- The paper introduces a diffusion-based hierarchical pruning pipeline that leverages parallel mask prediction to significantly reduce prompt length and inference time.
- The method generalizes across tasks and architectures, maintaining or improving accuracy with up to 80% prompt length reduction compared to sequential approaches.
- The approach utilizes discrete diffusion language models for efficient token retention mask denoising, achieving architecture-independent performance and robust domain transfer.
DiffuMask: Diffusion LLM for Token-level Prompt Pruning
Background and Motivation
Prompt compression is increasingly critical as LLMs leverage In-Context Learning (ICL) and Chain-of-Thought (CoT) prompting for complex reasoning tasks. While richer prompts drive substantive performance gains, increased prompt length directly raises inference latency and memory requirements. Existing prompt pruning methods, especially token-level pruning via reinforcement learning or evolutionary algorithms, are computationally expensive and sequential, prohibiting practical scalability.
DiffuMask ("Diffusion LLM for Token-level Prompt Pruning") introduces a hierarchical, diffusion-based approach to prompt pruning. The key innovation is parallel mask prediction, leveraging discrete DLMs to denoise token retention masks, rapidly compressing lengthy prompts without sacrificing performance. DiffuMask offers tunable control over compression and generalizes across domains and architectures.
Hierarchical Prompt Pruning Pipeline
DiffuMask's training requires high-quality supervision mimicking realistic hierarchical pruning. The pipeline proceeds as follows: (1) shot-level pruning eliminates unnecessary in-context examples via RL-based or random selection strategies; (2) token-level pruning (TA-Pruning) removes redundancies within exemplars, guided by task accuracy thresholds; (3) evaluation and filtering discard suboptimal candidates, retaining those improving accuracy; (4) full–pruned prompt pairs are aligned for binary mask supervision.
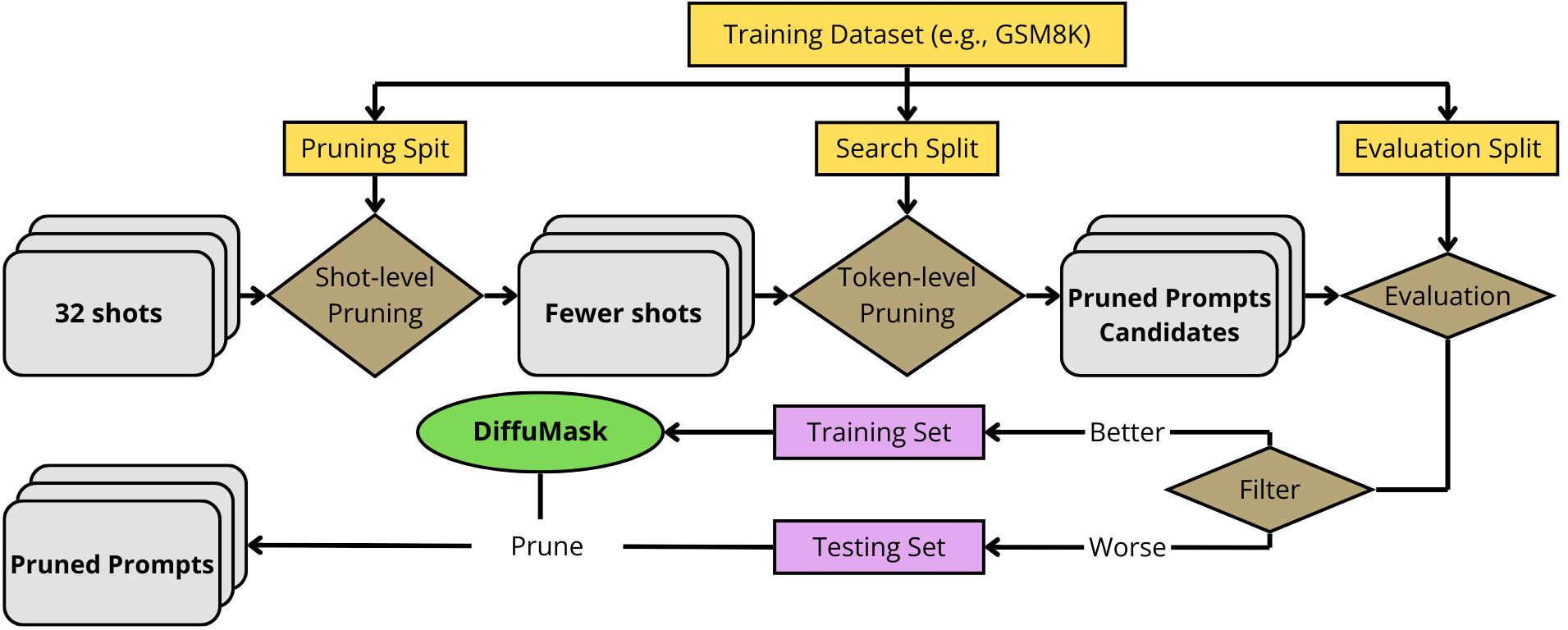
Figure 1: Data generation pipeline for DiffuMask, illustrating hierarchical shot-level and token-level pruning yielding full–pruned prompt pairs, exemplified on GSM8K.
This multi-stage pipeline ensures robust mask supervision, capturing both coarse- and fine-grained redundancy patterns. Despite TA-Pruning's empirical effectiveness, its runtime (10–48 hours per prompt) underscores the necessity of efficient alternatives.
DiffuMask Framework
DiffuMask leverages discrete DLMs (LLaDA-8B architecture) to approximate the hierarchical pruning policy via mask prediction. The model receives a full prompt and iteratively denoises a token retention mask, operating inversely to standard masked DLMs (which predict tokens instead of masks). The forward process reveals incrementally more tokens; DiffuMask, trained with binary cross-entropy and an anti-mask penalty, learns to reconstruct the original pruned mask via parallel prediction. At inference, a tunable top-k and threshold mechanism modulates pruning aggressiveness, directly balancing compression and reasoning fidelity.
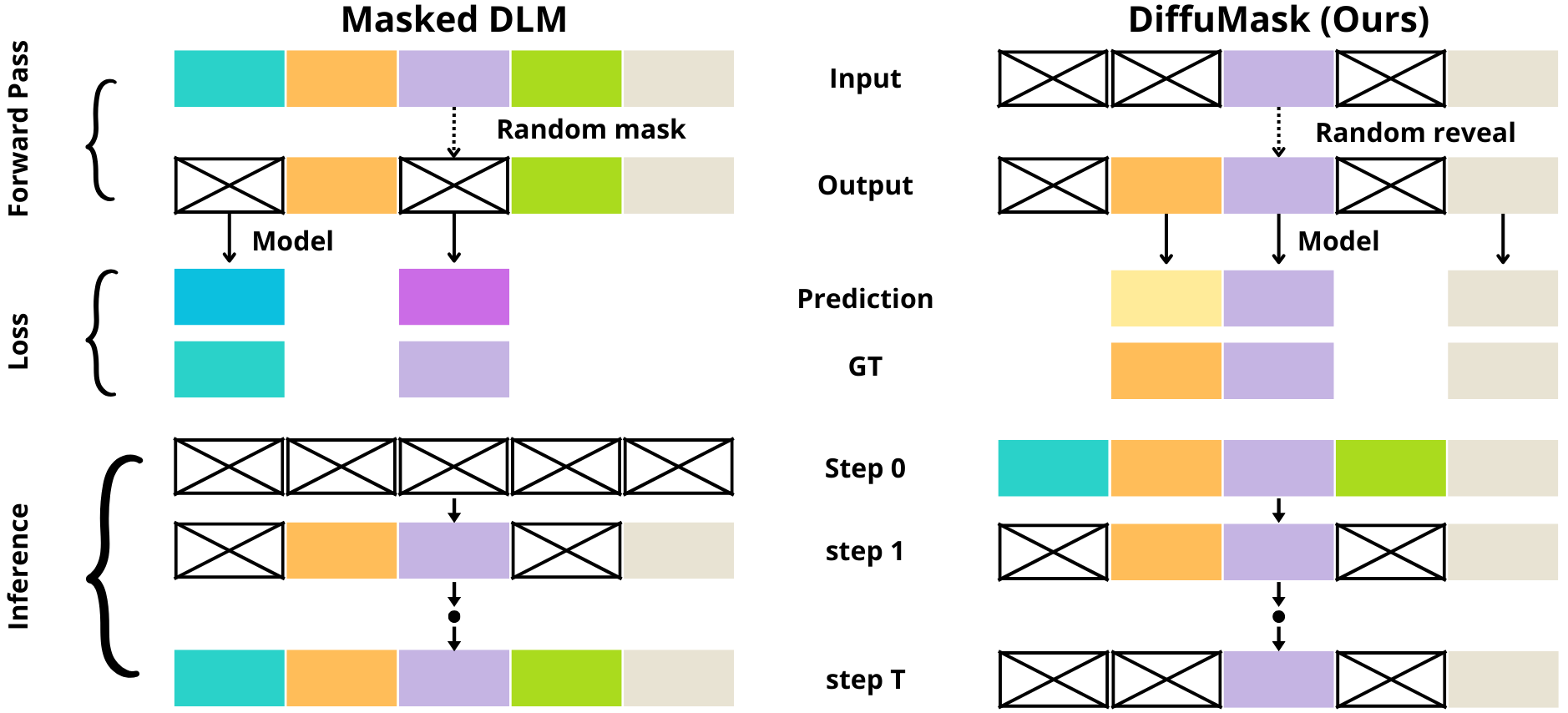
Figure 2: Overview of DiffuMask’s iterative mask denoising in contrast to masked DLM token reconstruction, emphasizing the parallel efficiency of mask-based prompt pruning.
Alignment between tokenizer spaces is strictly enforced to enable direct, positionwise mask supervision. The diffusion-based process discards redundant tokens in parallel, dramatically accelerating pruning compared to sequential methods.
Empirical Evaluation
In-Domain Results
DiffuMask achieves 80% prompt length reduction on GSM8K mathematical reasoning tasks, maintaining or exceeding original accuracy (77.07% EM vs. 76.49% for full prompts). Pruning inference time drops from 10–48 hours (TA-Pruning) to ~1 minute. DiffuMask exceeds LLMLingua/LLMLingua2 baselines by over 6% accuracy with near-identical token compression.
Out-of-Domain Generalization
DiffuMask trained solely on GSM8K generalizes robustly to classification tasks (Yelp5, Yahoo, AG's News):
- On AG’s News, twenty-shot accuracy rises from 25.37% (full) to 84.40% (DiffuMask), retaining only 53% of tokens.
- For Yahoo five-shot, accuracy increases by 12.03% alongside a 69% token reduction.
These results indicate task-agnostic redundancy detection and transfer, not merely memorization of domain-specific heuristics.
Cross-Model Robustness
DiffuMask-pruned prompts, generated for LLaMA, also enhance accuracy for GPT-4o (+1.8%), Llama-3.3-70B (+3.4%), Gemini-2.5-Pro (+0.2%), among others, with accuracy losses on only a subset of architectures and overall substantial efficiency gains. This suggests architecture-independent saliency modeling.
Token-Level Characteristics
POS analysis shows pruned tokens are not restricted to specific grammatical classes; the distribution of removed tags broadly mirrors original prompts, confirming non-trivial, semantic pruning.
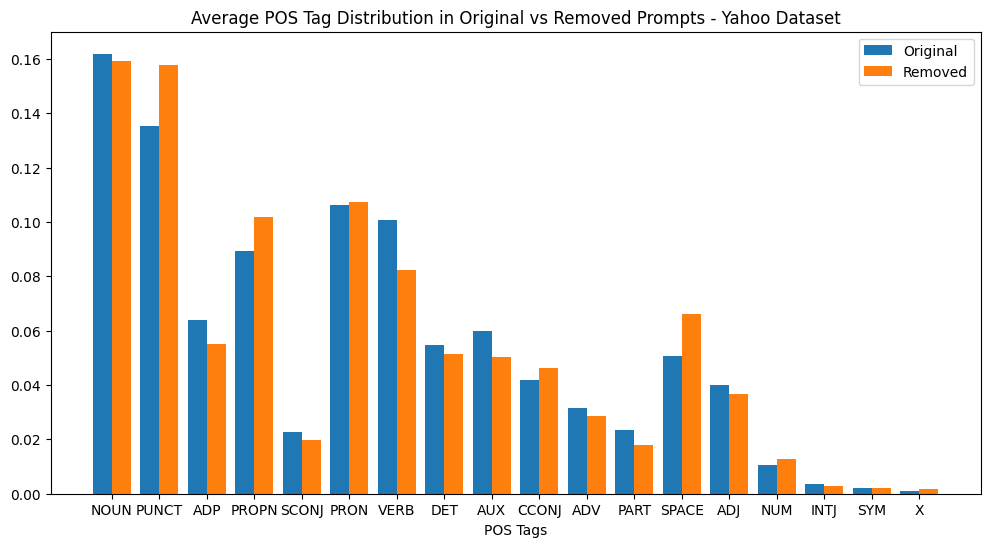
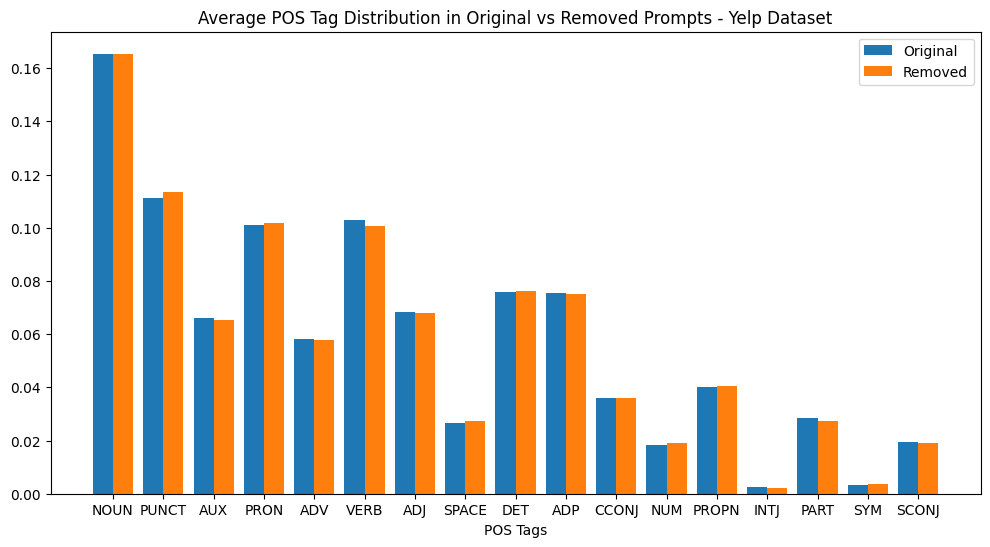
Figure 3: POS tag distribution in original vs. pruned prompt tokens across GSM8K, Yelp, and Yahoo—pruned content closely tracks the source distribution, indicating agnostic removal patterns.
Practical and Theoretical Implications
DiffuMask provides a scalable mechanism for prompt optimization, offering parallelizable token-level compression and task/model-agnostic deployment. The approach aligns with recent trends favoring discrete DLMs for efficiency and robustness (2604.06627, Nie et al., 14 Feb 2025). By transferring effectively to OOD settings and diverse LLM architectures, DiffuMask mitigates the inductive bias risk and addresses bottlenecks in practical LLM inference workflows.
Limitations include the high computational overhead in ground-truth data generation for model training, inference still requiring 64 iterative steps (though orders-of-magnitude faster than sequential pruning), and dependency on teacher pruning methods for supervisory signal quality. Extension to dialog, summarization, and multimodal scenarios remains unexplored.
Conclusion
DiffuMask integrates diffusion modeling for token-level mask prediction, achieving efficient, parallel prompt pruning and substantial compression without sacrificing accuracy. The model generalizes across domains and architectures, providing a practical path toward scalable prompt optimization. The results position DiffuMask as a general-purpose tool for balancing LLM reasoning quality with inference efficiency, supporting robust multi-task deployment for contemporary LLMs.