- The paper introduces a unified framework that combines a frozen MLLM for semantic reasoning with a diffusion transformer for precise audio synthesis and editing.
- It leverages a hybrid AudioEdit dataset with over one million paired instances to drive robust multi-domain performance, including general sound, music, and speech tasks.
- It demonstrates that dual-conditioning on high-level semantics and low-level signal features achieves competitive or superior results compared to specialized models.
Audio-Omni: A Unified Framework for General-Purpose Audio Understanding, Generation, and Editing
Introduction
"Audio-Omni: Extending Multi-modal Understanding to Versatile Audio Generation and Editing" (2604.10708) addresses the fragmentation and narrow domain coverage of existing audio models by proposing a scalable, end-to-end framework capable of unifying audio understanding, generation, and editing across diverse domains, including general sound, music, and speech. The work positions itself against prior specialized and semi-unified models that are restricted to domain-specific use cases or rely on loose tool-based integration rather than true architectural unification.
AudioEdit: Large-Scale Dataset Construction
A major impediment for progress in instruction-guided audio editing is the lack of a comprehensive, large-scale, high-fidelity dataset. The authors introduce AudioEdit—a dataset exceeding one million paired editing instances—constructed through a hybrid data pipeline combining real-world and synthetic sources. On the real-data branch, the pipeline leverages an MLLM (Gemini) to annotate sound categories followed by SAM-Audio for source separation, producing natural, annotated edit pairs. The synthetic branch uses the Scaper toolkit for programmatic generation of annotated editing instructions to ensure scale and diversity. The synergy of both branches enables the dataset to span authentic acoustic complexity and diverse editing scenarios.
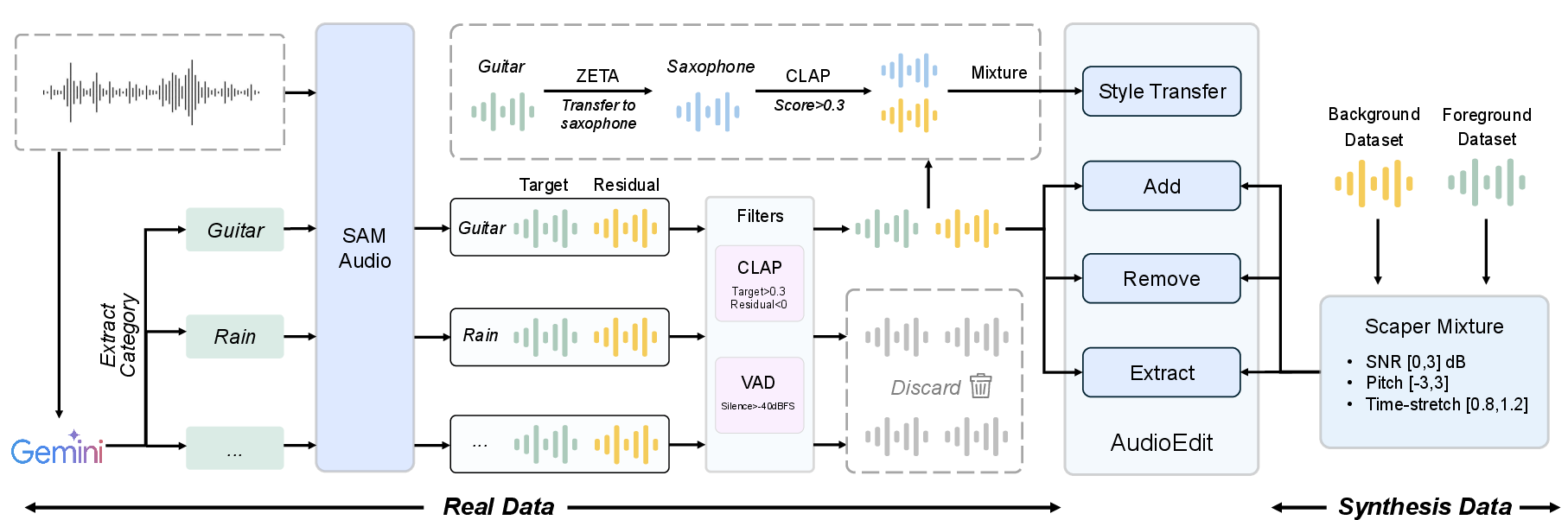
Figure 1: Overview of the hybrid pipeline for constructing AudioEdit, combining real and synthetic generation for acoustic fidelity and large-scale diversity.
Audio-Omni Architecture
The core of Audio-Omni is a decoupled, modular architecture comprising a frozen Multimodal LLM (MLLM) for all high-level semantic reasoning and a trainable Diffusion Transformer (DiT) for conditional audio synthesis and editing. Critical to the unified design is a hybrid conditioning mechanism with two complementary feature streams:
- High-Level Semantic Features: Concatenation of multimodal embeddings from the MLLM and speech transcript features (for TTS/VC tasks), injected via cross-attention. This stream informs the DiT with task instructions, world knowledge, and semantic context.
- Low-Level Signal Features: Concatenation of Mel-spectrogram (from reference audio or prompt) and synchronization features (extracted from video by a Synchformer), injected via concatenation with the input noise and time embedding. This stream provides temporally precise control, especially for editing and synchronization.
This separation of semantic and signal features is critical for mastering the disparate modalities of general sound, music, and speech within a single system.
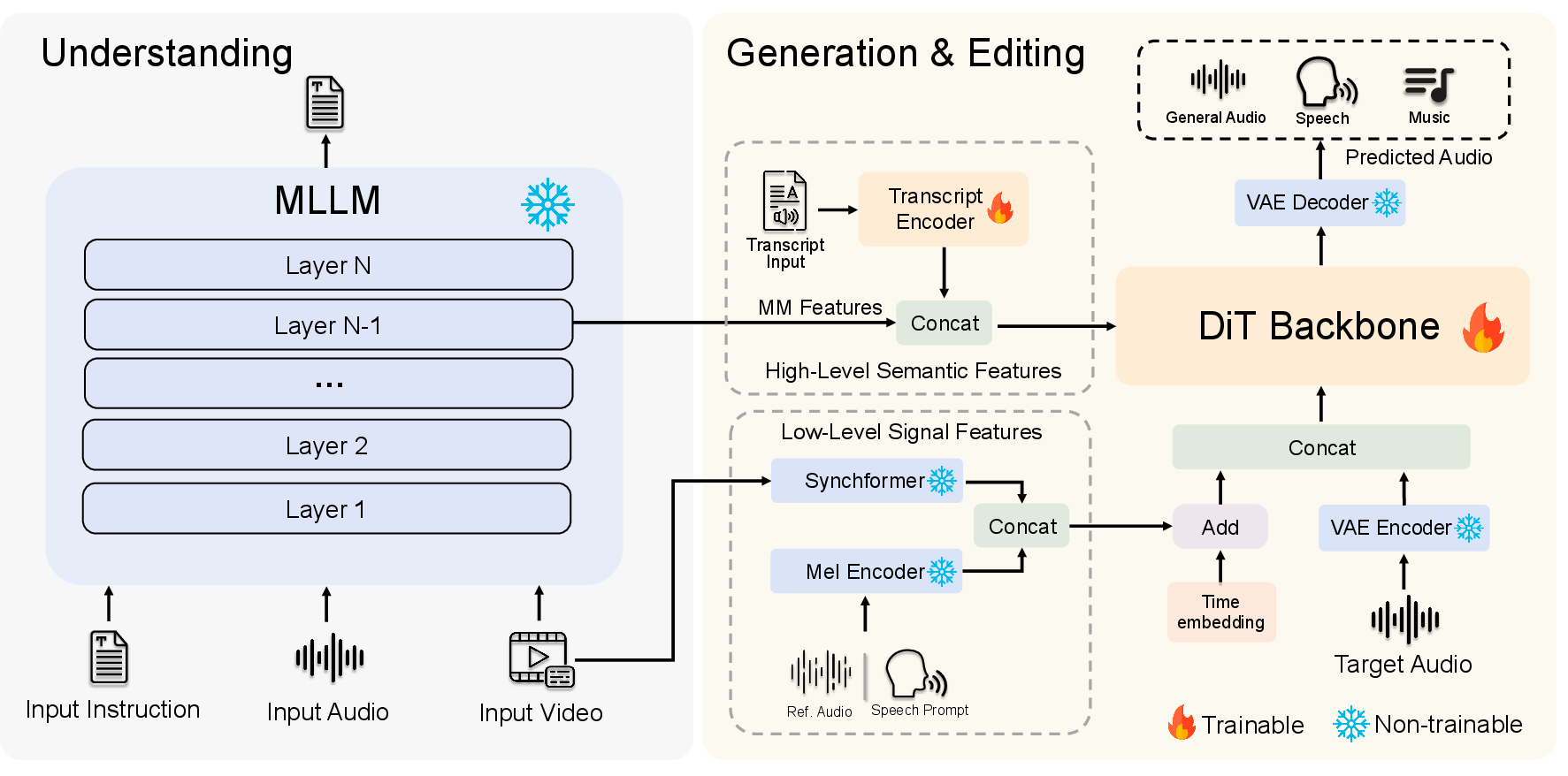
Figure 2: Audio-Omni’s architecture decouples semantic and signal conditioning for robust, flexible audio generation and editing.
Methodology: Diffusion-based Rectified Flow
A notable architectural choice is the adoption of Rectified Flow as the generative backbone. Instead of the typical stochastic diffusion path, Rectified Flow models the generative process as a direct path (constant velocity ODE) from noise to data, with the DiT required to predict the velocity field conditioned on both streams. This reduces stochasticity in audio synthesis, providing determinism and enabling efficient, controllable training tailored for temporally sensitive editing.
Training leverages end-to-end optimization of the DiT and all conditioning modules (except the frozen MLLM), with careful curriculum mixing of synthetic and real-world data to maximize generalization.
Experimental Results and Analysis
Audio-Omni demonstrates competitive or superior empirical performance versus both unified baselines and specialized expert models across all core audio tasks:
- Multimodal Understanding: The framework is evaluated on MMSU and MMAU. It achieves strong understanding scores, approaching or matching specialist audio-LLMs due to the MLLM’s extensive pretraining.
- Audio Generation (T2A, V2A, T2M, V2M, TTS): On a wide range of benchmarks, Audio-Omni consistently outperforms all unified baselines and either matches or surpasses domain experts. For instance, on FAD and WER, it reports best or near-best-in-class results, attributable to the effective disentangling of semantic intent from signal-level conditioning.
- Audio Editing: On the AudioEdit test suite, Audio-Omni exhibits lower FAD and LSD (e.g., 3.27/2.27 avg) than all specialized baselines, particularly excelling at style transfer and source-target consistency thanks to its well-constructed conditioning and dataset.
Notably, Audio-Omni achieves SOTA or near-SOTA performance across all modalities and tasks with a single set of model parameters—contradicting the common assumption that only domain-specialized models can reach top-tier quality.
Inherited and Emergent Capabilities
The unified framework, combined with a frozen, high-capacity MLLM, induces several emergent abilities:
- Knowledge-Augmented Generation: Prompts requiring external world knowledge (e.g., referencing historical musicians or rare instruments) are handled robustly, as the frozen MLLM brings non-explicitly-trained knowledge to bear during generation.
- In-Context Control: Conditioning on input exemplars enables the model to perform transfer and contextualization without explicit instruction, e.g., generating music in the style of a provided piano recording when given compositional prompts.
- Zero-Shot Capabilities: The masking-based training curriculum further equips Audio-Omni with robust zero-shot voice conversion, cross-lingual understanding/generation (tested on Chinese, Spanish, German, French, Japanese), and unsupervised editing, even without specific fine-tuning.
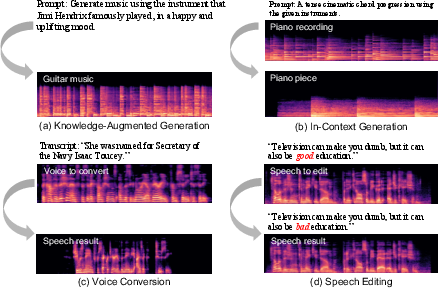
Figure 3: Qualitative showcase: knowledge-augmented generation, in-context generation, zero-shot voice conversion, and zero-shot speech editing.
Ablation and Architectural Study
Comprehensive ablations indicate:
- Mixed synthetic and real-world training data are required to achieve optimal results, as neither alone suffices for generalization and fidelity.
- The optimal conditioning strategy injects high-level semantic guidance via cross-attention and low-level signal features via concatenation, maximizing both flexibility and temporal alignment.
- Features extracted from the penultimate layer of the frozen MLLM provide richer, less task-specific representations than the final layer, which is overfit to text autoregression.
- Direct, dense feature integration (rather than query-based or bottlenecked mechanisms) is critical for high-fidelity synthesis; indirect, attention-based injection degrades generation quality.
Theoretical and Practical Implications
Audio-Omni validates that a single, end-to-end trainable architecture, with careful conditioning and data engineering, suffices to close the performance gap between unified and expert models in the audio domain. This finding has major ramifications for scalable, multi-task audio intelligence—suggesting that further scaling of the MLLM and DiT backbones, with even broader multimodal and multilingual pretraining, could enable fully universal generative agents capable of seamless audio, video, and text interaction.
On the practical side, the introduction of AudioEdit, combined with inheritance of real-world knowledge, enables new applications in zero-shot editing, creative synthesis, and robust cross-modal communication. However, the authors also note ethical risks in speech and speaker impersonation, advocating for careful deployment and watermarking.
Conclusion
Audio-Omni (2604.10708) advances the field by presenting a cohesive, empirically robust, and extensible architecture for general-purpose audio understanding, generation, and editing. By combining a frozen, high-capacity MLLM with a diffusion transformer under dual conditioning streams, and validating with a hybrid dataset, the framework achieves SOTA or competitive results on a battery of tasks and introduces substantial zero-shot and emergent abilities. Future work extending the model towards even broader multi-modal coverage and exploring structural modifications for real-time or interactive applications will push the boundary of universal generative audio intelligence.