UniToolCall: Unifying Tool-Use Representation, Data, and Evaluation for LLM Agents
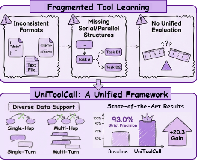
Abstract: Tool-use capability is a fundamental component of LLM agents, enabling them to interact with external systems through structured function calls. However, existing research exhibits inconsistent interaction representations, largely overlooks the structural distribution of tool-use trajectories, and relies on incompatible evaluation benchmarks. We present UniToolCall, a unified framework for tool learning that standardizes the entire pipeline from toolset construction and dataset generation to evaluation. The framework curates a large tool pool of 22k+ tools and constructs a hybrid training corpus of 390k+ instances by combining 10 standardized public datasets with structurally controlled synthetic trajectories. It explicitly models diverse interaction patterns, including single-hop vs. multi-hop and single-turn vs. multi-turn, while capturing both serial and parallel execution structures. To support coherent multi-turn reasoning, we further introduce an Anchor Linkage mechanism that enforces cross-turn dependencies. Furthermore, we convert 7 public benchmarks into a unified Query--Action--Observation--Answer (QAOA) representation with fine-grained evaluation at the function-call, turn, and conversation levels. Experiments show that fine-tuning Qwen3-8B on our dataset substantially improves tool-use performance. Under the distractor-heavy Hybrid-20 setting, achieves 93.0% single-turn Strict Precision, outperforming commercial models including GPT, Gemini, and Claude.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI assistants how to use “tools” (like a calculator, a calendar, a map, or any web API) in a consistent, reliable way. The authors build a unified system called UniToolCall that gives:
- one common format for how AIs should call tools,
- a large, carefully built set of practice data,
- and a fair, shared way to test how well different AIs use tools.
What questions did the researchers ask?
They focused on three simple questions:
- How can we make all tool calls look the same, so AIs trained on different data can learn better?
- How can we create practice problems that cover many kinds of tasks—quick one-step tasks, multi-step tasks, and longer conversations?
- How can we test AIs fairly, using the same rules, so we can compare different models properly?
How did they do it?
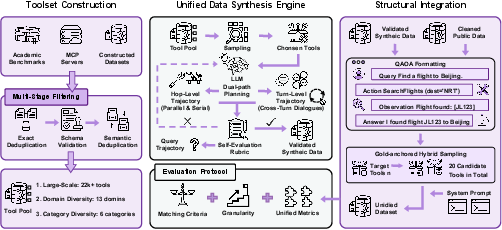
To solve these, they built a full pipeline—from gathering tools, to making training data, to evaluating models—using the same structure throughout.
Building a huge toolbox
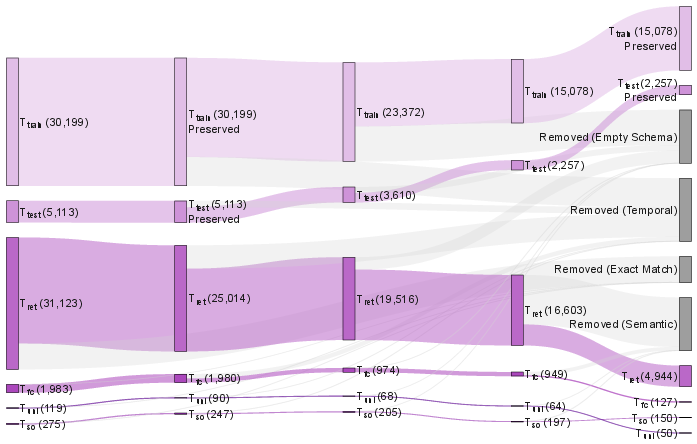
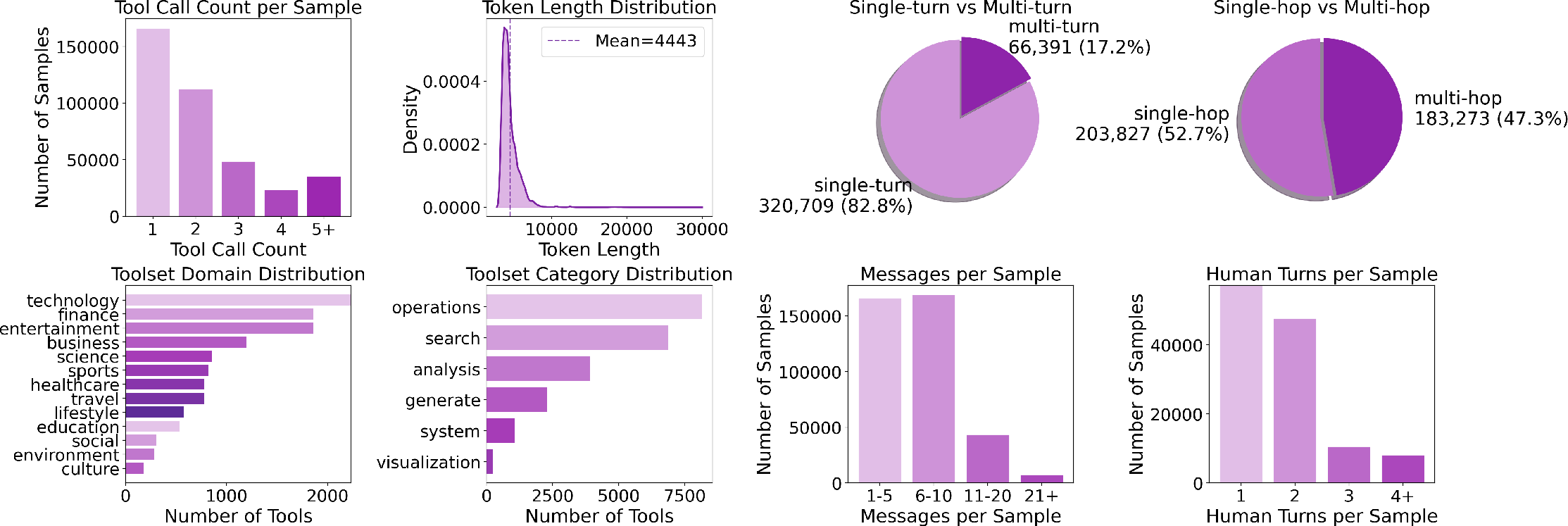
They collected over 22,000 “tools” (think: small apps/APIs that do specific jobs), organized by category (like “analysis” or “visualization”) and by topic (like finance or technology). All tools are written in the same format so they’re easy for AIs to understand.
Making practice problems with real structure
They created a big training set with about 390,000 examples by:
- Standardizing data from 10 public datasets.
- Adding synthetic (AI-generated) examples with tight quality checks.
These examples cover:
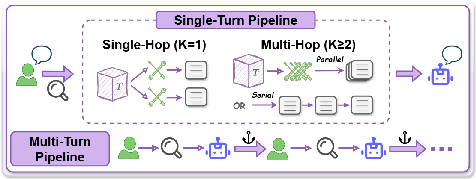
- Single-hop vs. multi-hop: one-step tasks vs. multi-step tasks.
- Single-turn vs. multi-turn: one question vs. a back-and-forth conversation.
- Serial vs. parallel execution: doing tools one after another (serial, like following a recipe) vs. doing independent calls at the same time (parallel, like washing and drying laundry with separate machines).
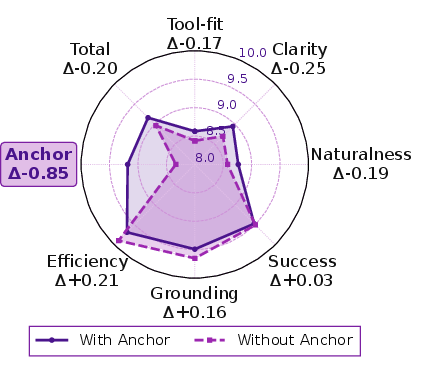
They also added an “Anchor Linkage” rule for multi-turn conversations: later messages must use important details produced earlier (like reusing an order ID from the previous step). This teaches the AI to “remember” and build on past results.
A simple, shared format (QAOA)
They turn every example into the same four-part pattern called QAOA:
- Query: the user’s request,
- Action: which tool the AI calls and with what inputs,
- Observation: the tool’s output,
- Answer: the AI’s final reply to the user.
Think of it like a lab report: question → what you did → what you saw → your conclusion.
A fair test and scoring system
They converted 7 public test sets into this same QAOA format and scored AIs at three levels:
- Function-call level: did the AI pick the right tool and fill in the details correctly?
- Turn level: did it get all needed calls right in this message?
- Conversation level: did it stay correct across the whole chat?
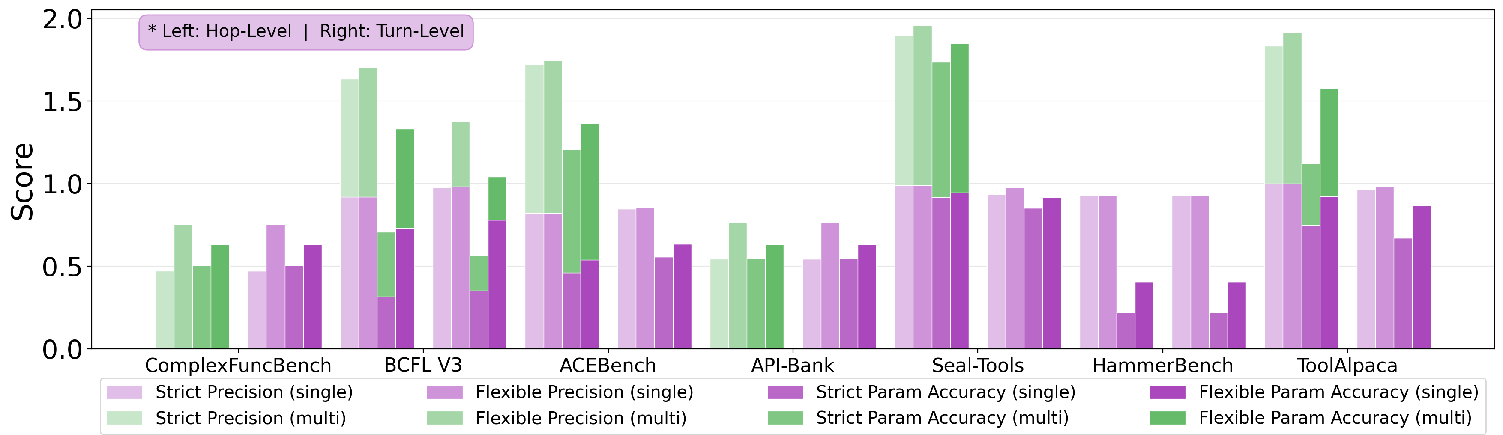
They tested both strict accuracy (everything exactly right) and flexible accuracy (mostly right, close matches allowed).
What did they find?
- Big jump in accuracy: After training on UniToolCall’s data, a mid-size open model (Qwen3-8B) became much better at choosing the correct tools and filling in the right details.
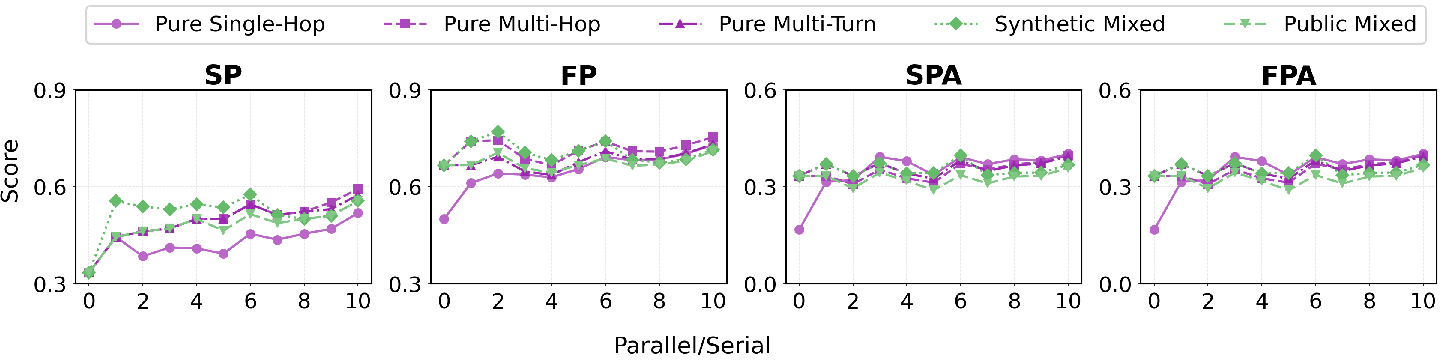
- Strong in “distractor” settings: In tests where the AI sees 20 possible tools (most are wrong), the model reached about 93% strict accuracy on single-turn tasks—better than several well-known commercial systems.
- Better parameters, not just tool names: The model also improved at providing the correct inputs to tools (like the right city name or date).
- Multi-turn remains hard: Long conversations with many dependencies are still challenging for all models, but the Anchor Linkage rule helped create better training data for this.
- Why synthetic data helps: Carefully designed synthetic examples were especially useful for learning serial, step-by-step reasoning, while public data offered broad coverage. Mixing both was best.
Why this matters
- For researchers and developers: A common “language” for tool use plus shared tests makes it easier to train, compare, and improve AI assistants fairly.
- For users: More reliable tool use means AI assistants that can correctly pick the right app and fill in the details—like booking travel, analyzing data, or fetching facts—without going off track.
- For the future: This framework is a foundation. It can be extended to longer tasks and real, live tools, helping build AI agents that handle complex, multi-step work more dependably.
Key terms in plain language
- Tool: A small program or API the AI can call (like a calculator or flight search).
- Function call: The AI’s “button press” to run a tool with specific inputs.
- Parameters: The details for a tool (e.g., city="Paris", date="2026-05-10").
- Single-hop vs. multi-hop: One-step vs. multi-step tasks.
- Turn: One back-and-forth message in a chat.
- Serial vs. parallel: In order (serial) vs. at the same time (parallel).
- Anchor Linkage: A rule that forces later steps to use important info from earlier steps (like a tracking number).
- Distractors (Hybrid-20): The AI sees 20 tool options; most are wrong. It must find the correct ones.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide future research.
- Real-world execution fidelity
- No evaluation with live tool execution; the framework does not model network latency, nondeterministic API responses, authentication, rate limits, versioning, or side effects. How do results change when tools are actually executed end-to-end under production constraints?
- Error handling and recovery (e.g., retries, backoff, partial failures) are not tested; how should agents be trained/evaluated for robustness to execution failures?
- Retrieval at realistic scale
- The Hybrid-20 setting fixes candidate lists to 20 tools with hard/easy negatives. How does performance scale when retrieving from the full 22k+ tool registry (or larger), or when candidate sizes vary (e.g., 50/100/1k)?
- Negative mining uses embedding similarity + random sampling; the effects of different negative sampling strategies (hard mining, adversarial negatives, domain-confusable tools) on both training and evaluation are not studied.
- Generalization to unseen tools and schemas
- The paper does not assess zero-shot generalization to unseen tools (new function names, novel argument schemas, missing/ambiguous docs) or to out-of-domain tool categories.
- Impact of documentation quality (e.g., sparse descriptions, synonyms, multilingual docs) on tool selection and argument generation remains untested.
- QAOA representation scope and limits
- QAOA assumes text-based inputs/outputs and JSON-structured calls; it does not cover multimodal tools (vision/audio), streaming I/O, binary/file artifacts, or complex/nested types with defaults and optional parameters. How can QAOA be extended to these cases?
- Observations are treated as text; there is no typed validation or schema for outputs, limiting rigorous argument grounding and state tracking.
- Multi-turn, long-horizon reasoning
- Multi-turn data are limited to T ∈ {2,3,4} and rely on adjacent-turn Anchor Linkage; longer-range dependencies (beyond adjacent turns), multi-session memory, and persistent tool state are not modeled.
- Strict conversation-level SP is 0.0 across many settings, suggesting either metric brittleness or model brittleness for long-horizon consistency. How can evaluation (and training) be redesigned for realistic, non-all-or-nothing multi-turn success?
- Anchor Linkage validation uses only 10 samples with an LLM rubric—too small to draw robust conclusions; larger, human-verified studies are needed.
- Parallel vs. serial execution realism
- While serial/parallel are modeled synthetically, there is no demonstration of concurrency hazards (e.g., race conditions, shared-state conflicts) or partial ordering constraints that arise in real systems.
- No measures of plan optimality (minimal calls, latency/cost), nor analyses of when parallelization is beneficial vs. harmful.
- Evaluation metrics and matching criteria
- Argument correctness uses rule-based exact match or ROUGE-L ≥ 0.7; this can misjudge structured arguments (types, units, formats) and fails to detect semantically wrong but lexically similar values. Type-aware, schema-aware, and execution-verified argument checks are missing.
- Strict conversation-level metrics are all-or-nothing; they may mask partial but meaningful success and can be overly punitive for long trajectories. More calibrated, task-centric success measures (e.g., end-state correctness, cost-aware success) are needed.
- Over/under-prediction trade-offs are not comprehensively analyzed; current macro-averaging and padding policies may bias results toward conservative predictions.
- Data generation and quality control
- Synthetic data are relatively small (2,937 instances) and generated/self-evaluated by Qwen3-32B—raising concerns of evaluator bias and family-specific artifacts. How do results change with independent evaluators/humans and larger synthetic corpora?
- The LLM-based rubric’s reliability (inter-rater agreement, calibration) and threshold sensitivity are not reported; failure modes of self-evaluation remain unclear.
- Mixing public and synthetic data helps, but the ideal mixing ratios and curricula (by domain, structure, difficulty) are not explored.
- Benchmark unification trade-offs
- Converting 7 heterogeneous benchmarks into QAOA may distort original task attributes; the paper acknowledges potential “evaluation distortion” but does not quantify it. Which phenomena are lost or altered by unification?
- Potential train-test leakage across standardized datasets and tool schemas is not rigorously ruled out (deduplication, near-duplicate tools/instructions, cross-split contamination).
- Tool retrieval and documentation integration
- The framework does not test document expansion/enrichment strategies for tool retrieval or parameter grounding (e.g., integrating tool manuals, examples, FAQs). How do doc quality and augmentation affect performance?
- Model scaling and transferability
- Only a LoRA-tuned Qwen3-8B is studied; scaling laws (8B → 32B → 70B), backbone diversity (non-Qwen families), and cross-backbone transferability of UniToolCall training are not examined.
- The impact of enabling explicit reasoning (CoT/tool-thinking) vs. reasoning-disabled inference is not analyzed, despite known trade-offs in tool-use accuracy and efficiency.
- Realistic tool ecosystems
- Authentication flows (OAuth), user identity, permissions, quotas, and privacy constraints are not modeled; these factors affect real agentic workflows and tool selection.
- Tool versioning and evolution (schema drift) are absent; robustness to API changes and automatic adaptation remains open.
- Safety, security, and robustness
- No adversarial evaluations: prompt injection via tool outputs, malicious/poisoned tools, data exfiltration risks, or jailbreak attempts during tool use.
- No calibration or abstention testing (knowing when not to call tools, or when to escalate/seek clarification).
- Multilingual and multimodal coverage
- All experiments appear monolingual; cross-lingual tool queries and multilingual tool metadata are untested.
- Multimodal tool usage (images, audio, video) is not represented in data or evaluation.
- Reproducibility and release details
- Exact tool registry release status (22k+ tools), licensing constraints, and full conversion/matching scripts are not detailed; formatting/notation inconsistencies in the text (e.g., unclosed math, section typos) may impede replication.
- Benchmark-specific per-domain gaps (e.g., underrepresented domains or categories) are not quantified; per-domain failure analyses are limited.
- Planning and learning paradigms
- The approach is purely supervised fine-tuning; outcome-based learning (e.g., RL, DPO, reward models like ToolRM) and planning-aware objectives are not explored.
- Decision policies for when to use which tools, how many steps to take, and when to stop are not explicitly optimized or evaluated beyond call-level correctness.
- Open design choices
- Impact of candidate-list composition (e.g., domain-balanced, functionally similar distractors, aliasing/synonyms) on selection and parameter accuracy is not characterized.
- The effect of extremely long contexts (>8192 tokens), large observation payloads (documents/DB dumps), and truncation strategies on multi-turn success is unknown.
Practical Applications
Overview
The paper introduces UniToolCall, a unified framework to standardize tool-use for LLM agents across representation (QAOA), data (22k+ tools; 390k+ instances with controlled structures), and evaluation (fine-grained, comparable metrics). Its contributions enable practical gains in tool selection/parameter generation, especially under realistic retrieval noise (Hybrid-20), and make it feasible to build interoperable, testable, and better-performing tool-using agents.
Below are concrete applications derived from the framework’s findings and methods, organized by immediacy and linked to sectors, potential products/workflows, and key dependencies.
Immediate Applications
These can be deployed now using the released representation, data, and evaluation protocol, with modest integration work.
- Agent tool standardization and interoperability
- Sectors: Software, enterprise IT, platforms
- What: Adopt UniToolCall’s JSON Schema tool format and QAOA interaction logs to normalize function-calling across tool chains, vendors, and agent frameworks (e.g., MCP-compatible servers, OpenAPI-based services).
- Tools/products/workflows: “Agent-Ready Tool Converter” (OpenAPI/Swagger → UniToolCall JSON Schema + taxonomy); “QAOA Logger” middleware in LangChain/LlamaIndex/agent platforms.
- Dependencies/assumptions: Access to API specs; willingness to map existing tools into the UniToolCall taxonomy; governance on versioning.
- Unified evaluation in CI/CD for agent systems
- Sectors: MLOps, QA, platform engineering
- What: Integrate SP/FP/SPA/FPA metrics at function/turn/conversation levels as regression tests to catch tool-selection and argument errors before deployment.
- Tools/products/workflows: “QAOA Evaluator” CLI/SDK; GitHub Actions to run Hybrid-20 tests; dashboards for per-tool and per-turn failure modes.
- Dependencies/assumptions: Test suites covering target tools; ability to simulate or mock tool responses.
- Retrieval stress-testing and tuning for tool calling
- Sectors: Search/RAG platforms, agent routing
- What: Use the Hybrid-20 setup (ground-truth + hard/easy negatives) to benchmark and tune tool retrieval/ranking so agents remain robust to distractors.
- Tools/products/workflows: Retrieval ablation harness; hard-negative mining based on embeddings; feature toggles to evaluate different retrievers.
- Dependencies/assumptions: Embedding models for negative mining; standardized tool corpora with descriptions.
- Domain-specific dataset augmentation for tool use
- Sectors: Finance, healthcare, e-commerce, operations
- What: Generate structurally controlled synthetic trajectories (single/multi-hop, serial/parallel, multi-turn with Anchor Linkage) to augment scarce logs and fine-tune small models (e.g., 8B) for higher fidelity tool use.
- Tools/products/workflows: “Dataset Synthesis Studio” with task templates (e.g., KYC→account creation→transfer); LoRA fine-tuning pipelines; targeted curriculum mixing.
- Dependencies/assumptions: Representative tool schemas and safe mock data; data governance for synthetic corpora; compute for fine-tuning.
- Internal tool catalog curation and discoverability
- Sectors: Enterprise IT, API management
- What: Organize tools by UniToolCall’s functional categories and domains to improve sampling balance and retrieval; identify gaps or redundancy in tool portfolios.
- Tools/products/workflows: Catalog dashboards; taxonomy tagging; automated linting for missing argument docs or inconsistent schemas.
- Dependencies/assumptions: Tool inventory access; buy-in from API owners for upkeep.
- Agent red teaming and failure pattern analysis
- Sectors: Security, compliance, risk
- What: Use unified strict/flexible metrics and distractor-heavy tests to probe misrouting (wrong tool) vs. misgrounding (wrong arguments), across turns and conversations.
- Tools/products/workflows: “Tool-Use Red Team Pack” with adversarial candidates; auto-reporting on failure clusters by tool category/domain.
- Dependencies/assumptions: Red-team policies; safe mocks for sensitive tools; monitoring to prevent live side effects.
- Teaching and reproducible research on tool-using agents
- Sectors: Academia, edtech
- What: Leverage the QAOA format and unified benchmarks for assignments, competitions, and cross-dataset comparisons on tool-use structures and retrieval robustness.
- Tools/products/workflows: Course kits; reproducible leaderboards; ablation templates (serial vs. parallel) for student projects.
- Dependencies/assumptions: Access to open models and GPUs; institutional policies on synthetic data.
- Higher-precision function-calling assistants (single-turn focus)
- Sectors: Customer support, IT ops, developer tools
- What: Deploy smaller, fine-tuned agents for single-turn or short single-turn tasks (e.g., ticket lookup, build/test command generation) with improved strict tool selection and parameter accuracy.
- Tools/products/workflows: Command/CLI copilot; ticket triage bot; internal knowledge agents invoking search/BI tools.
- Dependencies/assumptions: Guardrails to avoid unsafe calls; logging via QAOA for audits; clearly specified tools.
- Personal productivity assistants with structured tool use
- Sectors: Daily life, prosumer apps
- What: Use the framework to fine-tune small local models for accurate calendar/email/maps function calls; employ Hybrid-20-like checks to vet plugin catalogs.
- Tools/products/workflows: Local “tool-use” packs for calendars/emails; QAOA-based telemetry to improve agents over time.
- Dependencies/assumptions: Privacy-preserving local deployment; connectors for consumer APIs; minimal-context workflows (due to current context-length limits).
Long-Term Applications
These require further research, scaling, safety validation, or integration with live systems (especially multi-turn, long-horizon, and safety-critical use).
- Certified live-tool execution and safety audits
- Sectors: Policy/regulation, critical infrastructure, finance, healthcare
- What: Evolve unified metrics into certification criteria for agents that execute real operations (e.g., trades, orders, control actions). Use QAOA logs for auditability.
- Tools/products/workflows: Compliance test suites; third-party certs for SP/SPA thresholds; audit trails mapped to QAOA.
- Dependencies/assumptions: Regulatory frameworks recognizing such metrics; standardized logging in production; incident response protocols.
- End-to-end autonomous workflow orchestration with state continuity
- Sectors: Healthcare (prior authorization, care coordination), finance (loan origination, KYC-to-transfer), logistics (order-to-cash)
- What: Build multi-turn, long-horizon agents that reliably carry forward state (IDs, tokens) across steps using Anchor Linkage–like mechanisms to reduce context drift.
- Tools/products/workflows: Workflow planners that enforce state dependencies; cross-system credentials/state stores; human-in-the-loop checkpoints.
- Dependencies/assumptions: Stronger multi-turn reliability (conversation-level strict still low); longer context windows; robust state management; privacy controls.
- Tool marketplace readiness scoring and discovery
- Sectors: API ecosystems, SaaS marketplaces, MCP servers
- What: Create a “tool readiness score” (retrievability, schema clarity, parameter grounding performance) to rank and certify marketplace tools for agent use.
- Tools/products/workflows: Tool linting/scoring service; search ranking by readiness; badges for “Agent-Ready.”
- Dependencies/assumptions: Broad adoption of JSON Schema and metadata; governance for scoring fairness; feedback loops from production usage.
- Formal verification and semantic guarantees for tool parameters
- Sectors: Safety-critical ops, finance, industrial control
- What: Combine UniToolCall’s structured evaluation with symbolic checks or contracts to guarantee preconditions/postconditions of tool invocations.
- Tools/products/workflows: Contract-based tool specs; pre-execution validators; postcondition monitors integrated with QAOA traces.
- Dependencies/assumptions: Formalizable tool semantics; cost-effective runtime checks; performance overhead budgets.
- Robotics skill orchestration via tool-use analogs
- Sectors: Robotics, manufacturing, warehousing
- What: Map “tools” to robot skills/services; use serial/parallel planning and Anchor Linkage for skill composition and stateful tasks.
- Tools/products/workflows: ROS/MoveIt adapters to QAOA; simulation-to-reality pipelines for skill testing; mixed parallel/serial execution graphs.
- Dependencies/assumptions: Real-time constraints; safety interlocks; sim fidelity; alignment between function-call schemas and robot APIs.
- Energy and industrial automation agents
- Sectors: Energy, utilities, process industries
- What: Agents orchestrating telemetry queries and control commands with strict parameter and sequencing requirements (e.g., SCADA-like constraints).
- Tools/products/workflows: Digital twins as “tools” with verified schemas; conservative controllers with rollback; operator-in-the-loop.
- Dependencies/assumptions: High assurance levels; latency and reliability guarantees; regulatory oversight.
- Cross-lingual and multimodal tool-use generalization
- Sectors: Global platforms, accessibility, media
- What: Extend the unified representation and evaluation to multilingual tool descriptions and multimodal arguments/observations (e.g., images, PDFs).
- Tools/products/workflows: Doc expansion for multilingual retrieval; multimodal argument validators; adapted metrics for multimodal similarity.
- Dependencies/assumptions: Multilingual/multimodal training data; updated matching criteria; tool schemas with modality-aware fields.
- Retrieval-augmented tool learning and documentation optimization
- Sectors: Documentation platforms, devrel, API publishers
- What: Co-train retrieval and tool-use with synthetic hard negatives and doc expansion to improve tool discoverability and correct invocation.
- Tools/products/workflows: “ToolDoc Optimizer” that expands/clarifies descriptions; retrieval-feedback loops tied to SP/SPA uplift.
- Dependencies/assumptions: Infrastructure for continuous evaluation; editorial oversight for doc changes; alignment with branding/legal constraints.
- Long-horizon planning with memory and larger models
- Sectors: Complex enterprise workflows, scientific assistants, legal tech
- What: Scale to 30B–70B+ backbones and longer contexts for deeply nested, multi-session workflows with richer observations (e.g., large documents, DB outputs).
- Tools/products/workflows: Memory stores keyed by Anchor variables; episodic planning; chunked QAOA with compression.
- Dependencies/assumptions: Compute/budget; memory safety; reliable chunking/grounding; improved conversation-level strict performance.
- Safety and governance policy templates for tool-using agents
- Sectors: Public sector, corporate compliance
- What: Draft policy templates that reference standardized metrics (e.g., SP/SPA thresholds for deployment in sensitive departments) and require QAOA audit logs.
- Tools/products/workflows: Governance checklists; procurement requirements; internal policy frameworks referencing UniToolCall-style evaluation.
- Dependencies/assumptions: Policy adoption cycles; consensus on thresholds; secure storage and access control for logs.
Notes on feasibility across applications:
- Performance depends on retrieval quality and candidate lists; production retrieval must approximate Hybrid-20 rigor.
- Multi-turn, long-horizon reliability still lags; critical workflows need human oversight and conservative rollout.
- Mapping proprietary APIs to JSON Schema and maintaining high-quality tool docs is a prerequisite to realize benefits.
- Safety, privacy, and regulatory compliance (especially in healthcare/finance/energy) require additional safeguards beyond the presented evaluation.
Glossary
- AdamW: An Adam optimizer variant that decouples weight decay from the gradient update to improve generalization. "using AdamW with a learning rate of "
- Anchor Linkage mechanism: A constraint that forces later dialogue turns to reference concrete state produced in earlier turns, ensuring cross-turn coherence. "we further introduce an Anchor Linkage mechanism that enforces cross-turn dependencies."
- bfloat16: A 16-bit floating-point format with a wider exponent than FP16, enabling efficient training with large dynamic range. "We use bfloat16 precision throughout training."
- Conversation-level: Evaluation aggregated over the entire multi-turn dialogue, not just individual turns or calls. "Conversation-level: For single/multi-turn scenarios, we compute metrics across the entire dialogue trajectory."
- DeepSpeed: A distributed training and optimization library for accelerating large-scale model fine-tuning and inference. "We employ the LLaMA-Factory framework integrated with DeepSpeed optimization"
- distractor-heavy: A setting where many irrelevant candidate tools are present, making selection harder. "Under the distractor-heavy Hybrid-20 setting, UniToolCall achieves 93.0\% single-turn Strict Precision,"
- easy negatives: Randomly chosen obviously-incorrect candidate tools used as simpler distractors during evaluation or training. "and appending 5 random easy negatives to yield exactly 20 candidates"
- embedding similarity: A vector-space similarity measure used to retrieve semantically similar (often confusable) items. "retrieving top-ranking hard negatives via embedding similarity"
- Flexible Parameter Accuracy (FPA): A metric that credits correct tool arguments via exact or semantic (e.g., ROUGE-L) matching. "Flexible Parameter Accuracy (FPA)"
- Flexible Precision (FP): A metric that measures the proportion of predicted tool names that match the ground truth, allowing partial credit. "Flexible Precision (FP)"
- Function call-level verification: The finest-grained evaluation unit that checks each individual tool invocation’s name and arguments. "Function call-level verification"
- Ground Truth (GT) setting: An evaluation mode where the candidate list contains only the true tools required, removing distractors. "We additionally report results under the Ground Truth (GT) setting, in which the candidate list contains only the required target tools."
- hard negatives: Confusable candidate tools retrieved to be similar to the correct ones, increasing selection difficulty. "retrieving top-ranking hard negatives via embedding similarity"
- Hybrid-20 setting: A standardized candidate list of exactly 20 tools combining ground-truth, hard negatives, and easy negatives. "Our main evaluation is conducted under the Hybrid-20 setting"
- JSON Schema: A JSON-based formalism used to standardize tool signatures and arguments across sources. "All tools are standardized into a unified JSON Schema format."
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning method that inserts trainable low-rank adapters into layers. "Training is conducted with LoRA~\cite{hu2022lora}."
- LLaMA-Factory: A training framework/tooling used here to fine-tune LLMs with integrations like DeepSpeed. "We employ the LLaMA-Factory framework integrated with DeepSpeed optimization"
- MCP servers: Servers implementing the Model Context Protocol, exposing tools/APIs for agent interaction. "the toolset is formed from three primary sources: (1) Academic benchmarks, (2) MCP servers, and (3) Constructed datasets."
- multi-hop: Tasks or trajectories requiring two or more tool calls in sequence (or coordinated in parallel) to complete. "including single-hop vs. multi-hop and single-turn vs. multi-turn,"
- multi-turn: Dialogues spanning multiple user–agent turns, often requiring state tracking across turns. "including single-hop vs. multi-hop and single-turn vs. multi-turn,"
- parallel execution: An execution pattern where multiple tool calls are invoked concurrently within a step. "while capturing both serial and parallel execution structures."
- parametric knowledge: Information stored in a model’s parameters rather than fetched from external tools or data sources. "extending their capabilities beyond parametric knowledge"
- Query--Action--Observation--Answer (QAOA) representation: A unified schema encoding user queries, tool actions, resulting observations, and final answers. "we convert 7 public benchmarks into a unified Query--Action--Observation--Answer (QAOA) representation"
- ROUGE-L: A text similarity metric based on the longest common subsequence, used here for semantic argument matching. "We calculate the ROUGE-L similarity score between the prediction and the reference."
- rule-based matching: Deterministic, exact matching rules for validating predicted tool names and arguments. "Rule-based matching: Serving as the primary strategy, this method achieves exact matching through rigorous standardization"
- semantic matching: A non-exact matching approach that judges correctness via similarity scores rather than exact string equality. "Semantic matching: We calculate the ROUGE-L similarity score between the prediction and the reference."
- serial execution: An execution pattern where tool calls are invoked one after another, creating inter-step dependencies. "while capturing both serial and parallel execution structures."
- self-evaluation: An automatic quality-control step where an LLM judges its own generated trajectories against a rubric. "$D_{\text{syn}$ is filtered using an LLM-based self-evaluation framework using six core metrics"
- Strict Parameter Accuracy (SPA): A stringent metric requiring both tool name and all argument values to match exactly. "Strict Parameter Accuracy (SPA)"
- Strict Precision (SP): A stringent metric that requires every predicted tool name to perfectly match the ground truth. "Strict Precision (SP)"
- Turn-level: Evaluation aggregated per dialogue turn, suitable for single- or multi-hop within a turn. "Turn-level: For single/multi-hop scenarios, we compute metrics across individual dialogue turns."
- Two-Stage planning mechanism: A generation process that first plans at the episode level, then refines intent at the turn level. "Generation requires a Two-Stage planning mechanism (episode-level storyline followed by turn-level intent)."
- warmup ratio: The fraction of training steps used to gradually increase the learning rate from zero to its target value. "a warmup ratio of $0.03$"
Collections
Sign up for free to add this paper to one or more collections.