- The paper introduces full-sequence masking during training to unlock bidirectional prompt infilling capabilities in diffusion LMs.
- Empirical results on GSM8K and SummEval show that infilled prompts achieve comparable or superior performance with significantly fewer tokens.
- The approach streamlines prompt engineering by eliminating external optimization pipelines and enhancing model transfer across various tasks.
Prompt Infilling Capabilities in Masked Diffusion LLMs
Introduction and Motivation
Masked Diffusion LLMs (dLMs) generate text through bidirectional, iterative denoising, making them architecturally well-suited for infilling any span of text given its context. Despite this theoretical capacity, existing fine-tuning protocols for diffusion LMs constrain infilling to response sections during supervised fine-tuning (SFT), leaving the "prompt infilling capability" effectively locked. This work identifies the training-induced bottleneck restricting prompt infilling: exclusive masking of responses during SFT introduces a training-inference mismatch, and bidirectional infilling is not realized in deployed models despite architectural support.
The authors propose a minimal yet consequential adjustment: extending SFT to encompass full-sequence masking, thereby exposing both prompts and responses to noise in training. This adjustment unlocks prompt infilling capabilities, enabling the generation of high-quality, task-adapted prompt templates directly from few-shot examples. The resulting pipeline for prompt infilling is depicted below.
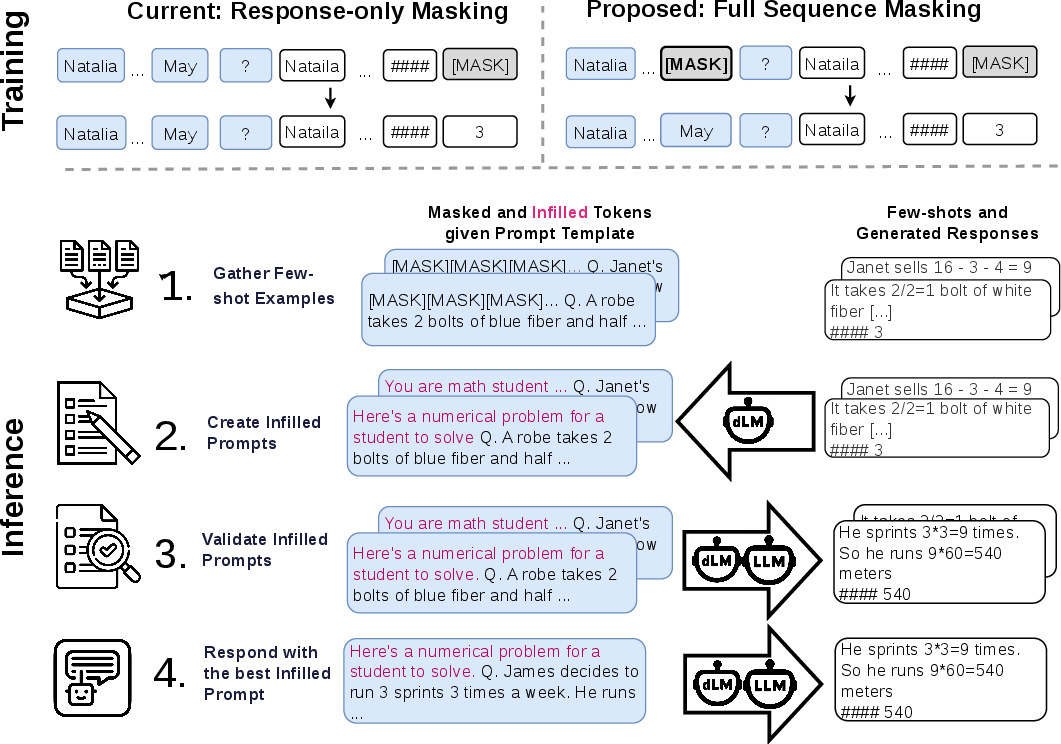
Figure 1: Overview of the prompt infilling procedure and the change in training. Both prompts and responses are masked during SFT (unlocking infilling), and during inference, the model infills prompt templates conditioned on few-shot reference responses, validates candidates, and selects the optimal prompt for downstream use.
Methodology
Full-Sequence Masking Protocol
During SFT, rather than restricting the mask to response tokens, random masking is applied across the entire prompt-response pair. This allows the model to learn and generalize bidirectional denoising, i.e., the ability to recover masked prompt tokens conditioned on observed responses. The loss function covers both prompt and response tokens without bias, unlike the conventional regime.
A two-stage sequence is also proposed: First, train with full-sequence masking; then, optionally refine with standard response-only masking to further optimize downstream generation capabilities for some tasks.
Prompt Infilling Procedure
At inference, a partially masked prompt template and corresponding few-shot reference responses are provided. The diffusion LM infills the masked tokens iteratively, producing candidate prompts. Candidates are validated on few-shot examples (e.g., via downstream metrics or model output quality), and the highest-performing prompt is fixed for amortized inference on test data.
Empirical Analysis
Training-Inference Gap Validation
Evaluation on arithmetic reasoning (GSM8K) and LLM-as-a-Judge tasks provides compelling evidence for the central claim: models fine-tuned with response-only masking fail at prompt infilling, typically generating trivial outputs (e.g., runs of end-of-text tokens) in the masked regions. Full-sequence masking is required for meaningful infilling.
A robust set of experiments shows that infilled prompts produced by full-sequence-masked dLMs:
- Achieve comparable or superior performance to hand-designed templates on multiple tasks
- Are transferable across models and checkpoints
- Enable strong prompt compression, condensing necessary reasoning strategies into concise prompts while maintaining or boosting accuracy
On GSM8K, prompt infilling with fully-trained LLaDA achieves 76.4% exact match accuracy with shrunk prompts (316 tokens), while standard 16-shot in-context learning consumes an order of magnitude more context tokens (3334) for 73.1% accuracy. The trend holds for other models (Dream, etc.).
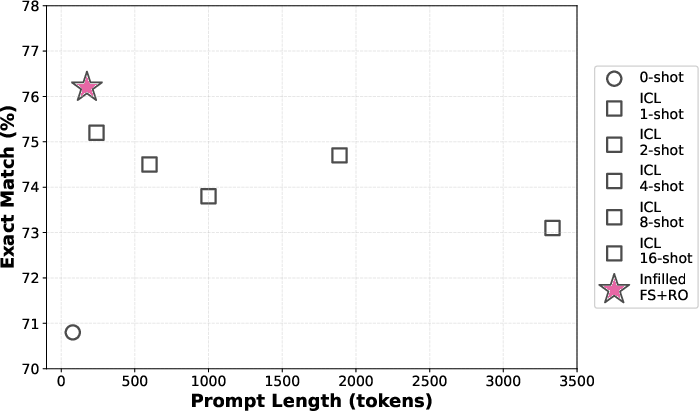
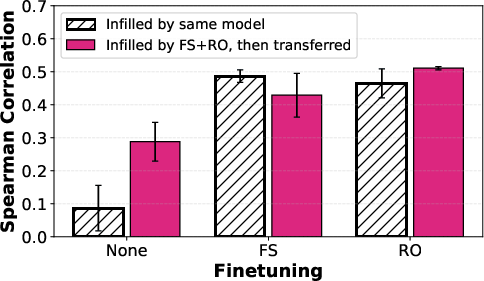
Figure 3: Infilling enables ultra-compact prompts—significantly higher accuracy at a fraction of the prompt length compared to in-context learning baselines on GSM8K.
Further, on SummEval (LLM-as-a-Judge), infilled prompts generated via FS+RO models yield highest correlations with human judgments, outperforming manually constructed and externally optimized templates. The bidirectionality and learned template reconstruction from full-sequence SFT are essential—public checkpoints lacking FS masking show negligible human correlation with infilled prompts, confirming that the infilling ability is gated by training, not model architecture.
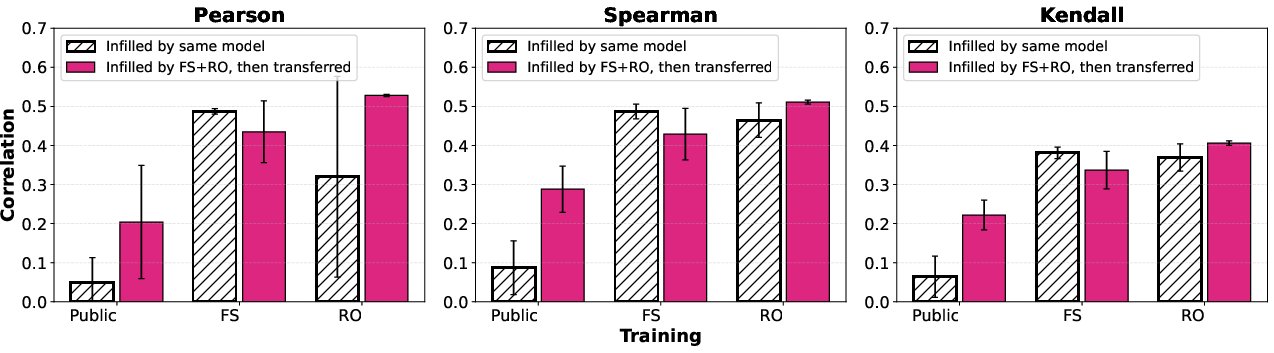
Figure 5: Prompt transfer evaluation shows infilled prompts (trained under FS+RO) consistently boost evaluation metrics across LLaDA checkpoints on SummEval.
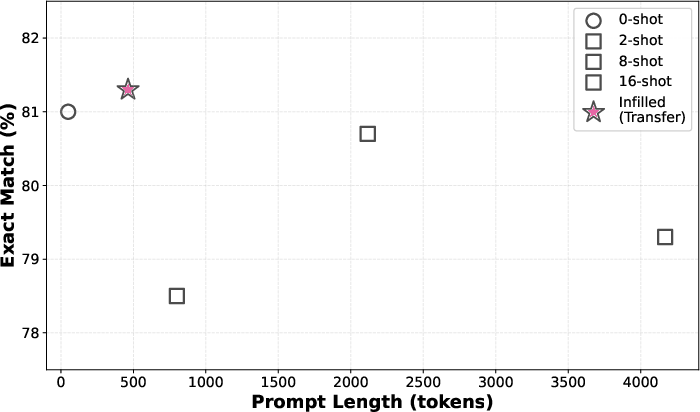
Figure 2: For Dream checkpoints on GSM8K, the infilled prompt (red star) achieves best-in-class accuracy with far fewer tokens than extensive few-shot setups.
Diffusion Perplexity and Template Analysis
Analysis with the diffusion perplexity (PPL) metric shows that full-sequence masking produces robust generalization and substantially lower perplexity on diverse tasks—evidence that the model's learned distribution aligns better with downstream data.
Template-dependent results show that prompt formats used during fine-tuning (e.g., the Judge template) are recovered with minimal perplexity by full-sequence-masked models, speaking to their generalized infilling proficiency.
Prompt Transfer and Combination with Prompt Optimization
Experiments demonstrate that infilled prompts generated by well-trained dLMs can be ported to weaker or differently-trained models, improving their evaluation performance. Moreover, dLM infilling is complementary to external prompt optimization techniques (e.g., evolutionary search [GEPA], hill-climbing [COPRO]). Applying infilling to prompts generated by optimization pipelines can further refine and localize edits in templates, achieving compounded gains in human correlation metrics.
Implications and Future Directions
This work establishes that the primary limitation in recent dLMs' prompt infilling capability is not architectural, but resides solely in training protocol. Full-sequence masking is a low-overhead prescription that unlocks latent capacities intrinsic to diffusion-based modeling.
The theoretical implication is significant: modern architectures may harbor dormant capabilities not expressed due to under-exposure in training, suggesting that capacity-based innovation should extend beyond architecture to encompass fine-tuning objectives and curriculum design.
Practically, this finding elevates dLMs as competitive tools for automated prompt design. They can:
- Compress few-shot knowledge into highly effective, transferable prompt templates
- Substitute for intrusive external optimization pipelines in tasks needing adaptive prompt engineering
- Enhance interoperability and robustness in prompt-based LLM deployments
The complementarity to autoregressive prompt optimization methods (such as OPRO, GEPA, and DSPy pipelines) points toward unified frameworks leveraging both evolutionary search and targeted infilling for controllable prompt construction.
Future directions include systematic investigation of finer-grained masking schedules, studies of generalization to zero-shot and cross-linguistic setup, extension to multimodal prompt infilling, and the development of defensive (anti-leakage) and interpretability tools for prompt reconstruction.
Conclusion
Extending SFT with full-sequence masking unlocks prompt infilling in diffusion LMs, not by architectural enhancement but by correcting the training signal. Empirical evidence across reasoning and evaluation tasks supports that appropriately-trained dLMs achieve state-of-the-art prompt generation and transfer, enabling highly compressed, effective templates that generalize across models. This result motivates re-examination of current fine-tuning conventions throughout the language modeling landscape, emphasizing the pivotal role of training protocol as a lever for model capability.