- The paper demonstrates that LLMs enhance SOC efficiency—especially in triage and alert investigation—while posing verification and security risks.
- Mixed-methods analysis of 892 Reddit posts shows predominant use of general-purpose LLMs despite growing interest in specialized solutions.
- The study underscores the need for AI-literate upskilling and governance reforms to mitigate risks and ensure sustainable cybersecurity operations.
LLMs in Cybersecurity Operations: Empirical Insights from Practitioners on Reddit
Introduction
The proliferation of LLMs has catalyzed a new wave of interest in augmenting Security Operations Center (SOC) workflows with generative AI. Despite significant industry and academic attention, rigorous empirical understanding of how security practitioners employ, perceive, and adopt LLMs remains limited. "Like a Hammer, It Can Build, It Can Break: LLM Uses, Perceptions, and Adoption in Cybersecurity Operations on Reddit" (2604.09998) addresses this gap via a mixed-methods analysis of 892 Reddit posts in cybersecurity-focused communities. The paper systematically dissects LLM tool adoption, use cases, practitioner sentiment, and underlying organizational dynamics, providing an authoritative perspective on emergent sociotechnical shifts in real-world security operations.
Methodology and Corpus Overview
The authors employ a mixed-methods analytical framework, combining qualitative coding with quantitative statistical measures, to analyze practitioner discourse from December 2022 to September 2025 across several active cybersecurity-focused subreddits. Posts were filtered and annotated for relevance to actual SOC work and LLM tool use. This dataset supports robust, fine-grained thematic and content analysis, yielding statistically validated insights on tool prevalence, workflow integration, benefit–risk trade-offs, and adoption trajectories. Rigorous IRR validation and ethics controls underpin the study’s methodological credibility.
Dominance of General-Purpose LLMs
Practitioner discussion disproportionately centers on general-purpose LLMs (e.g., ChatGPT, Microsoft Copilot), which are referenced significantly more than domain-specific security LLMs (e.g., Microsoft Security Copilot, Dropzone AI, Intezer). This pattern demonstrates that, as of the study period, the majority of active usage is driven by broadly accessible, non-specialized models, despite concurrent market emergence of specialized security platforms.
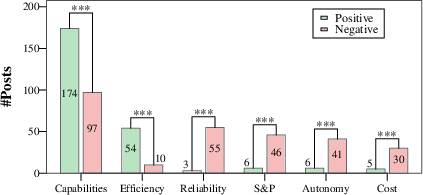
Figure 1: Practitioners voice more positive sentiment for LLM capabilities and efficiency, but express predominantly negative views on other factors such as autonomy, security, and reliability.
Fragmented Security-Specific Ecosystem
The security-focused LLM tool landscape is characterized by a ‘long tail’ of rapidly proliferating offerings. Although practitioners mention over 30 commercial security LLM platforms, discussion remains concentrated around a handful of products, suggesting limited awareness or trial beyond marquee solutions. Notably, only a small fraction of posts describe in-house, custom LLM workflows, indicating significant barriers to internal development and a prevailing reliance on commercial toolchains.
Analytical Use Cases
LLM adoption in SOC work is highly use case-dependent. Triaging, alert investigation, and incident response constitute the dominant applications, followed by scripting, detection logic generation, reporting, and documentation. Knowledge support, threat analysis, and cyber training are less prevalent. A statistically validated analysis confirms the primacy of triage/IR as the leading context for LLM deployment in practice.
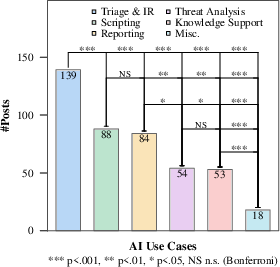
Figure 3: Relative prevalence of discussed LLM application areas shows triage/IR as markedly dominant, with scripting, reporting, and knowledge support less frequent.
Patterns of LLM Integration and Human-AI Collaboration
Practitioners report a strong preference for using LLMs as decision support agents or investigative "buddies." Most actual deployments retain strict analyst-in-the-loop architectures, limiting LLM autonomy to ensure verification and maintain operational safety. Reports of end-to-end autonomous LLM systems are rare and typically restricted to low-impact, high-volume routine alerts or ‘Tier 1’ support. Custom integrations and SOAR augmentations leverage LLMs for narrow, productivity-oriented tasks rather than mission-critical response actions.
Practitioner Perceptions: Benefits and Risks
Capabilities and Efficiency
LLM tools are widely recognized as beneficial for contextualizing alerts, improving visibility, automating documentation, and enabling more efficient query/script generation. Quantitative analyses reveal that practitioners are significantly more likely to express positive sentiment on these dimensions. Reductions in incident triage times (from median 45 minutes to under 2 minutes in some cases) are cited as concrete efficiency gains.
Reliability, Security, and Autonomy
However, reports of reliability issues—including hallucinations, inconsistent output, lack of determinism, and susceptibility to fabricated justifications—dominate negative sentiment. Critically, these shortcomings impose manual verification overhead, offsetting perceived efficiency and forming the principal barrier to granting LLMs true operational autonomy. Concerns around security and privacy are acute: practitioners worry about inadvertent organizational data leakage through LLM prompts and about attack surface expansion via prompt injection or jailbreak risks.
Cost Sensitivity
Negative perceptions around the economics of LLM solutions are frequent, particularly regarding inference costs at SOC scale and the high recurring expense of commercial tools. Practitioners question whether the price performance ratio of premium security LLM products justifies their enterprise integration versus hiring additional analysts.
Trajectories and Sociotechnical Dynamics of Adoption
Adoption is bifurcated: individual analysts exercise low-commitment, independent use of general-purpose LLMs for personal productivity, while enterprise-grade, security-focused tool uptake is typically driven by organizational decision-makers and is subject to higher friction. The factors constraining higher-level, organization-wide adoption include reliability, security, integration requirements, inflated vendor promises, and lack of compelling value over existing deterministic workflow automation.
Adverse sentiment is magnified within discussions of autonomy and "AI replacement" narratives. While practitioners acknowledge that LLMs threaten to reduce or replace entry-level (L1) SOC roles, consensus holds that high-skill and governance tasks (IR, threat hunting, compliance, contextual reasoning, accountability) remain robustly human-centric.
Implications for SOC Workforce and Future of Expertise
A pivotal insight is the emergence of a sociotechnical tension: LLM-driven automation of entry-level work risks eroding the experiential learning pipelines necessary for building expert analysts capable of overseeing and governing AI-augmented operations. This circularity—where only expert analysts can supervise LLMs effectively, yet these experts classically develop through now-automated tasks—has long-term consequences for workforce sustainability. Recommendations emphasize the imperative for AI-literate upskilling, role redefinition, and investigation into co-learning paradigms (AI-as-mentor) to facilitate effective knowledge transfer in LLM-mediated environments.
Theoretical and Practical Implications
The study advances the state of empirical research in AI-augmented SOCs by surfacing critical nuances around tool adoption, reliability ceilings on autonomy, and shifting expertise boundaries. It questions industry narratives promising full SOC automation, instead supporting a model where LLMs function primarily as operator-controlled decision support. The results reinforce the need for research into uncertainty communication, verification-aware system design, and novel governance patterns for LLM-integrated security operations. From a practical standpoint, the reported verification overhead and risk trade-offs should inform both product engineering (focusing on explainability/confidence estimation) and organizational policy (managing AI deployment expectations and data governance).
Conclusion
This mixed-methods analysis provides authoritative, empirically grounded insights on the multidimensional adoption and impact of LLMs in SOC environments. Practitioners are leveraging general-purpose LLMs for non-critical tasks, observe significant productivity gains, but remain constrained by reliability, risk, and cost concerns—precluding broad LLM autonomy in high-stakes security operations. Theoretical advances are needed in both AI governance and co-learning system design to resolve the emerging workforce expertise gap. Future work should focus on measuring real-world verification overhead, designing uncertainty-aware LLM systems, and developing sustainable human–AI co-learning models for critical security infrastructure.

