- The paper introduces EagleVision, a LiDAR-centric benchmark for 3D detection and trajectory prediction in high-speed autonomous racing.
- It demonstrates that domain-aligned real data pretraining outperforms simulation-only approaches for robust cross-domain perception.
- The study highlights the importance of motion coverage and sensor alignment for effective domain adaptation in extreme racing dynamics.
EagleVision: A Multi-Task Benchmark for Cross-Domain Perception in High-Speed Autonomous Racing
Introduction and Motivation
Autonomous racing presents extreme challenges for perception systems, characterized by high velocities, aggressive dynamic maneuvers, and pronounced domain mismatch with urban driving scenarios. While urban datasets such as KITTI, nuScenes, and Waymo Open have propelled advances in urban perception tasks, their domain coverage, annotation protocols, and environmental conditions are fundamentally misaligned with high-speed, low-structure racing environments. The absence of large-scale, rigorously annotated, and standardized benchmarks for autonomous racing perception constrains both research progress and benchmarking reproducibility in this regime.
This paper introduces EagleVision, a unified LiDAR-centric, multi-task benchmark designed to fill these gaps by providing standardized 3D detection and trajectory prediction annotations across real and simulated high-speed racing domains. The dataset curation spans three sources: manually labeled Indy Autonomous Challenge data (I), annotated A2RL competition data (R), and synthetically generated A2RL Simulator data (S). The unified annotation format (SUSTechPOINTS) ensures protocol consistency for cross-domain evaluation, supporting fine-grained analysis of domain adaptation, transfer learning, and generalization under extreme dynamics.
Dataset Construction and Structure
EagleVision consolidates approximately 28,000 annotated frames, with each domain offering complementary challenges:
- Indy Autonomous Challenge (I): 14,893 frames, Luminar Iris 360° LiDAR, focused on single-vehicle racing scenarios.
- A2RL Simulator (S): 12,000 frames, matching competition sensor setups, multi-agent settings, and perfect ground-truth.
- A2RL Real (R): 1,163 frames, three high-fidelity Seyond Falcon Ultra LiDARs, real-world competitive data with sensor imperfections.
All labels are normalized under a 3D bounding box PSR schema with ego-vehicle frame referential, considering a single "Car" semantic class. Trajectory prediction annotations provide synchronized global pose data for high-fidelity forecasting.

Figure 1: Autonomous racing platform operating under real A2RL competition.
The diverse sensing platforms and annotation protocols capture the unique domain shifts between urban, synthetic, and real racing regimes, including differences in object multiplicity, LiDAR density, and acquisition rates.
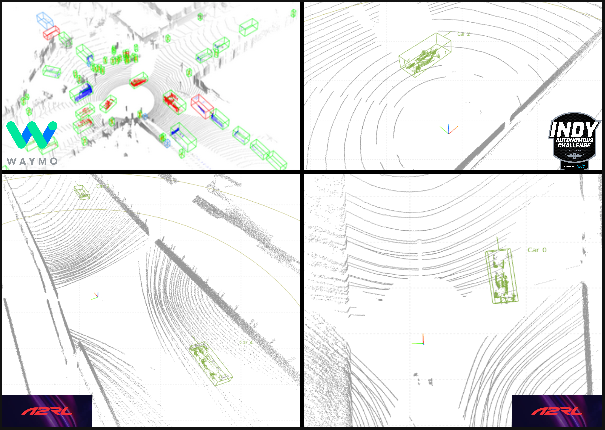
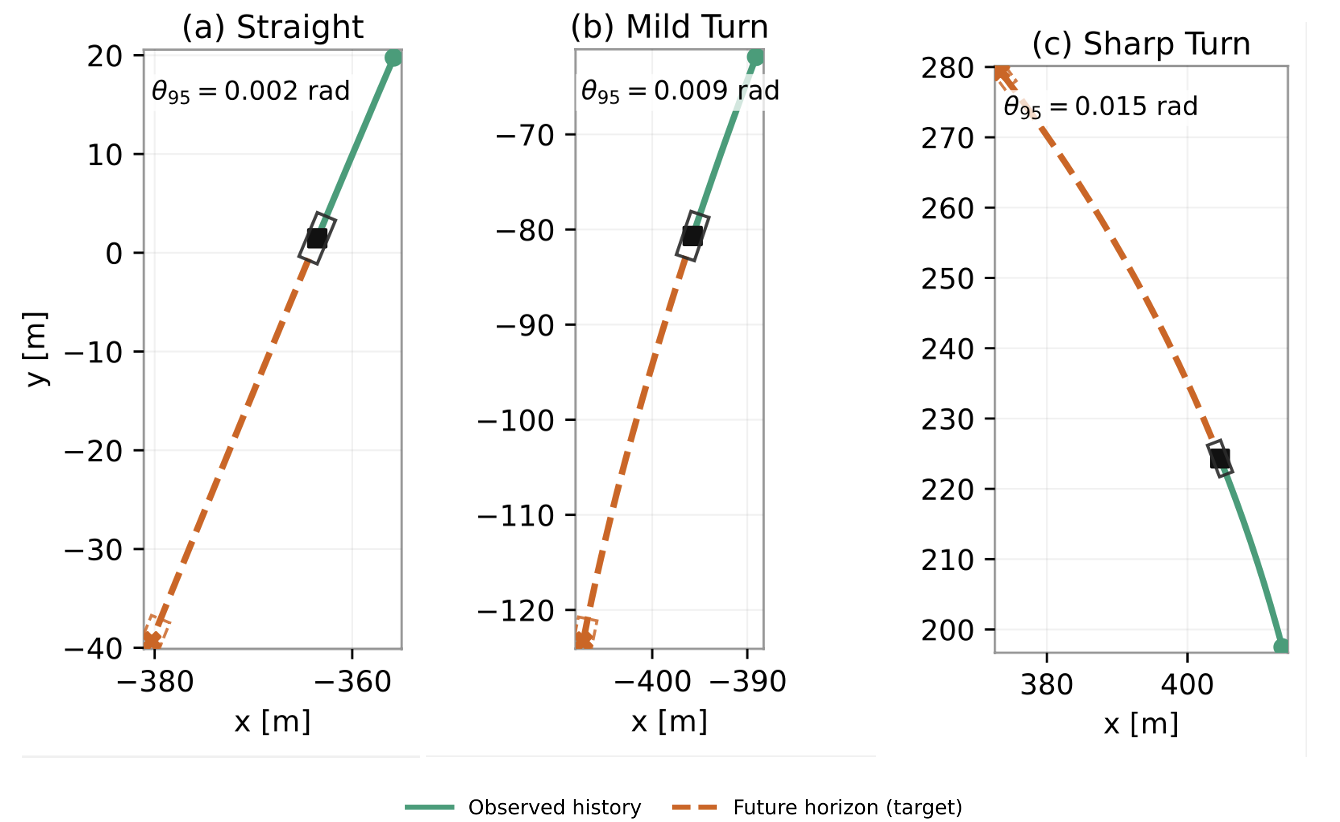
Figure 2: Detection datasets and representative LiDAR annotations.
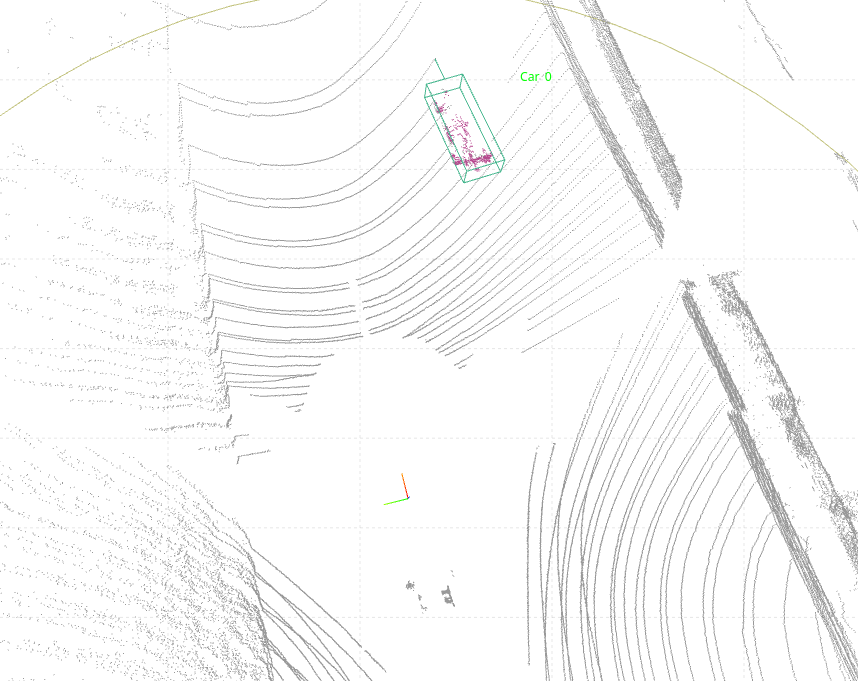
Figure 3: LiDAR point cloud visualization of 3D detection result on A2RL Real.
Benchmarking Protocols and Baselines
EagleVision establishes a unified multi-task benchmark protocol. The two primary tasks are:
- 3D Detection: Localization of vehicles via oriented bounding boxes, evaluated with AP, Average Translation Error (ATE), Average Scale Error (ASE), Average Orientation Error (AOE), and a reduced nuScenes Detection Score (NDS).
- Trajectory Prediction: Short-horizon (1s) multi-agent prediction using encoder-decoder LSTM baselines, assessed via ADE and FDE.
The transfer protocol involves combinations of urban-scale (Waymo) pretraining, real/simulated racing intermediate adaptation, and racing-only finetuning to dissect the value of each source domain.
Cross-Domain Generalization and Experimental Results
Quantitative results on the A2RL Real test set reveal several critical insights:
- Urban Pretraining Impact: Waymo initialization leads to NDS=0.722 on R, compared to $0.693$ when trained from scratch. Generic 3D geometric features prelearned on urban scenes accelerate adaptation to racing conditions despite appearance and distribution shifts.
- Simulator vs. Real Racing: Pure simulator-based pretraining does not match the gains obtained from real racing data. For instance, W→I10→R achieves the highest NDSR0, surpassing both scratch and simulator-only strategies.
- Multi-Domain Pretraining: Strategies that combine synthetic scale with real-world dynamics—especially staged (R1 followed by R2 and then R3)—yield stable, robust detection performance.
For the trajectory prediction task, training on the larger and more dynamically varied Indy domain enables superior cross-domain generalization to A2RL test sequences. Notably, the Indy-trained model outperforms the in-domain A2RL baseline (FDER4 vs. R5), a consequence of richer motion coverage trumping smaller, domain-matched splits.
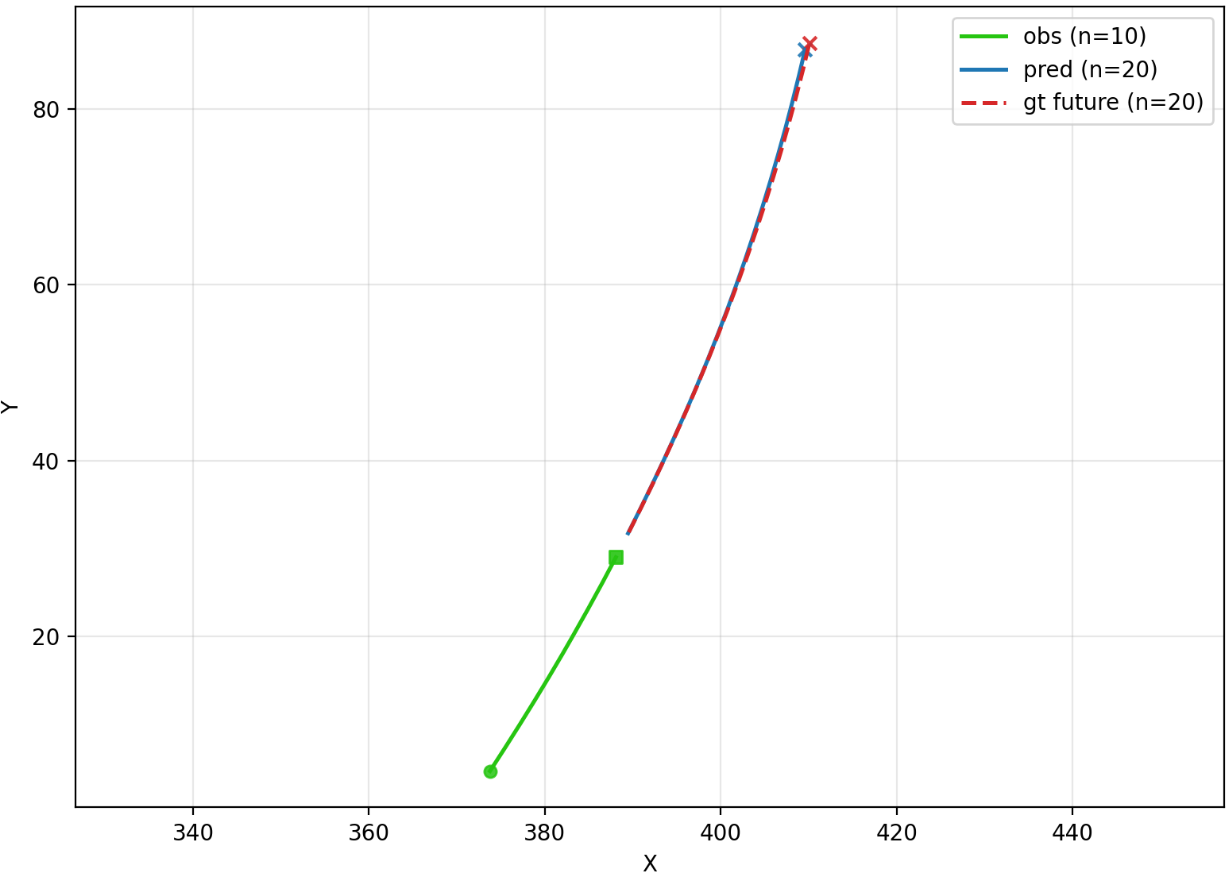
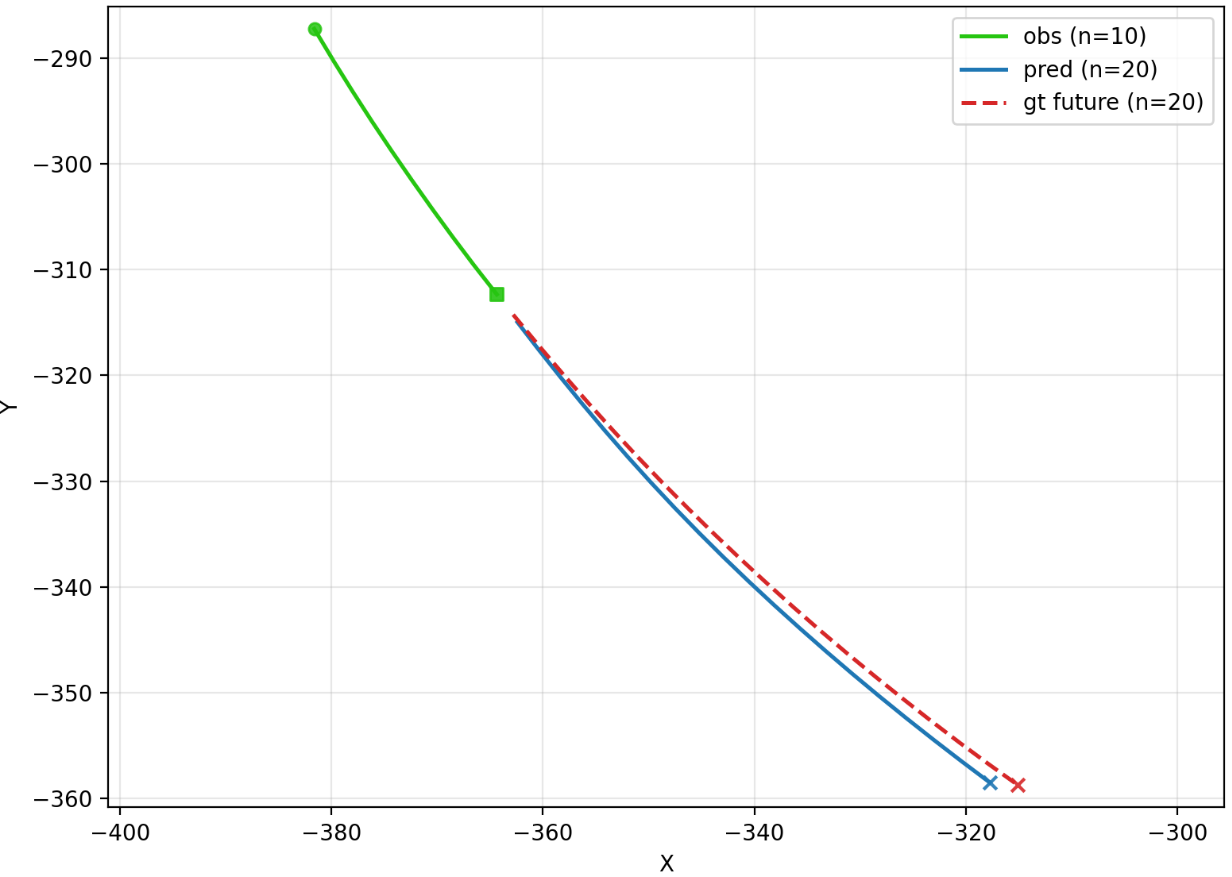
Figure 4: Representative trajectory prediction examples from the R6 training setup, indicating observed histories and predicted future trajectories.
Analysis of Strong Claims and Limitations
A core claim supported by the numerical evaluation is that domain similarity dominates dataset scale in cross-domain racing perception—an observation that contradicts the generalized trend in urban detection benchmarks, where scale typically drives transfer. Furthermore, pretraining with real racing data delivers stronger adaptation than synthetic simulation exposure, even after extensive augmentation, underscoring the presence of subtle sim-to-real gaps not captured in LiDAR geometry alone.
Still, performance is bottlenecked by the size of R7, the restriction to a single semantic class, and the absence of velocity or attribute annotations. The benchmark, unlike comprehensive urban datasets, cannot yet support fine-grained reasoning over the full semantic space or high-level dynamic events.
Practical and Theoretical Implications
From a practical standpoint, EagleVision provides the first rigorous baseline for high-speed cross-domain transfer in 3D autonomous racing perception. This enables fair benchmarking for new adaptation strategies and supports reproducible research in sim-to-real and domain generalization for LiDAR-centric robotic autonomy.
Theoretically, the results reinforce that motion distributional coverage and domain alignment are foundational for robust forecasting and detection under regime shifts. The findings motivate research into geometry-aware adaptation, temporal attention across high-dynamic regimes, and architecture designs that explicitly model uncertainty propagation due to velocity and acceleration extremes.
Outlook and Future Work
EagleVision delineates essential directions for advancing high-speed autonomy:
- Domain-bridging adaptation: Improved adaptation methods that exploit both geometric and dynamic invariances.
- Multi-task and multi-agent architectures: Unified models for detection-prediction, incorporating agent interactions and raw sensory fusion.
- Dataset expansion: Increasing the real racing data scale, diversifying semantic classes, and introducing additional sensor modalities (e.g., radar, high-frequency GPS).
- Fine-grained task protocols: Velocity, intent, and behavior prediction tasks aligned with real race event semantics.
Conclusion
EagleVision provides a uniquely structured foundation for high-speed, LiDAR-based perception benchmarking across urban, simulated, and real racing environments. Results establish that domain-aligned real data adaptation and rich motion coverage are central for robust generalization under extreme dynamics. The benchmark and public release will catalyze research in cross-domain adaptation, perception robustness, and the autonomy stack for high-speed robotics.

