- The paper introduces a challenge that leverages generative diffusion models for restoring short-form UGC videos affected by complex real-world degradations.
- It presents the KwaiVIR benchmark combining synthetic and wild video data to evaluate methods on both objective fidelity and subjective perceptual quality.
- Results reveal that one-step and dual-stream diffusion approaches can achieve robust restoration with high spatial detail, temporal consistency, and perceptual realism.
Introduction and Challenge Motivation
The NTIRE 2026 Challenge targets the restoration of short-form user-generated content (S-UGC) videos in-the-wild, emphasizing generative-model-driven approaches under complex, real-world degradations. Unlike traditional video restoration, S-UGC video restoration must contend with mixed artifacts originating from consumer-grade capture devices, aggressive compression/transcoding pipelines, and diverse content dynamics characteristic of platforms like Kwai and TikTok. Restoration objectives require not only distortion removal but perceptual realism and temporal coherence, with methods expected to generalize robustly across unseen and varied content distributions.
The challenge introduced the KwaiVIR benchmark, featuring both paired synthetic degraded videos and authentic wild S-UGC videos, facilitating comprehensive evaluation via both objective (PSNR, SSIM, LPIPS, MUSIQ, WarpError) and subjective (user study—fidelity, perceptual quality, temporal consistency) metrics. This dual-track protocol addresses the ongoing debate between fidelity-oriented and perceptually-preferred restoration strategies.
Benchmark Description
KwaiVIR's dataset includes 200 synthetic training videos and 48 wild training videos, with separate validation and test sets blending synthetic and wild scenarios. By combining paired data and in-the-wild samples, the challenge imposes requirements for methods to excel in both reference-based restoration and blind perceptual improvement tasks—mirroring actual deployment conditions and maximizing practical relevance.
Methodological Overview
Submissions reveal a strong clustering in paradigms: large diffusion-based transformers, domain-adaptive pipelines, fusion frameworks, and efficient distillation/distillation-driven designs. Notably, rapid advances in generative diffusion models directly translate to the video restoration field, with leading teams leveraging pretrained text-to-video, video-to-video, and latent generative backbones.
Team RedMediaTech dominates both tracks via a two-stage training protocol implementing Wan2.1's video diffusion transformer (DiT). Stage 1 leverages the Wan2.1 VAE and DiT, optimizing for both MSE and LPIPS to rapidly capture strong generative priors and perceptual realism. Stage 2 swaps in a Qwen-Image VAE for increased spatial detail retention, with shortcut connections to preserve cross-stage information. Three-dimensional rotary positional encoding (RoPE) is crucial for temporal modeling, and aggressive data augmentation (frame skipping, cropping) enhances robustness.
Frames are encoded to latent space, processed by DiT in a single diffusion step, and decoded, achieving efficient inference and high perceptual quality.
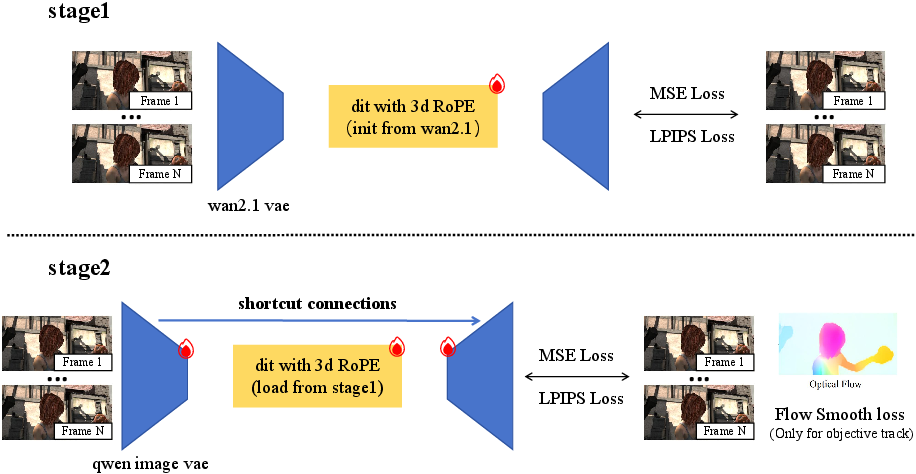
Figure 1: RedMediaTech’s framework—single-step diffusion transformer with temporal RoPE and VAE shortcut connections.
MiAlgo_LM: Dual-stream Mini-Control Injection
MiAlgo_LM presents Mi-GenVR, founded on Wan2.1-14B DiT, using a dual-stream conditional injection scheme. Their method introduces Self-Attention-Control and Cross-Attention-Control modules to explicitly inject degraded priors and semantic conditions into generative streams. High-rank LoRA modules tune task-specific adaptation with most backbone weights frozen for memory efficiency. Inference uses overlapping sliding windows and prediction averaging for seamless temporal restoration.
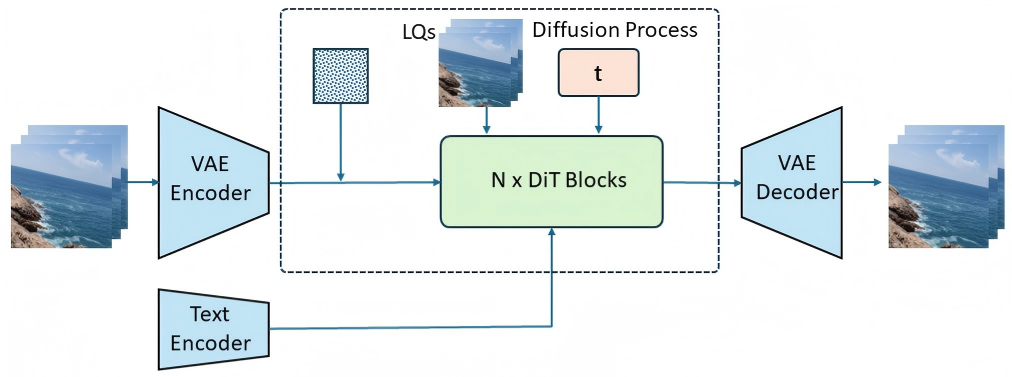
Figure 2: Mi-GenVR’s dual-stream conditional injection restoration framework built on Wan2.1-14B DiT.
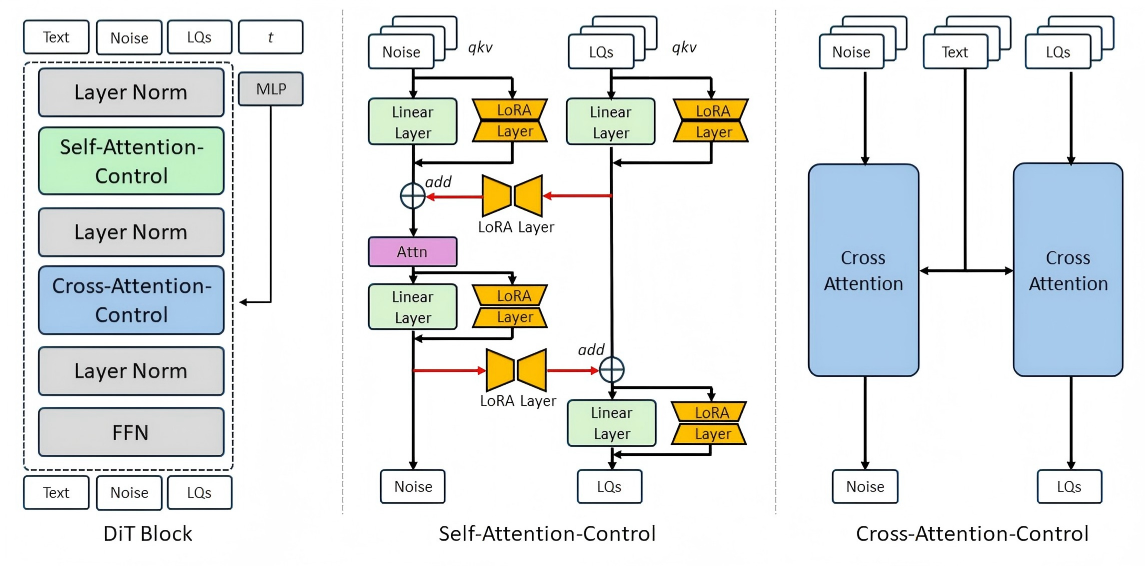
Figure 3: Detailed DiT design underlying Mi-GenVR, emphasizing cross-stream attention and LoRA tuning.
TaoMC2 employs a dual-branch text-to-video diffusion module, supplementing general restoration with a pre-cleaning branch for severe discontinuities. A RRDB-based fusion network leverages the origin degraded input for a balance between detail preservation and artifact removal. Training uses 500K high-quality web videos, with quality assessed by no-reference models and text annotation generated via Qwen2.5-VL. Distributed training on 64 GPUs facilitates comprehensive coverage of diverse degradation statistics.
STCVSR: Anchor-based Structural Guidance with Consistent VAE Segmentation
STCVSR combines ODTSR for sparse anchor frame enhancement with STCDiT to restore full videos, focusing on structural guidance and segment boundary adaptation for locally severe degradations. No additional retraining is performed; pretrained weights drive inference, and robust segment boundary adjustment reduces failure rates in strongly degraded regions.
BuptMM simultaneously processes video frames via SeedVR2 7B (fine-tuned with LoRA) and FlashVSR, fusing results with a constant global weight (α=0.7) to optimize both pixel fidelity and perceptual quality. The fusion strategy avoids spatial/block-wise artifacts and temporal jitter, balancing high-frequency preservation with robust restoration.
FlashVSR-UGC-Causal and Lucky one: Efficient One-step Diffusion Models
Both approaches opt for single-step diffusion restoration, compressing traditional multi-step generative processes via distillation or latent-pixel supervision. FlashVSR-UGC-Causal adapts vertical stream processing for portrait-format content and employs causal temporal streaming built solely on current and historical frames, improving resistance to nonlinear motion and shot changes while enabling real-time deployment.
Results and Analysis
RedMediaTech achieves highest scores in both tracks: subjective (3.8525) and objective (61.7395, PSNR 30.76, SSIM 0.85, LPIPS 0.191), demonstrating robust convergence between distortion removal and perceptual enhancement. Video-Restorer places second in objective evaluation, notably with lowest WarpError ($0.0549$), reflecting superior temporal consistency. Discrepancies between subjective and objective rankings highlight the challenge's design, where results submitted per track may be independently optimized for perception or reference fidelity.
Team BVI: Time-Aware One-step Latent Diffusion
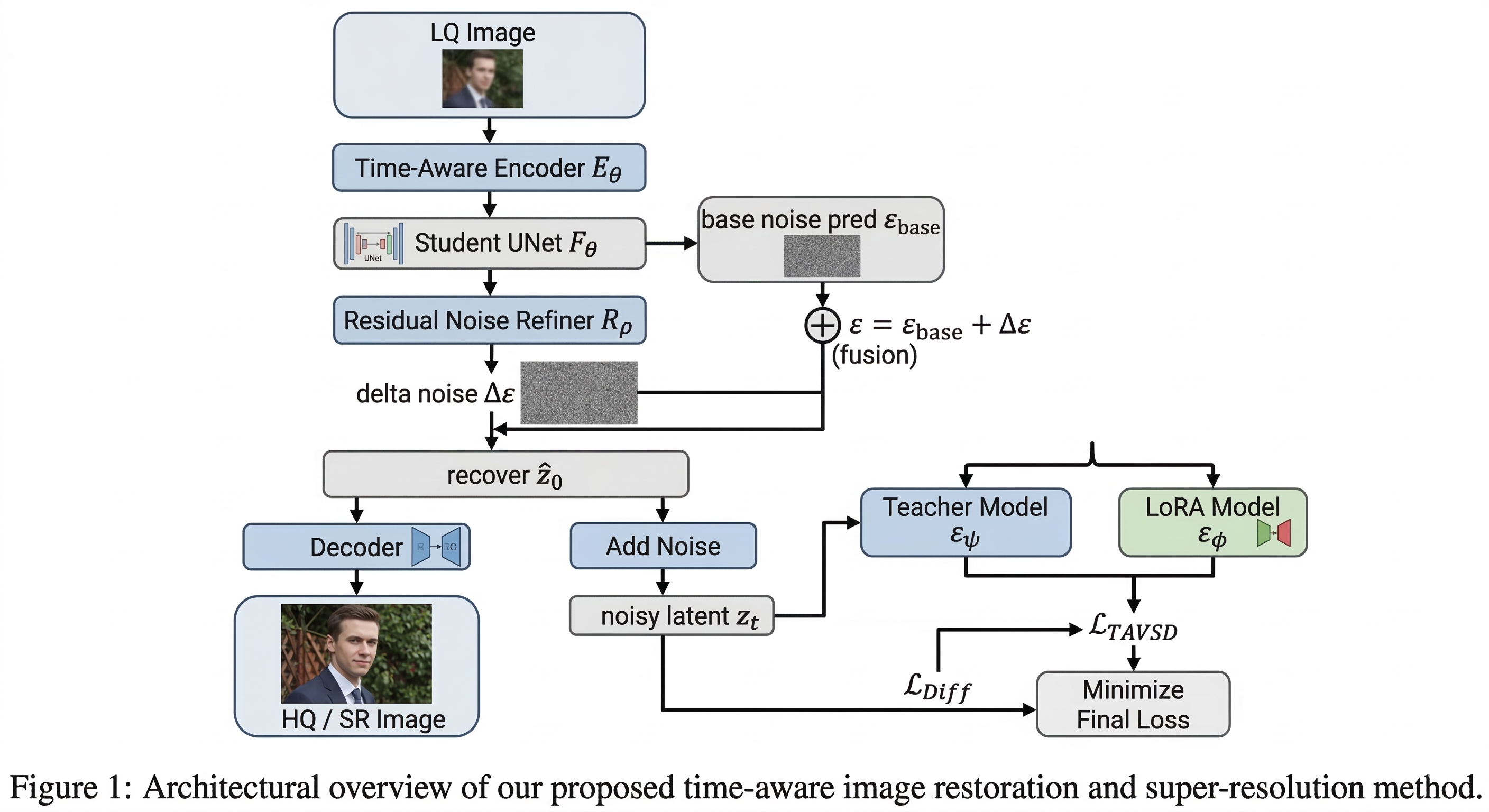
Figure 4: BVI’s time-aware latent diffusion restoration pipeline incorporating residual noise refinement and detail-aware loss scheduling.
BVI adapts TADSR for one-step frame-wise restoration, supplementing standard supervision with novel detail-aware losses emphasizing high-frequency and gradient information. Ratio-capped residual regularization stabilizes correction magnitudes—a proven mechanism for balancing global and local restoration objectives.
Practical and Theoretical Implications
The challenge demonstrates the operational viability of large diffusion models (over 14B parameters) for real-time restoration when guided by efficient one-step distillation and adaptive encoder/decoder configuration. Data diversity and targeted augmentation are critical in achieving domain adaptation, and fusion architectures leveraging both generative and discriminative models claim strong empirical gains.
The theoretical implication is clear: future research must balance perceptual quality, distortion fidelity, temporal consistency, and inference efficiency. Given S-UGC’s volatility, robust domain adaptation, personalized restoration streams, and dynamic fusion mechanisms will increasingly define competitive solutions. Model compression, prompt learning, and scalable distillation are immediate priorities for real-world deployment.
Conclusion
The NTIRE 2026 Challenge formalizes UGC video restoration as a multi-faceted task—requiring advances in generative modeling, adaptation, and evaluation. Single-step diffusion architectures, dual-stream and anchor-guided fusion, and novel loss functions dominate current solutions, highlighting the maturity of generative restoration. Comprehensive benchmarks like KwaiVIR and dual-track protocols accelerate convergence to practical, deployable restoration systems, with future progress likely hinging on efficient scaling, multi-modal conditioning, and seamless integration into content platforms (2604.10551).