- The paper introduces a novel multi-layer decoupling framework using tensor decomposition via ParaTuck-L factorization for improved system identification and network compression.
- It devises CMTF algorithms and adaptive bilevel optimization routines that achieve low error rates (10⁻³ to 10⁻²) on synthetic and benchmark tasks.
- Empirical evaluations on Silverbox, MNIST, and FashionMNIST demonstrate the method’s robustness, scalability, and potential for significant parameter savings.
Tensor-based Multi-layer Decoupling: Theory, Algorithms, and Applications
Introduction and Problem Setting
The decoupling of multivariate nonlinear mappings into sequences of linear transformations and univariate nonlinearities underpins diverse paradigms in system identification and neural representation. Canonical Polyadic Decomposition (CPD)-based techniques enable such decoupling for the single-layer case; extending these methods to multi-layer architectures, both for theoretical and applied contexts, demands significant advances in tensor algebra and computational methods.
Decoupled forms, as in
f(x)=W1g(W0x),
have seen wide usage for system identification, model order reduction, and neural network compression. However, single-layer decoupling is fundamentally limited in expressivity under strict parameter budgets. Deep or multi-layer architectures—prevalent in state-of-the-art deep learning—motivate a systematic extension of decoupling methods beyond the CPD paradigm.
This paper establishes the formalism and practice for multi-layer tensor-based decoupling, linking the structure of Jacobian tensors to ParaTuck-L tensor decompositions. It further devises constrained coupled matrix–tensor factorization (CMTF) algorithms and adaptive bilevel optimization routines for parameter estimation, with rigorous evaluation on synthetic and benchmark tasks.
Mathematical Foundation: From CPD to ParaTuck-L
The CPD of a third-order tensor forms the algebraic backbone of the single-layer decoupling problem. In the multi-layer scenario, the Jacobian tensor loses its CPD structure and instead adheres to a ParaTuck-L decomposition.
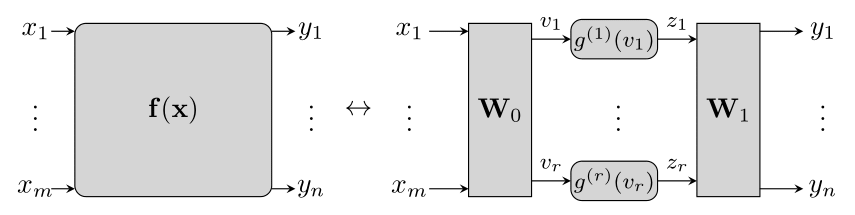
Figure 1: The single-layer decoupling problem, which is recoverable via CPD of a third-order Jacobian tensor.
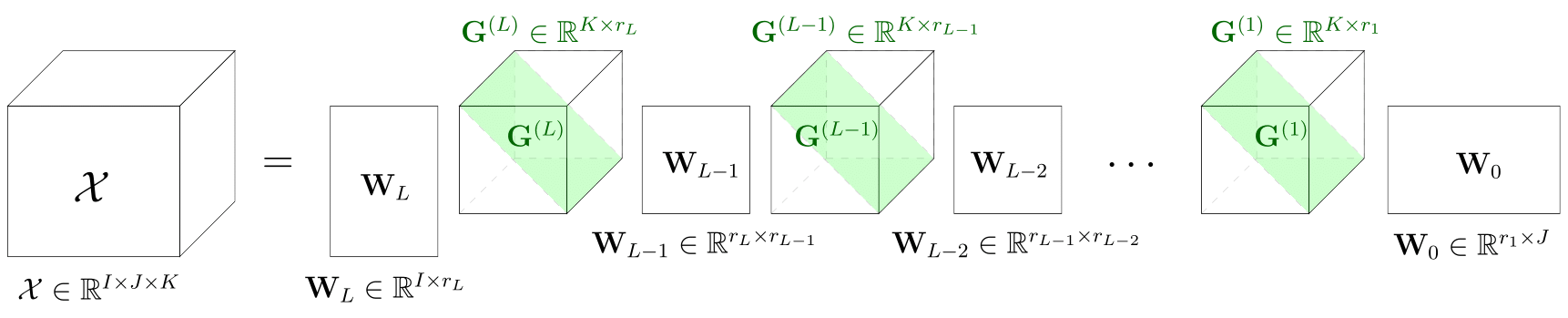
Figure 2: Visualization of the ParaTuck-L decomposition, which generalizes CPD and encodes the inter-layer structure induced by multi-layer compositions.
Formally, the L-layer decoupled model writes as
f(x)=WLgL(WL−1gL−1(…W1g1(W0x)…)).

Figure 3: The multi-layer decoupling problem—recovery of the entire sequence of linear maps and univariate nonlinearities from multivariate input-output data.
The derivative structure of f implies that, stacking Jacobians across input samples, the resulting third-order tensor admits a ParaTuck-L factorization, where each G(ℓ) directly encodes the derivatives of the internal activations per layer. This critical observation allows recasting multi-layer decoupling as a constrained tensor decomposition task.
The paper provides detailed analysis of ambiguities in ParaTuck-L (scaling, permutation, slice-wise ambiguities), and proves that these can—under mild assumptions—be appropriately handled by suitable basis selection and bias propagation.
Parameterization and Basis Selection
The work adopts parametric representations for the internal univariate nonlinearities:
L0
where L1 are typically monomials, chosen for their analytic properties and scale-invariance, ensuring the model's expressivity is robust to the unavoidable scaling ambiguities arising from tensor decomposition.
A series of theorems establish that bias terms in all but the final layer can be propagated and handled by the last layer, enabling effective constraint enforcement and parameter estimation without loss of representational power for analytic and especially polynomial bases.
Algorithms: CMTF with Alternating Updates and Bilevel Optimization
To address the intrinsic nonidentifiability and numerical instability in unconstrained ParaTuck decomposition, the paper proposes two main algorithmic variants:
- PROJ-CMPT-L2: Sequential unconstrained least-squares updates, followed by projection onto the constraint space determined by the chosen basis structure.
- CONSTR-CMPT-L3: Direct optimization over the expansion coefficients, with the constraints incorporated explicitly in the least-squares updates.
A key innovation is the combination of first-order (Jacobian) and zeroth-order (function) information through a coupled matrix–tensor factorization. This ensures reliable recovery of both activation derivatives and offsets.
For tuning the regularization hyperparameter L4 controlling the tradeoff between fitting derivatives and values, a bilevel adaptive scheme is deployed, using validation metrics relevant to the ultimate task (e.g., regression error, neural network accuracy).
Empirical Evaluation
The proposed framework undergoes extensive empirical validation:
- Synthetic Examples: Both PROJ and CONSTR variants achieve mean relative errors on Jacobian and function values in the L5 to L6 range and sub-1% output RMSE on synthetic polynomials, demonstrating reliable recovery.
- System Identification (Silverbox PNARX): On the Silverbox benchmark, both TS-PROJ-CMPT-1 and TS-CONSTR-CMPT-1 attain model approximation errors near or below 1% (median values) and simulation errors comparable to state-of-the-art nonparametric decoupling methods. The TS-CONSTR-CMPT-1 is particularly stable, with minimal gap between mean and median.
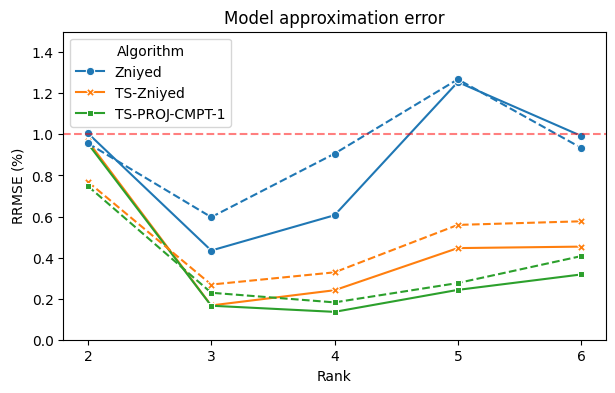
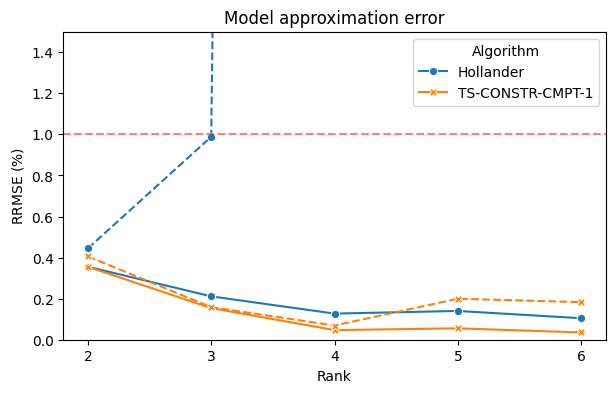
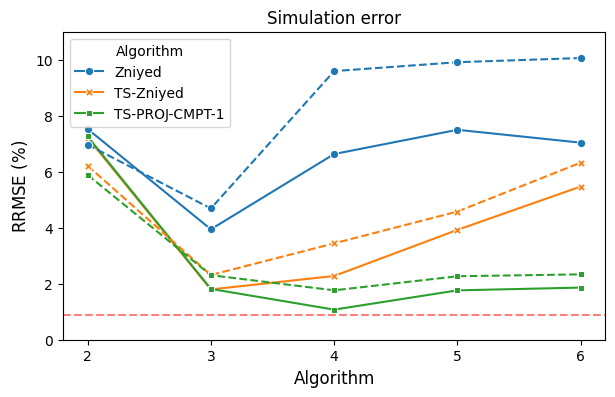
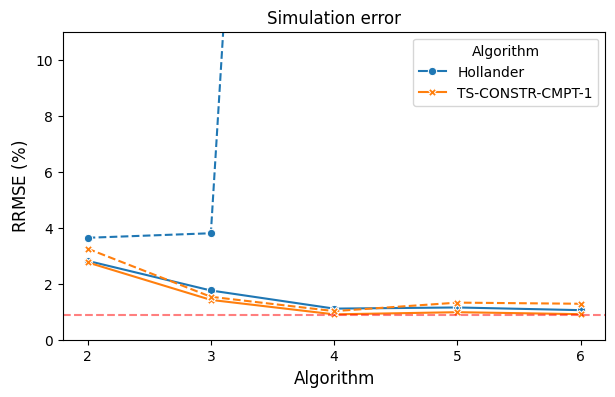
Figure 4: Comparative results (mean and median) for model and simulation error on Silverbox data, evidencing the improved stability and accuracy of the TS-PROJ-... and TS-CONSTR-... algorithms.
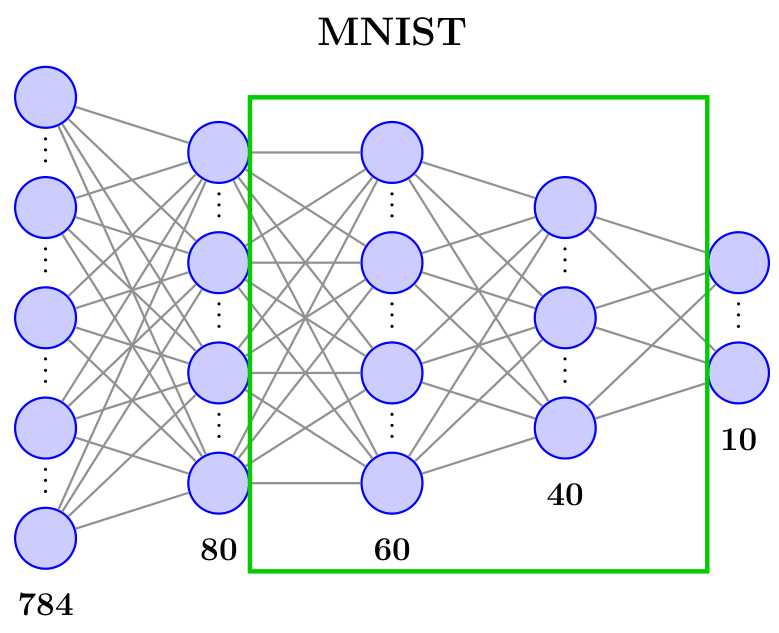
For MNIST, with L7 parameter savings, accuracy drops are consistently maintained below L8 for TS-PROJ-CMPT algorithms, which show significant improvements in stability and lower drop compared to prior methods.
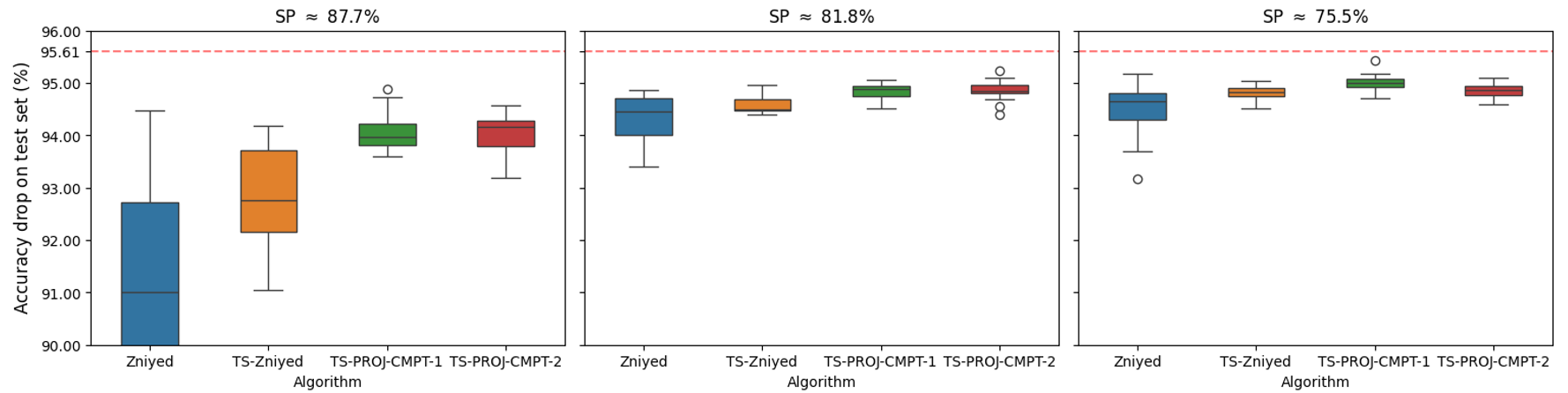
Figure 6: Test accuracies on MNIST under various decoupling/parameter saving configurations. TS-PROJ-CMPT methods attain minimal and consistent drops.
For FashionMNIST, even more aggressive compression (L9 savings) is possible with accuracy drop below L0.
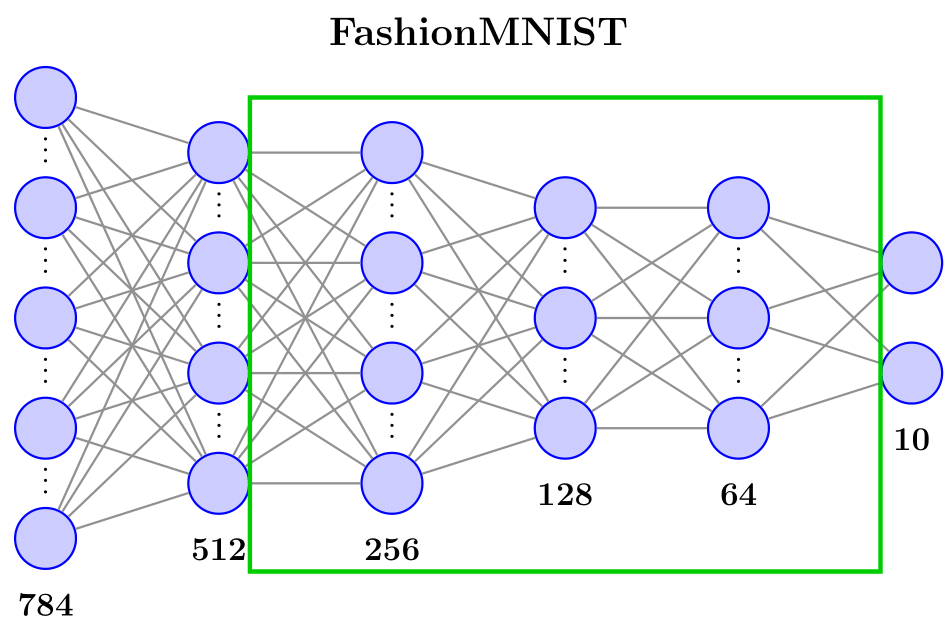
Figure 7: Architecture of FashionMNIST network, with the section to be decoupled/compressed indicated.
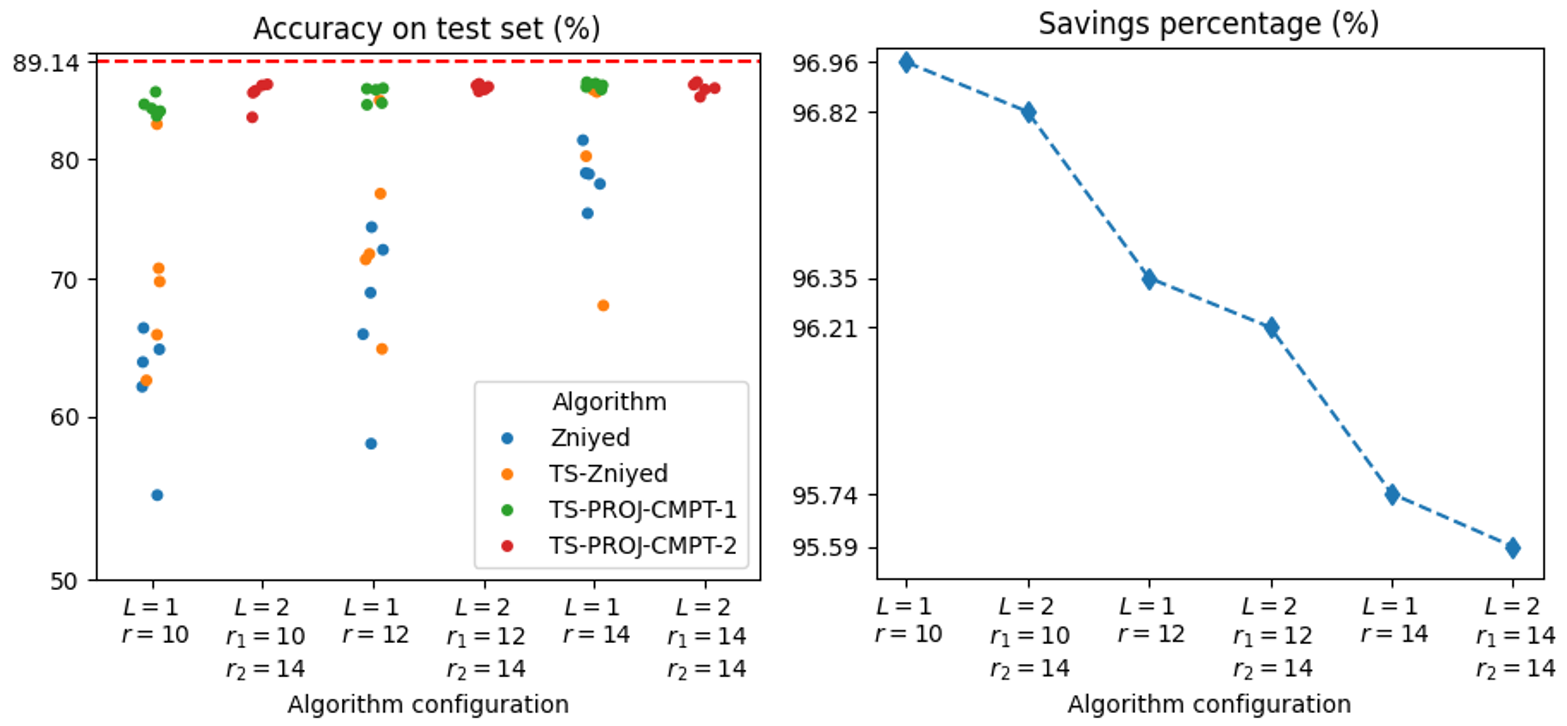
Figure 8: FashionMNIST test accuracy and savings percentage; TS-PROJ-CMPT algorithms exhibit significantly higher stability and smaller accuracy loss versus Zniyed.
Moreover, multi-layer (depth-2) decouplings can outperform single-layer models of similar parameter count, amplifying the practical value of the framework for highly expressive, resource-limited architectures.
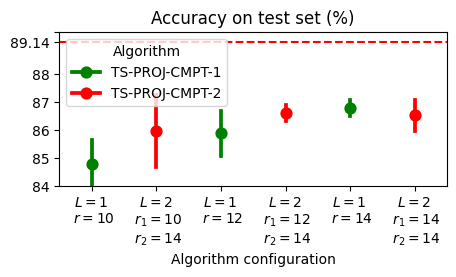
Figure 9: Detailed accuracy versus savings comparison for TS-PROJ-CMPT-1 and TS-PROJ-CMPT-2. Deeper decoupled representations offer an advantageous tradeoff.
Implications and Theoretical Significance
The work generalizes CPD-based decoupling to an arbitrary number of layers via the ParaTuck-L1 formalism, with full theoretical characterization of ambiguity, uniqueness (under polynomial/analyticity and scale-invariant basis), and algebraic structure of Jacobian tensors. The numerical results substantiate strong practical benefit in classical system identification and neural network model order reduction.
Importantly, this framework integrates naturally with modern neural architectures, offering data-driven compression directly on pretrained networks, and can guide the design of parameter-efficient, expressive architectures by allowing flexible, learned activation structures. When the underlying function is highly nonlinear or when tensorized model compression [cf. (Schmidhuber, 2015, Janzamin et al., 2015)] is used, the ParaTuck-based techniques offer a theoretically well-founded alternative to tensor-train and low-rank methods.
This paradigm may also enhance interpretability in system identification, providing access to learned activation structures per layer, and establish the basis for analyzing the expressivity and sample complexity of deep flexible-activation neural networks.
Conclusion
The Tensor-based Multi-layer Decoupling framework unifies and extends algebraic decoupling methodologies to multi-layer settings, grounding the analysis of deep architectures in tensor algebra. By leveraging the structure of ParaTuck-L2 decompositions with appropriately regularized and constrained factorization algorithms, it enables accurate, robust, and scalable recovery and compression of deep nonlinear maps from modest data. Empirical results validate its superiority in stability and error guarantees. As architectures and applications continue to scale, further investigation into optimal basis selection, layerwise bias propagation, and high-order extension will drive the field toward more efficient and interpretable model design.
(2604.10858)