- The paper introduces Synapse, a two-phase retrieval system that integrates LLM-guided genetic resume optimization to enhance candidate-job alignment.
- It employs a scalable ensemble of rerankers and retrieval-augmented generation for explainable recommendations, achieving up to 31.9% nDCG@10 improvement.
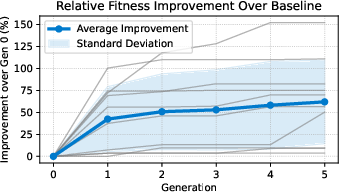
- The evolutionary resume optimization process yields median fitness gains of 62% through iterative, label-free population-based refinement.
Synapse: A Multi-stage, Explainable Recruitment Recommender with LLM-guided Evolutionary Resume Optimization
Introduction and Motivation
The paper presents Synapse, a recruitment recommender system targeting the longstanding challenges of semantic candidate-job alignment, retrieval precision, and transparency in digital hiring flows (2604.02539). The proliferation of job postings and applicant volume has rendered existing keyword-based and embedding-only systems inadequate due to their inability to capture fine-grained, latent alignments and enforce explicit constraints, especially within highly dynamic and data-limited recruitment environments.
Synapse addresses these limitations with a multi-stage architecture combining high-recall dense retrieval with high-precision semantic reranking and contextual explainability. A novel contribution is the LLM-guided, evolutionary resume optimization loop, which iteratively refines candidate resumes towards better alignment with recruiter screening objectives, operationalized entirely in a label-free, black-box setting.
System Architecture: Two-phase Retrieval and Explainability
The Synapse pipeline is structured as a scalable two-phase recommender, carefully designed to partition efficiency-critical broad search from computationally expensive, context-sensitive reranking.
In Phase I, both resumes and job postings are embedded into a shared semantic space using a lightweight Sentence-BERT variant. Fast approximate nearest-neighbor search over a FAISS index retrieves top-K candidates, aggressively prioritizing recall and throughput over precision.
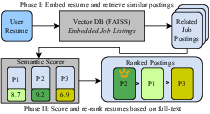
Figure 1: The Synapse recommender pipeline combines high-recall dense retrieval with precise semantic reranking.
Phase II then applies multiple more expressive reranking models to the retrieved subset: (1) deeper embedding similarity with higher-dimensional latent spaces, (2) a contrastive learning model trained on augmented resume-job pairings with a RoBERTa backbone and a token-aligned triplet loss to maximize semantic robustness, and (3) pairwise preference modeling using LLMs, which proved superior to direct scalar scoring. A variety of ensemble strategies (including weighted averaging, Borda count, and Reciprocal Rank Fusion) were explored for optimal aggregation, with weighted averaging yielding the highest nDCG improvements.
Complementing this retrieval stack, Synapse introduces an explainability module grounded in Retrieval-Augmented Generation (RAG). Here, relevant evidence snippets are extracted from both the resume and job description, and provided to an LLM, which generates textual rationales for recommendations. This mitigates user trust issues and hallucination risk inherent to opaque neural models, and provides actionable feedback for applicants.
LLM-guided Evolutionary Resume Refinement
A key innovation of Synapse is modeling resume optimization as a black-box, population-based search. The system operationalizes fitness as the weighted sum of embedding distance, contrastive model similarity, and LLM preference—all computed against a target posting set—with empirical weighting heavily favoring embedding alignment ($0.7$), and smaller contributions from the higher-precision rerankers.
The evolutionary process initializes a population of mutated resumes via temperature-controlled section rewriting (mutation), employs LLM-driven semantic merging (crossover), and ensures elitism for monotonic fitness improvement. Aggressive mutations become more probable in later generations to promote escape from local optima. Fitness-based selection iteratively advances the population, yielding resumes with progressively better system alignment, with no need for labeled data or human intervention.
Experimental Evaluation
The Synapse system was rigorously evaluated for computational efficiency, retrieval quality, and the effectiveness of the evolutionary refinement loop. Key findings include:
Quantitatively, the evolutionary loop achieved monotonic fitness improvement, yielding median, mean, and upper-quartile gains of 62%, 68%, and 92% respectively, as measured by the composite objective function across top-ranked job postings.
Implications and Future Directions
The Synapse system offers several immediate and longer-term implications:
- Recruitment System Design: The demonstrated architecture provides a practical blueprint for scalable deployment in high-volume recruitment settings. The strong gains from ensemble reranking and explainability mechanisms underscore the limits of single-model semantic similarity and highlight the value of integrating orthogonal signals.
- Interactive Career Optimization: The LLM-guided evolutionary loop offers a data-agnostic, modular framework for automated, system-aligned resume refinement, which can be generalized to broader document optimization and recommendation tasks.
- Bias and Data Scarcity: While the system circumvents the need for large-scale labeled data, its reliance on automated fitness metrics introduces potential for encoding and perpetuating algorithmic biases inherent in underlying embedding or LLM models. As such, research on augmenting supervision via synthetic labeling, adversarial debiasing, and expanded transparency auditing is warranted.
- LLM Cost Tradeoffs: The latency and cost overhead of LLM-based evaluation remains the limiting factor for real-time, large-scale deployment. Continued advances in efficient LLMs or distillation approaches will be required for practical adoption.
Conclusion
Synapse advances recruitment recommendation by tightly integrating scalable two-phase retrieval, transparent RAG-style explainability, and a novel LLM-driven evolutionary optimization for resumes. The system realizes strong empirical improvements—up to 31.9% nDCG@10 over basic embeddings, and 62–92% evolutionary fitness gains—without requiring extensive labeled data. Ongoing work may focus on further efficiency optimizations, robustifying fitness objectives, and expanding explainability to address trust and bias in human-centric AI systems.