manipulation with consistent physics.
- Mixed-render occlusion and shading artifacts: depth compositing between CUDA 3DGS and OpenGL meshes may introduce z-fighting or edge artifacts; no quantitative artifact analysis or mitigation (e.g., epsilon tuning).
- Shadows and mutual illumination: 3DGS avatars likely do not cast physically plausible shadows onto GS scenes or meshes; the visual inconsistency’s impact on perception and policy learning is unexamined.
- Anti-aliasing and MIP integration: alias-free 3DGS (e.g., Mip-Splatting) is cited but not integrated or evaluated; the effect of aliasing on policy robustness remains unknown.
- Asset preparation scalability: no quantitative analysis of time/cost to reconstruct and clean large numbers of 3DGS scenes and avatars, nor guidance on minimal capture requirements for acceptable quality.
- Data distribution coverage: GS scenes are interior-focused; no evaluation on outdoor or mixed indoor–outdoor settings, large-scale navigation, or multi-floor buildings with elevators/stairs.
- Domain randomization vs photorealism: trade-offs between photorealistic GS assets and domain randomization strategies are unexplored; unclear if combining both further improves generalization.
- Training strategy scope: only DD-PPO is tested; missing comparisons with alternative architectures (e.g., transformer encoders, self-supervised pretraining) or auxiliary tasks (segmentation, depth, optical flow).
- Sample efficiency and compute cost: GS-only training converges slower; paper doesn’t quantify wall-clock training time, GPU-hours, or strategies to amortize cost (curriculum, progressive fidelity, replay).
- Scaling avatars: performance measured up to 10 avatars; no characterization of frame rate, memory, and learning stability with dozens/hundreds of agents (crowds) typical of public spaces.
- Distributed training and hardware coverage: benchmarks on a single RTX 4090; no evaluation on A100/H100 clusters (claimed support), multi-GPU scaling, or CPU bottlenecks in Habitat-Lab pipelines.
- API completeness for research tasks: semantics and instance masks for 3DGS not discussed; lack of annotation/segmentation support limits tasks like ObjectNav or semantic exploration.
- Safety edge cases: no tests under adversarial conditions (sudden stops, occlusions, narrow corridors, dense crowds) to probe failure modes and rare-event safety.
- Robustness to camera intrinsics/extrinsics shifts: no evaluation of generalization across different FOVs, mounting heights, or sensor placements typical across robot platforms.
- Generalization to other tasks: claims focus on PointNav; no experiments on ObjectNav, AudioNav, Rearrangement, or exploration to test broader utility of GS scenes/avatars.
- Reproducibility of avatar behaviors: offline GAMMA generation lacks seeds/protocols for reproducible motion diversity; unclear how to standardize scenario difficulty across studies.
- Ethical and demographic coverage: no discussion of diverse human appearances, clothing, mobility aids, or cultural proxemics—factors that influence social navigation policies and fairness.
- Licensing and redistribution: importing public and generative GS assets raises questions on licensing, privacy, and redistribution policies not addressed for large-scale benchmarks.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage Habitat-GS’s findings and system design.
- Mixed-domain training for robust robot navigation — sectors: robotics, software
- Description: Adopt the paper’s validated training recipe that mixes mesh and 3DGS scenes (e.g., 20–50% mesh + 50–80% GS) to accelerate convergence while improving cross-domain generalization in point-goal navigation.
- Tools/products/workflows: DD-PPO training in Habitat-Lab with 256×256 RGB-D sensors; scene packs curated from HM3D (mesh) and InteriorGS/Marble (3DGS); workflow to balance curricula between mesh and GS.
- Assumptions/dependencies: Availability of GS and mesh scene assets; adequate GPU budget (e.g., A100/H100 or RTX 4090); tasks limited to navigation, not manipulation.
- Human-aware navigation policy training and safety evaluation — sectors: robotics, policy, healthcare
- Description: Use gaussian avatars as photorealistic, dynamic obstacles to train service robots for socially compliant navigation. Evaluate with Collision Rate (CR) and Personal Space Intrusion (PSI) metrics to quantify safety and proxemics.
- Tools/products/workflows: Gaussian avatar module (SMPL-X + CUDA LBS), GAMMA-driven trajectories, NavMesh blocking via proxy capsules; reward shaping via distance-to-avatar and step-blocking APIs.
- Assumptions/dependencies: Accurate proxy capsule calibration; avatar motion realism (GAMMA trajectories); proxemics thresholds may need context-specific tuning (e.g., hospital vs. retail).
- Photorealistic synthetic RGB-D data generation for perception models — sectors: software, robotics, education
- Description: Render 3DGS scenes to produce high-fidelity synthetic data for training or benchmarking visual encoders (segmentation, detection, depth completion) used in embodied AI.
- Tools/products/workflows: CUDA–OpenGL interop for real-time RGB-D; domain randomization across GS assets; pipelines to augment or annotate GS assets (bounding boxes, semantic overlays).
- Assumptions/dependencies: GS assets typically lack native semantic labels; requires additional tooling for annotations; downstream models should be robust to GS visual characteristics.
- Pre-deployment “virtual QA” for mobile robots — sectors: robotics, facilities
- Description: Stress-test navigation policies across diverse GS scenes and avatar populations to identify failure modes (e.g., narrow corridors, reflective surfaces, crowded regions) before field trials.
- Tools/products/workflows: Scenario library with varying scene complexity and avatar counts; automated test harness that logs SR/SPL/DTG as well as CR/PSI.
- Assumptions/dependencies: Sim-to-real differences remain (e.g., physics and sensing peculiarities); policies must be tuned for robot-specific actuation and sensor noise.
- Facility layout and crowd-flow prototyping — sectors: retail, hospitality, healthcare
- Description: Rapidly prototype foot-traffic patterns (e.g., lobby flow, waiting areas, aisle layouts) by driving gaussian avatars along scene-aware paths and assessing bottlenecks or unsafe proximities.
- Tools/products/workflows: GAMMA-guided paths over NavMeshes; avatar occupancy heatmaps; iterative layout adjustments with quick re-renders.
- Assumptions/dependencies: Navigation-level obstacles only (no force/interactions); crowd models may need extensions for complex behaviors (queuing, group dynamics).
- Scalable RL training on datacenter GPUs — sectors: MLOps, cloud computing
- Description: Exploit Habitat-GS’s compatibility with non-RT datacenter GPUs (A100/H100) for large-scale parallel training without requiring RTX RT cores.
- Tools/products/workflows: Distributed training with DD-PPO across GPU clusters; per-scene performance profiles (e.g., 50–90 FPS in medium scenes with 1–2 avatars).
- Assumptions/dependencies: Memory and throughput scale linearly with gaussian count and avatar count; scheduling must respect per-node constraints.
- HRI user studies in simulation — sectors: academia, healthcare, robotics
- Description: Explore human–robot proxemics, avoidance strategies, and perception under realistic appearances and motions using GS avatars, before in-person experiments.
- Tools/products/workflows: CR/PSI metrics; scenario scripts for avatar behaviors; recorded trajectories to replicate experiments.
- Assumptions/dependencies: Cultural differences in personal space; avatars approximate humans visually/kinematically but do not model nuanced social signals (gaze, speech).
- Education and benchmarking modules — sectors: education, academia
- Description: Course labs on embodied AI using open-source Habitat-GS to teach navigation, sim-to-real, and human-aware policy design with reproducible, diverse GS assets.
- Tools/products/workflows: Ready-to-use scene and avatar packs; standardized tasks (PointNav, avatar-aware PointNav); baseline configurations and logs for SR/SPL/DTG/CR/PSI.
- Assumptions/dependencies: Access to CUDA-capable GPUs; classroom-friendly datasets (licensing, storage).
- GS asset curation pipelines — sectors: content creation, digital twins
- Description: Build a workflow to import and manage GS assets from reconstructions and generative pipelines (e.g., Marble) for rapid environment diversification.
- Tools/products/workflows: PLY-based asset repositories; quality filters via VLM scoring (rendering quality, realism, diversity); NavMesh generation toolchain.
- Assumptions/dependencies: Robust camera trajectories or scans; NavMesh availability; asset licensing and provenance.
Long-Term Applications
These applications require further research, scaling, or system extensions beyond what Habitat-GS provides today.
- Compliance certification for social navigation — sectors: policy, robotics, healthcare
- Description: Formalize CR/PSI thresholds and avatar-rich test suites as a certification standard for mobile robots operating around people (e.g., hospitals, airports).
- Tools/products/workflows: Auditable scenario banks; third-party cert labs; reporting dashboards; cross-cultural proxemics profiles.
- Assumptions/dependencies: Multi-stakeholder consensus; mapping sim metrics to field outcomes; periodic updates for new robot classes and contexts.
- Physics-enabled manipulation and contact-rich tasks in GS environments — sectors: robotics
- Description: Extend visual–navigation decoupling to support physics-grounded interactions (grasping, pushing) by tightly integrating GS assets with a physics engine and explicit collision geometry.
- Tools/products/workflows: Hybrid representations (GS for visuals + meshes/voxels for physics); contact simulators; learned tactile models.
- Assumptions/dependencies: GS lacks topology/rigidity; nontrivial engineering to maintain visual fidelity while enabling accurate forces/impulses.
- Building- and campus-scale digital twins with dynamic occupants — sectors: smart buildings, logistics, healthcare
- Description: Simulate operations (robot routes, occupant movement, cleaning schedules) in GS twins for planning, optimization, and what-if analyses.
- Tools/products/workflows: Large-scale GS scene generation; multi-avatar orchestration; scheduling and optimization layers.
- Assumptions/dependencies: Scalable asset creation for large sites; multi-sensor modeling (e.g., LiDAR, thermal) beyond RGB-D; ongoing synchronization with real facilities.
- Generative “scene factories” for embodied AI foundation models — sectors: software, robotics
- Description: Use generative 3DGS pipelines to produce vast, diverse environments to pretrain generalist navigation and perception policies that transfer broadly.
- Tools/products/workflows: Data engine that mixes synthetic GS scenes with curated meshes; curriculum design; continual learning pipelines.
- Assumptions/dependencies: Quality controls for synthetic diversity and realism; avoiding overfit to GS artifacts; scalable compute.
- Multi-agent social navigation with richer human behaviors — sectors: academia, robotics
- Description: Study dense crowds, social norms, and intent prediction with dozens to hundreds of avatars exhibiting group dynamics, queuing, and nonverbal cues.
- Tools/products/workflows: Behavior libraries; trajectory planners beyond GAMMA; scalable rasterization and NavMesh injection for many dynamic obstacles.
- Assumptions/dependencies: Performance at very high avatar counts; validated human behavior models; extended metrics (comfort, fairness, throughput).
- Language-conditioned embodied tasks in high-fidelity scenes — sectors: assistive robotics, education
- Description: Combine GS realism with instruction following (ObjectNav, Room-to-Room) to train agents that interpret natural language and navigate socially.
- Tools/products/workflows: Multimodal datasets pairing GS visuals with language; VLM-augmented policies; semantic annotation layers for GS.
- Assumptions/dependencies: Annotation pipelines for GS assets; robust grounding between language and visual cues; compute for multimodal training.
- Industry-specific sim-to-real bridges (warehouses, hospitals, retail) — sectors: logistics, healthcare, retail
- Description: Tailor Habitat-GS scenarios to industry environments (AMRs in warehouses, hospital delivery robots), including domain-specific obstacles and human workflows.
- Tools/products/workflows: Sector-specific GS asset packs; sensor models (LiDAR, stereo, RFID); KPI tracking (throughput, wait times, near-miss counts).
- Assumptions/dependencies: Accurate sensor simulation beyond RGB-D; integration with enterprise systems; policy alignment with workplace safety standards.
- Simulation-as-a-Service for embodied AI teams — sectors: software, cloud
- Description: Offer hosted Habitat-GS clusters with curated GS libraries and avatar packs for turnkey training, benchmarking, and safety testing.
- Tools/products/workflows: Cloud orchestration; experiment management; reproducibility tooling; billing and quota systems.
- Assumptions/dependencies: Data licensing for shared assets; cost-effective GPU provisioning; security and compliance.
- Cross-sensor fidelity modeling and benchmarking — sectors: robotics, automotive
- Description: Expand GS simulation to reliably mimic non-RGB sensors (active depth, LiDAR, thermal) for broader embodied tasks and outdoor navigation.
- Tools/products/workflows: Sensor plugins; noise/occlusion simulators; cross-domain generalization benchmarks.
- Assumptions/dependencies: Accurate physical modeling for each sensor; validation against real datasets; performance tuning for more complex render passes.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit point-based scene representation that renders anisotropic 3D Gaussians in real time for photorealistic views. "3D Gaussian Splatting (3DGS)~\cite{kerbl3dgs} represents scenes as collections of explicit anisotropic 3D Gaussians and renders them via differentiable tile-based rasterization, achieving real-time frame rates while maintaining rendering quality."
- AnimatableGaussians: A method that maps Gaussians to UV space to enable pose-driven avatar rendering. "AnimatableGaussians~\cite{animatablegaussians} maps 2D Gaussians into UV space for pose-driven rendering."
- avatar-aware navigation: Navigation that explicitly accounts for dynamic human avatars as obstacles. "Evaluations on avatar-aware navigation further confirm that gaussian avatars enable effective human-aware navigation."
- canonical gaussian attributes: The pose-independent parameters (e.g., position, color, opacity, scale) of Gaussians defined in a canonical space for later deformation. "first, canonical gaussian attributes, specifically positions, SH coefficients, opacities, scales, rotations, and LBS weights, exported from a trained gaussian avatar model."
- Collision Rate (CR): A metric measuring the fraction of time steps in which the agent collides with obstacles. "Collision Rate (CR), the fraction of collision steps."
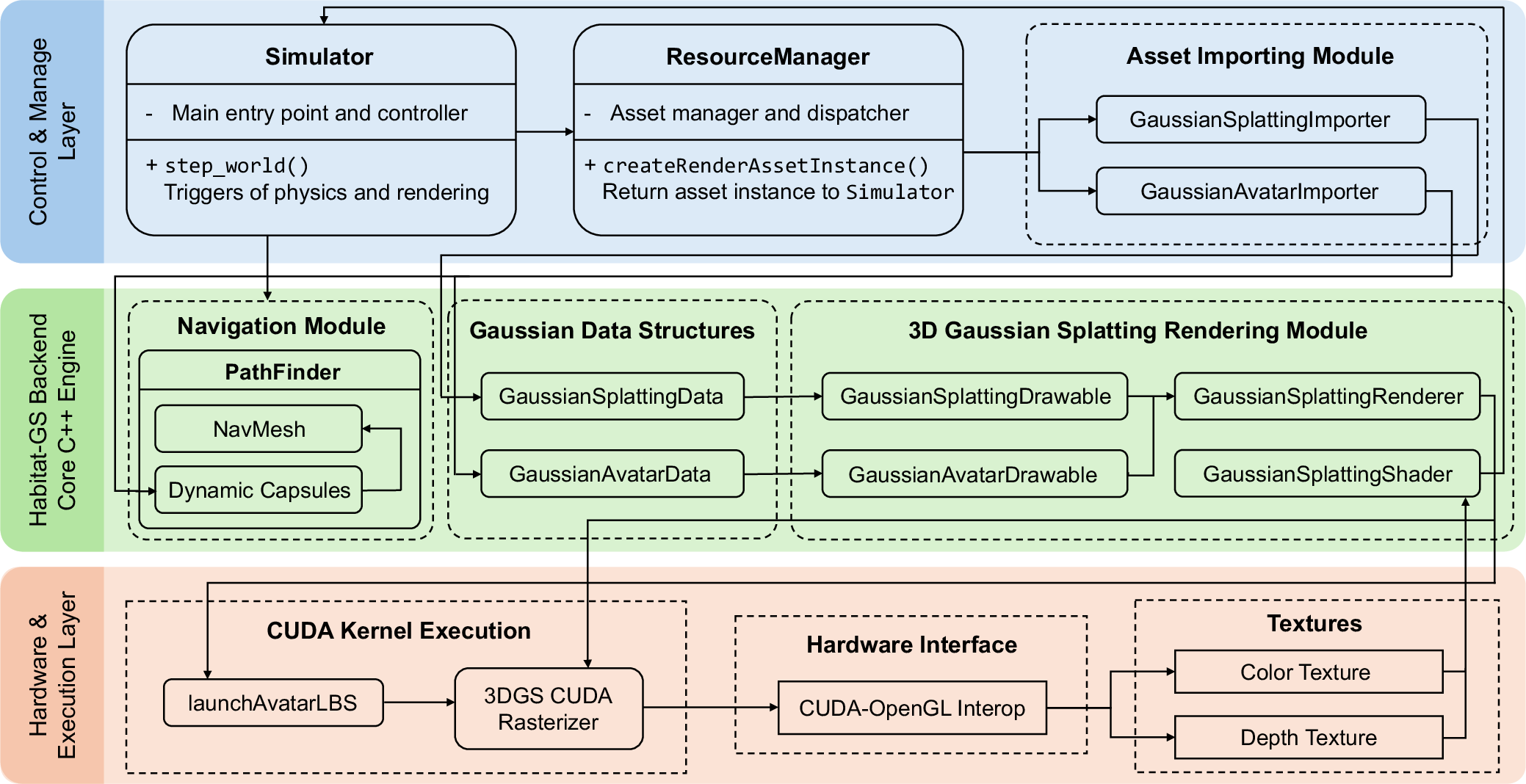
- CUDA-OpenGL interop: A technique to share GPU buffers between CUDA and OpenGL without CPU copies to enable efficient rendering pipelines. "for example via CUDA-OpenGL interop, and facilitates spatial editing, asset composition, and dynamic deformation."
- depth compositing mechanism: A rendering step that merges depth from different pipelines (e.g., CUDA 3DGS and OpenGL) to ensure correct occlusions. "we implement a depth compositing mechanism that merges the CUDA-produced 3DGS depth with the OpenGL depth buffer via a full-screen compositing pass."
- differentiable tile-based rasterization: A GPU rendering approach that processes image tiles and supports gradient-based optimization. "renders them via differentiable tile-based rasterization, achieving real-time frame rates while maintaining rendering quality."
- drivable gaussian avatars: Photorealistic, animatable human avatars represented by Gaussians that move according to motion controllers. "integrates 3D Gaussian Splatting scene rendering and drivable gaussian avatars while maintaining full compatibility with the Habitat ecosystem."
- Embodied AI: Research on agents that perceive and act in environments via sensors and actuators, often trained in simulation. "The prevailing paradigm in Embodied AI is therefore to train agents at scale in simulation and transfer the learned policies to reality~\cite{anderson2018evaluation,batra2020objectnav,wijmans2019dd}."
- forward kinematics: Computing joint transformations along a kinematic chain from pose parameters. "For each frame, we then compute the SMPL-X joint transformation matrices via forward kinematics."
- GAMMA: A generative motion model used to synthesize realistic, scene-aware human trajectories. "we employ the GAMMA motion generation model~\cite{gamma} in an offline trajectory synthesis pipeline."
- geodesic shortest-path length: The shortest path length constrained to the navigable manifold, used in navigation metrics. "where is the geodesic shortest-path length and the agent's actual path length."
- Habitat-Lab: The task and training API suite built atop Habitat simulators for embodied AI research. "Habitat-GS is designed for seamless integration with Habitat-Lab."
- Linear Blend Skinning (LBS): A skeletal deformation technique that blends bone transforms to deform geometry or Gaussians. "By employing pre-baked canonical gaussians with CUDA-accelerated Linear Blend Skinning, avatar deformation is driven in real time by SMPL-X~\cite{smplx} pose sequences without neural network inference at runtime."
- NavMesh: A polygonal representation of navigable surfaces used for path planning and collision-aware movement. "The NavMesh blocking module retrieves pre-computed proxy capsules at runtime and injects them into the NavMesh for obstacle blocking."
- Neural Radiance Fields (NeRF): An implicit neural representation that synthesizes novel views from images via volumetric rendering. "Neural Radiance Fields (NeRF)~\cite{nerf} demonstrated that implicit neural scene representations can synthesize photorealistic novel views from multi-view images."
- Personal Space Intrusion (PSI): A metric quantifying how often and how much the agent enters a human’s personal-space radius. "Personal Space Intrusion (PSI), which quantifies the average degree to which the agent enters the 1.0\,m personal-space radius around each avatar."
- proxy capsules: Simplified capsule primitives approximating avatar collision volumes for navigation-level collision handling. "proxy capsules that approximate the avatar's per-frame collision geometry."
- RT Core hardware: Specialized NVIDIA GPU hardware units that accelerate ray tracing operations. "their closed-source rendering backends impede the deep customization often required for research purposes. Moreover, these platforms depend on RT Core hardware available only in RTX-series GPUs"
- Score Distillation Sampling: A diffusion-based optimization technique used to generate 3D content (or avatars) guided by text/image models. "HumanGaussian~\cite{humangaussian} leverages Score Distillation Sampling~\cite{dreamfusion} for text-driven gaussian avatar generation."
- Sim-to-Real gap: The mismatch between simulation and reality that hinders transfer of learned policies. "The resulting visual domain gap between simulation and reality, commonly termed the Sim-to-Real gap, has been shown to degrade the transfer of learned navigation policies to physical platforms~\cite{tobin2017domain}."
- SMPL-X: A parametric human body model with expressive hands and face used to drive avatar poses. "from the skeletal bone segments of the SMPL-X model, and pre-compute their world-space positions for each frame of the trajectory."
- Success weighted by Path Length (SPL): A navigation metric combining success and path efficiency. "Success weighted by Path Length (SPL)~\cite{anderson2018evaluation} jointly captures success and path efficiency: , where is the geodesic shortest-path length and the agent's actual path length."
- step clipping routine: A planner safeguard that truncates the agent’s motion when a collision with dynamic obstacles would occur. "The path planner is augmented with a step clipping routine that checks for intersection between the agent's bounding capsule and each avatar capsule, clipping agent's motion at the collision boundary if necessary."
- URDF: Unified Robot Description Format for specifying robot kinematics and dynamics used to drive articulated bodies. "such as URDF-driven articulated bodies~\cite{ai2thor,sapien}"
- Vision-LLM (VLM): A model that jointly processes images and text; here used to assess scene quality automatically. "A VLM-based scene quality assessment first confirms that 3DGS scenes substantially surpass mesh scenes in rendering quality, realism, and scene diversity."
- zero-copy CUDA--OpenGL interoperability: A GPU-only data sharing mechanism that avoids host transfers between CUDA and OpenGL. "We address this through a zero-copy CUDA--OpenGL interoperability mechanism that keeps all rendering data on the GPU throughout the entire pipeline, eliminating CPU-side data movement."
Collections
Sign up for free to add this paper to one or more collections.