- The paper introduces a unified diffusion-based framework that jointly controls camera trajectories and object dynamics for coherent video generation.
- It leverages explicit 3D spatial priors with novel Camera Trajectory Control (CTC) and Object Dynamics Control (ODC) modules to enhance spatial consistency.
- The method achieves superior performance on metrics like FID, FVD, and Box-IoU, validated through quantitative experiments and user studies.
SymphoMotion: Joint Control of Camera Motion and Object Dynamics for Coherent Video Generation
Introduction
SymphoMotion presents a unified diffusion-based framework for controllable video generation, enabling synchronized control over both camera trajectories and object-level dynamics within a single architecture. Previous approaches largely treat camera and object motions independently, causing a lack of coherence and reduced realism in compound motion scenarios. SymphoMotion overcomes these limitations via dedicated mechanisms for Camera Trajectory Control (CTC) and Object Dynamics Control (ODC), grounded in explicit 3D spatial priors. To facilitate large-scale training and evaluation, the authors introduce RealCOD-25K, a new dataset providing paired camera poses and 3D object trajectories in diverse real-world scenes.
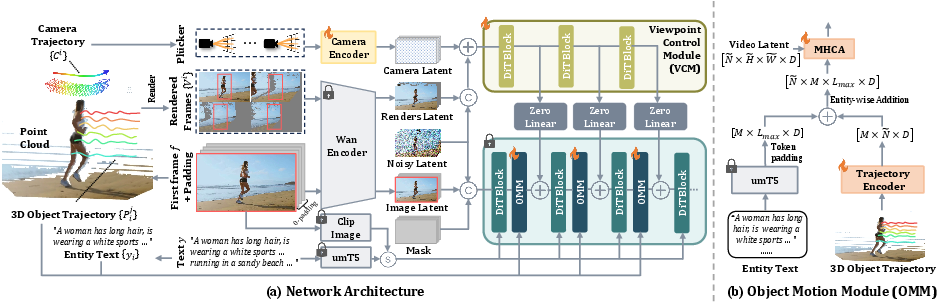
Figure 1: Overview of SymphoMotion, which takes a reference image, text prompt, and user-defined camera/object trajectories to generate spatially consistent videos reflecting both motion modalities.
Video diffusion models with explicit camera control—such as CameraCtrl, CamCo, and Uni3C—parameterize viewpoint via pose embeddings or geometric priors but do not address object motion. Conversely, object-controllable frameworks (e.g., Motion-i2V, MagicMotion, 3DTrajMaster) leverage 2D visual cues or 3D trajectories to manipulate object dynamics, failing to model the complex interactions between camera movement and object motion, especially under strong parallax. Attempts at joint control (e.g., MotionPrompting, ATI, MotionCtrl) often project both motion types into a shared 2D space, leading to ambiguity between camera-induced and object-induced motion, or restrict object modeling to 2D planes.
SymphoMotion is positioned as a fully unified 3D-aware solution. Compared to methods using synthetic-only datasets or needing dense 6D inputs (such as FMC), SymphoMotion leverages real-world 3D annotations and supports intuitive, user-driven control interfaces.
SymphoMotion Architecture
SymphoMotion builds on a diffusion transformer backbone (Wan-I2V), injecting both textual and visual embeddings at each stage for image-to-video synthesis. It introduces two orthogonal yet interconnected mechanisms:
Camera Trajectory Control (CTC)
CTC integrates explicit camera pose trajectories (using Plücker ray encoding) and point-cloud-based 3D geometry extracted from the reference image (leveraging Depth-Pro). Rendered point-cloud frames from varying camera viewpoints are used to encode geometric structure, providing the model with strong spatial priors that enable precise and consistent viewpoint transitions.
Camera embeddings from the pose sequence and geometry-aware features from the point clouds are fused and injected via a Viewpoint Control Module (VCM), implemented as a ControlNet within the diffusion model.
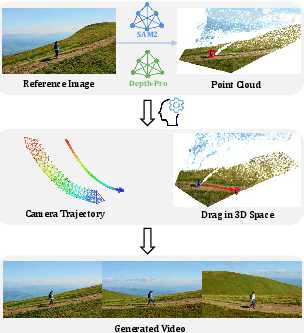
Figure 2: Inference pipeline of SymphoMotion, allowing users to specify camera motion paths and interactively edit object trajectories in 3D before video generation.
Object Dynamics Control (ODC)
ODC manipulates dynamic objects through both 2D and 3D cues. 3D object trajectories for each entity (sampled as point sets across frames) are projected into the image plane for 2D anchoring (motion bounding boxes), while the full 3D paths are embedded via a dedicated encoder. Both visual and trajectory embeddings are cross-attended in each transformer block, ensuring the network aligns object behavior with the specified spatiotemporal paths.
Object identities (from the text prompt) are fused with 3D trajectory features, enabling entity-conditioned dynamic control. The system supports intuitive interactive editing: users can select objects (using SAM2 masks), fit and drag 3D bounding boxes, and directly draw or manipulate motion paths before generation.
RealCOD-25K Dataset Construction
The RealCOD-25K dataset constitutes a significant practical contribution by providing, for the first time, large-scale, real-world paired data of camera poses and accurate object-level 3D trajectories.
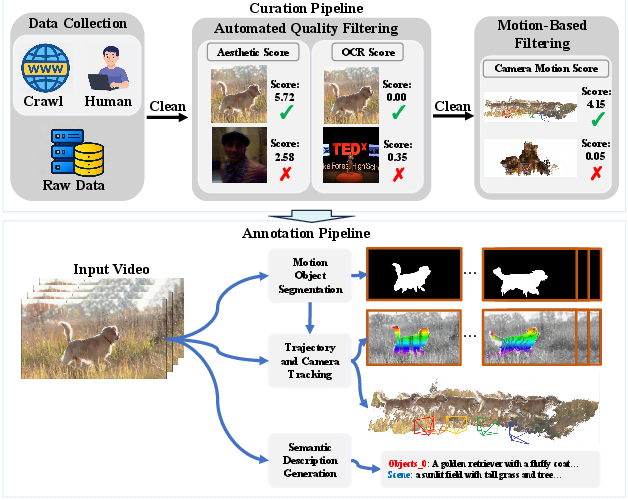
Figure 3: RealCOD-25K dataset construction pipeline, combining web-scale curation, automated motion/object filtering, and multi-stage geometric and semantic annotation.
Key steps:
- Data Collection and Filtering: 1M video clips curated and filtered for quality, motion diversity, and presence of dynamic entities.
- Annotation: SegAnyMo segments moving objects; SpatialTrackerV2 tracks object masks and recovers 2D/3D trajectories using state-of-the-art depth estimation; Qwen-2.5-VL-72B and associated modules generate semantic object captions and align behaviors.
- Manual Verification: Expert curation ensures high geometric and visual fidelity.
Experimental Results
Evaluation comprises both quantitative metrics and user studies, comparing SymphoMotion with CameraCtrl, ViewCrafter, Uni3C, and MotionCtrl baselines.
- Visual Quality: Measured by FID (Fréchet Image Distance) and FVD (Fréchet Video Distance), SymphoMotion achieves superior results (FID: 70.47, FVD: 332.50), indicating both spatial and temporal improvements.
- Camera Control: On CamTransErr and CamRotErr, SymphoMotion achieves the lowest errors (0.37, 0.05), reflecting highly accurate trajectory following.
- Object Control: SymphoMotion's Box-IoU (61.88) nearly doubles previous methods, denoting fine-grained adherence to ground-truth motion versus MotionCtrl (31.42).

Figure 4: Independent camera motion control—SymphoMotion accurately preserves scene structure under prescribed camera paths.

Figure 5: Simultaneous control over camera and object—SymphoMotion maintains object integrity during complex coordinated motion, resolving failure cases seen in MotionCtrl.
Ablation studies further highlight the criticality of 3D priors in CTC and both 2D and 3D conditioning in ODC. Removal of geometric cues or trajectory embeddings consistently degrades object or camera controllability.

Figure 6: Results of different settings in the ablation study, visualizing the impact of removing geometry-aware or trajectory conditioning.
Qualitative and User Study Analysis
User studies (rated 1-5) consistently preferred SymphoMotion across visual quality, semantic alignment, camera control, and object control. Notably, object motion scores (4.58) contrasted with the substantially lower 2.87 for the closest baseline. Qualitative comparisons in diverse scenes—static and dynamic—show robust maintenance of spatial relationships and a marked absence of entity drift or disappearance (common in previous methods).
Inference System and Interface
SymphoMotion features an interactive interface that supports real-time user specification of both viewpoint and dynamic object paths. The workflow—mask selection, camera path editing, and 3D trajectory manipulation—offers practitioners high-level flexibility for content creation and scene design.
Implications and Future Directions
SymphoMotion represents a convergence of geometric vision and large-scale generative modeling, grounding motion control in explicit 3D reasoning. This architecture paves the way for robust, user-steerable video generation in animation, VFX, robotics, and simulation, where concurrent viewpoint and object manipulation are required. RealCOD-25K fills a critical gap in available benchmarks and should catalyze further advances in unified 3D-aware generative tasks.
Potential future directions include:
- Extending to multi-object, physically plausible interaction modeling.
- Robustness under extreme or out-of-distribution scenes.
- Integrating time-continuous control for long-horizon planning.
- Scaling to open-domain text-conditioned scenarios.
Conclusion
SymphoMotion demonstrates that high-fidelity, coherent joint control over both camera motion and object-level dynamics is achievable within a single model via 3D-aware embedding and flexible architecture. With robust numerical gains over prior methods and a comprehensive new dataset, it establishes new standards for controllable video generation and will serve as a foundation for subsequent research in unified motion and scene control (2604.03723).