- The paper demonstrates a transformer-based framework using a SwinV2-UNet for high-fidelity spatiotemporal forecasting of complex fluid flows.
- It integrates multimodal conditioning and autoregressive rollouts to accurately model gas injection dynamics and reconstruct unobserved fields.
- Empirical results highlight robust performance and scalability, paving the way for next-generation data-driven surrogates in energy systems.
Introduction
The presented study establishes a transformer-based multimodal modeling framework specifically designed for predictive modeling of complex, high-pressure fluid flows in energy systems, with a detailed demonstration on gas injection dynamics in reciprocating engine analogues. By leveraging a hierarchical, context-aware SwinV2-UNet vision transformer, the model processes multi-fidelity CFD-derived datasets—spanning multiple grid resolutions, turbulence closures, and equations of state—while incorporating auxiliary tokens that explicitly encode modality and temporal increment information. Two cornerstone tasks are addressed: autoregressive spatiotemporal rollouts for forward prediction, and cross-modality feature transformation for reconstructing unobserved or unmeasured fields.
SwinV2-UNet Architecture and Conditioning
The core of the framework is a SwinV2-based encoder-decoder design, which hierarchically encodes spatial context through shifted windowed self-attention and convolutional skip connections for multiscale feature fusion. Input flow fields, organized as multimodal 2D projections or slices, are partitioned into non-overlapping patches and embedded as local tokens. The architecture achieves linear complexity with respect to input size, crucial for large-scale, high-resolution physical simulations, and balances the global context with strong inductive biases via hybrid transformer-convolutional modules.
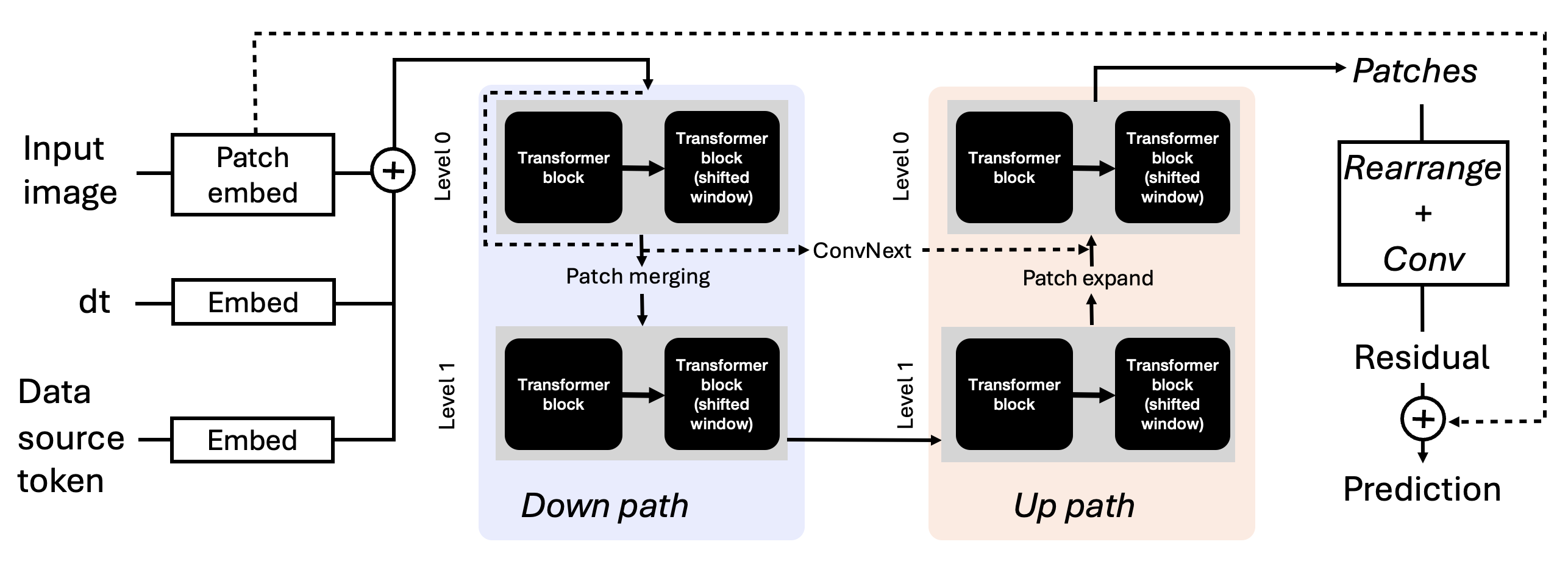
Figure 1: Schematic overview of the SwinV2-UNet used for spatiotemporal prediction, showcasing hierarchical encoding/decoding with modality and timestep conditioning.
The model employs auxiliary embeddings for both tasks: a time-step embedding captures temporal increments for autoregressive rollouts, while a dataset-specific embedding encodes grid resolution, physical modality, and turbulence closure. This conditioning permits the network to generalize effectively across heterogeneous data sources.
Spatiotemporal Rollouts: Dynamics Forecasting
In spatiotemporal prediction, the model is trained to forecast the temporal evolution of flow fields, updating states autoregressively. Three distinct training paradigms are compared: (1) single-step training, (2) multi-step rollout (with backpropagation-through-time), and (3) pushforward rollout (loss applied only at terminal step to reduce computational burden and error accumulation).
Qualitative and quantitative assessment on held-out LES, fine-grid, ideal gas cases reveal the model's robustness in capturing macroscopic jet evolution, sharp interfaces, and bulk motion, as depicted for projected, sliced, and transverse densities and velocities (Figures 2–4). The error is consistently lowest in contiguous regions but rises in complex turbulent zones, manifesting a smoothing effect.
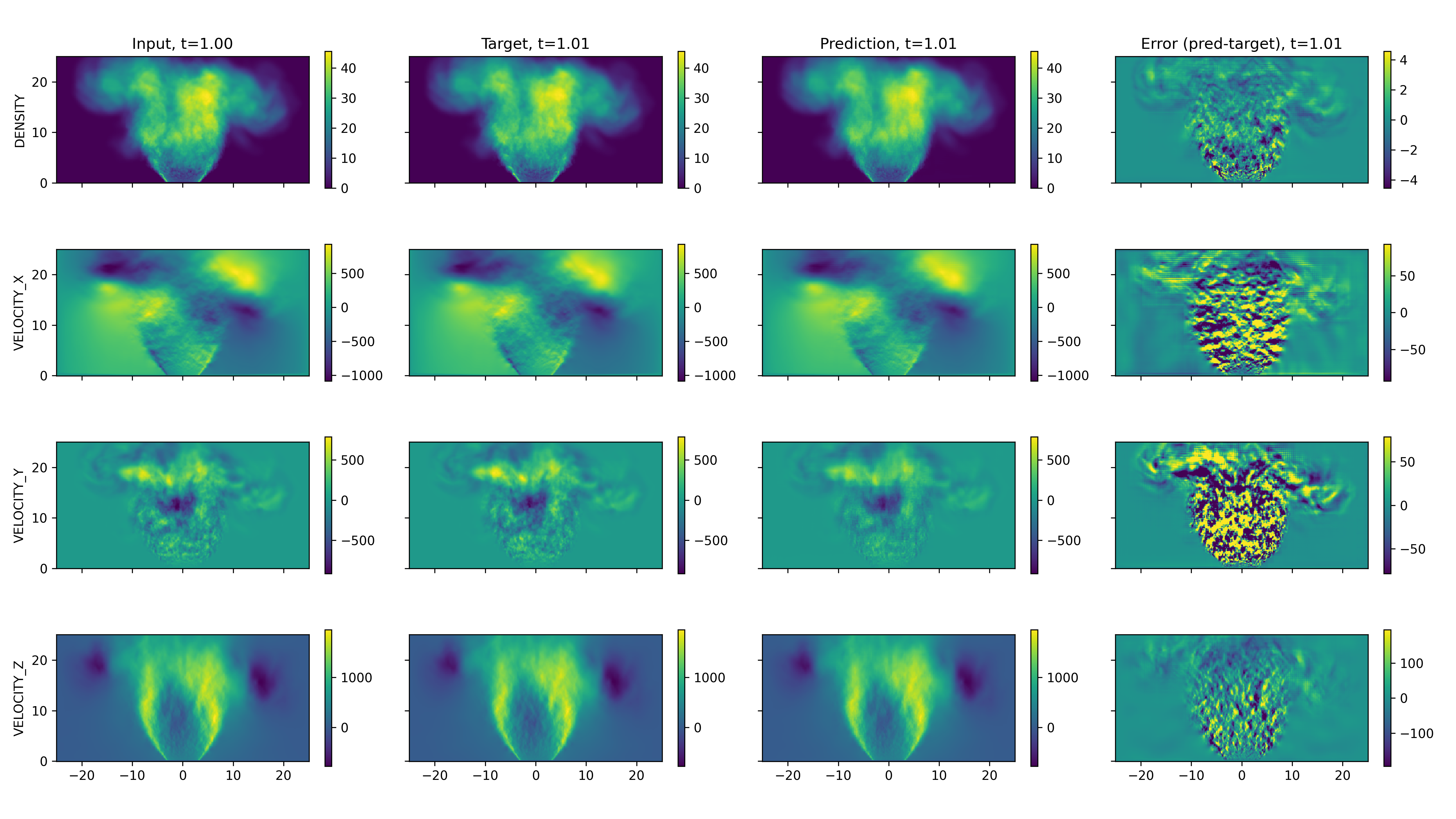
Figure 2: Predictions for longitudinal projected variables; local errors are minimal at jet fronts but higher in fine-scale turbulent regions.
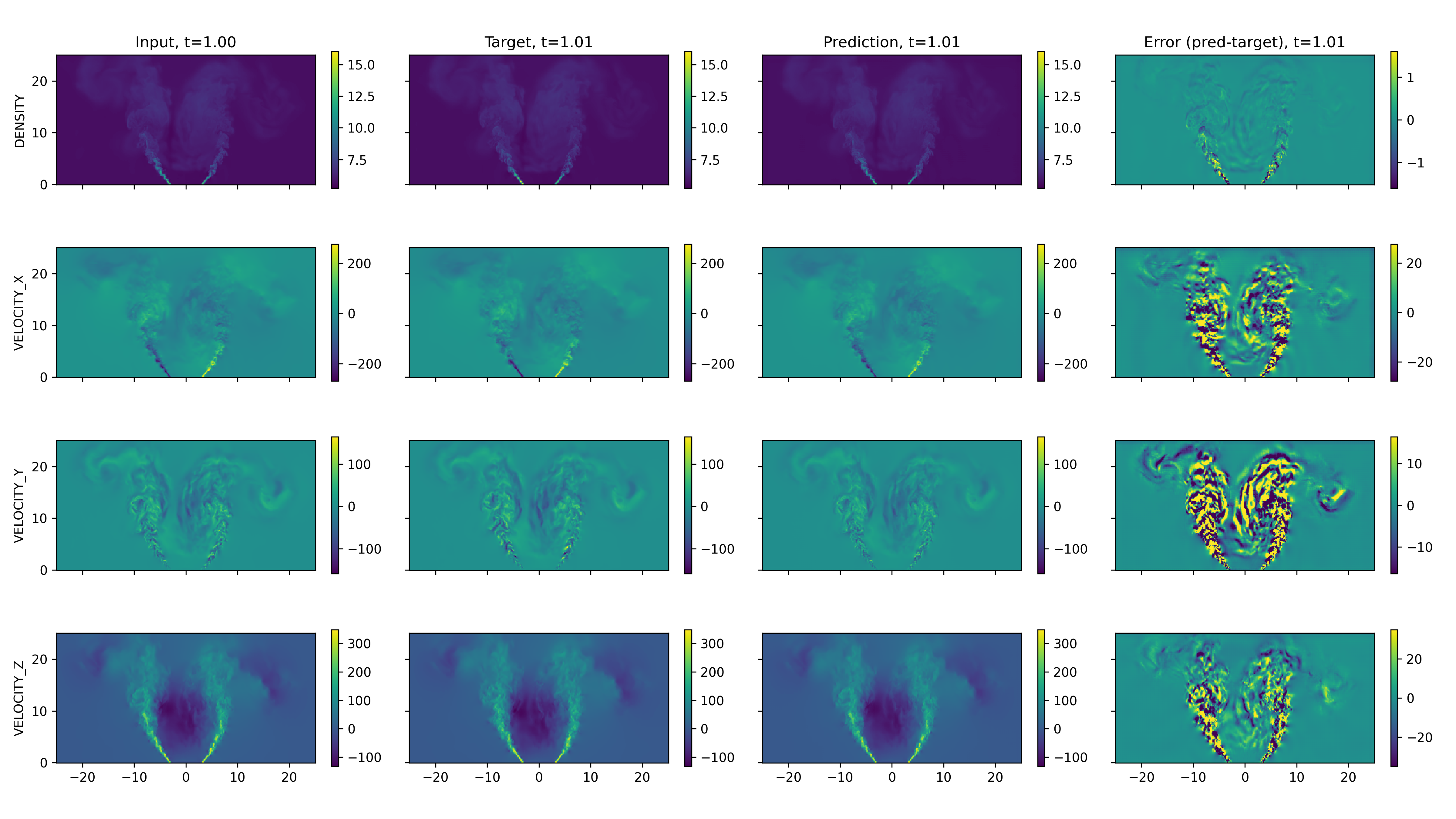
Figure 3: Longitudinal slice spatiotemporal rollouts reveal similar patterns in capturing bulk features and transitional structures.
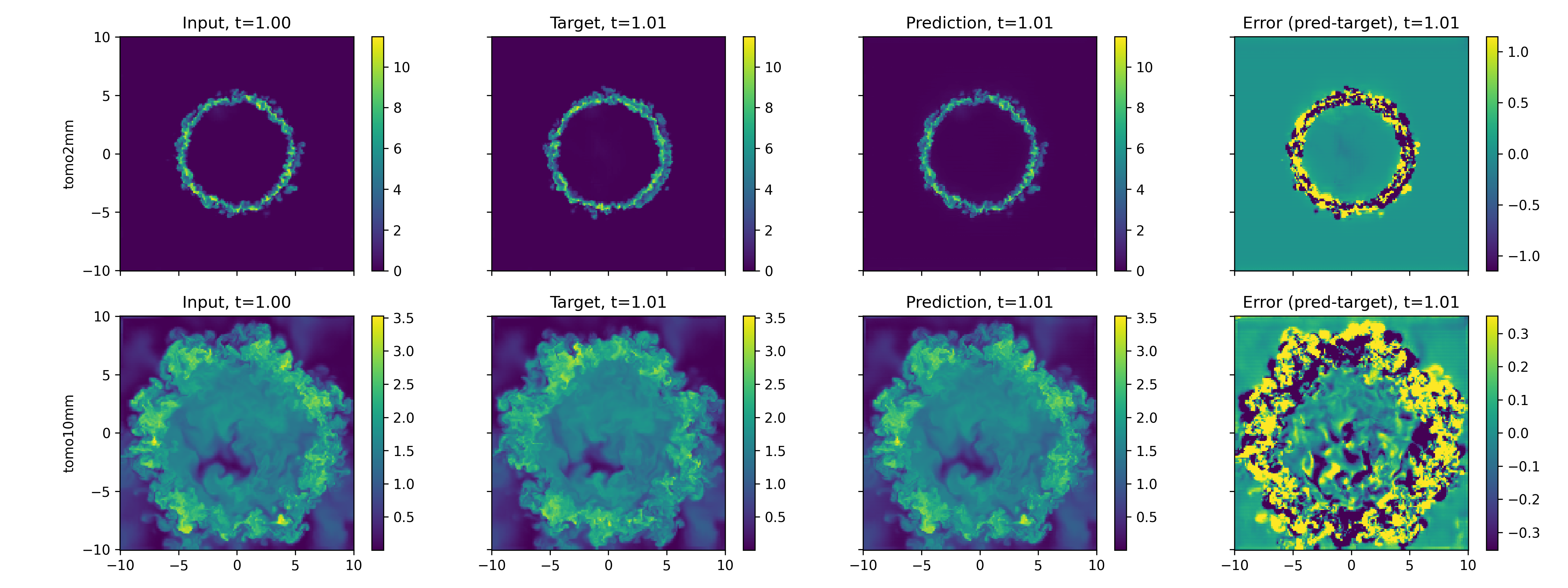
Figure 4: Accurate prediction of density on transverse planes; local errors indicate regions of strong mixing and small-scale turbulence.
Multi-step rollout and pushforward variants are empirically validated to better capture intrinsic small-scale details relative to the single-step baseline, albeit with modestly larger MAE due to gradual error accumulation (Figures 5–8). This directly quantifies the trade-off between local-step accuracy and long-horizon physical fidelity, essential for stable surrogate integration in design loops.
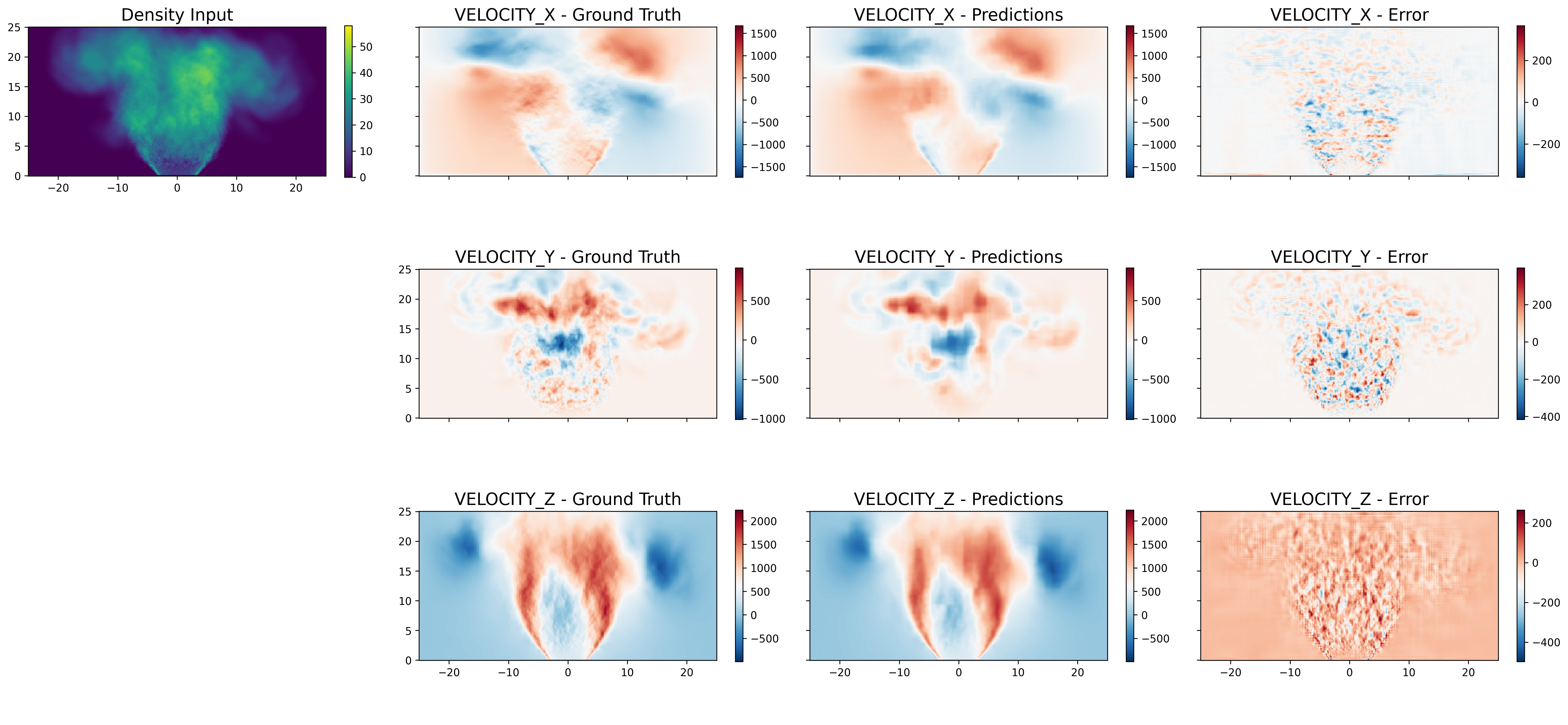
Figure 5: Multi-step rollout predictions for longitudinal projected density; error increases with step count but structural coherence is preserved.
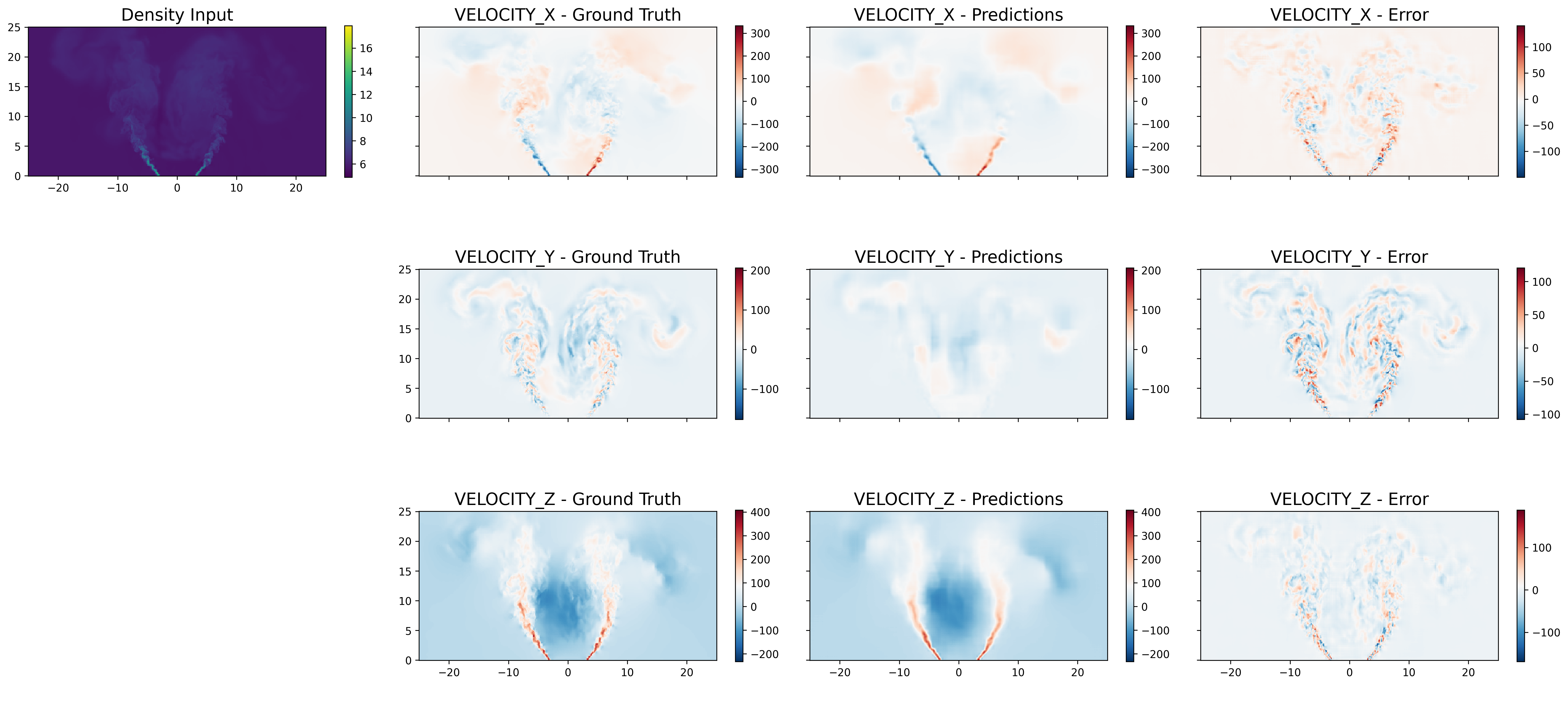
Figure 6: Rollout for longitudinal slice density demonstrates preservation of flow features across time steps.
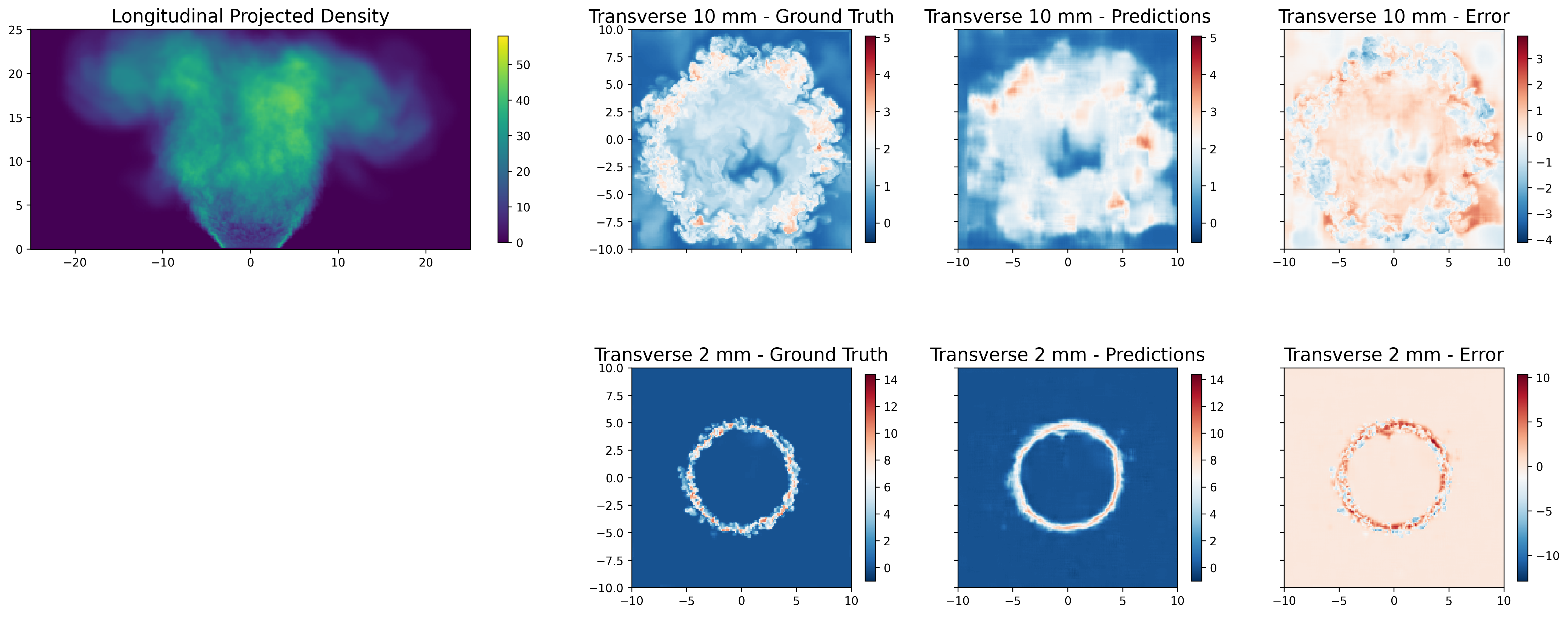
Figure 7: Rollout for transverse slice at z=2~mm; models generalize across spatial planes.
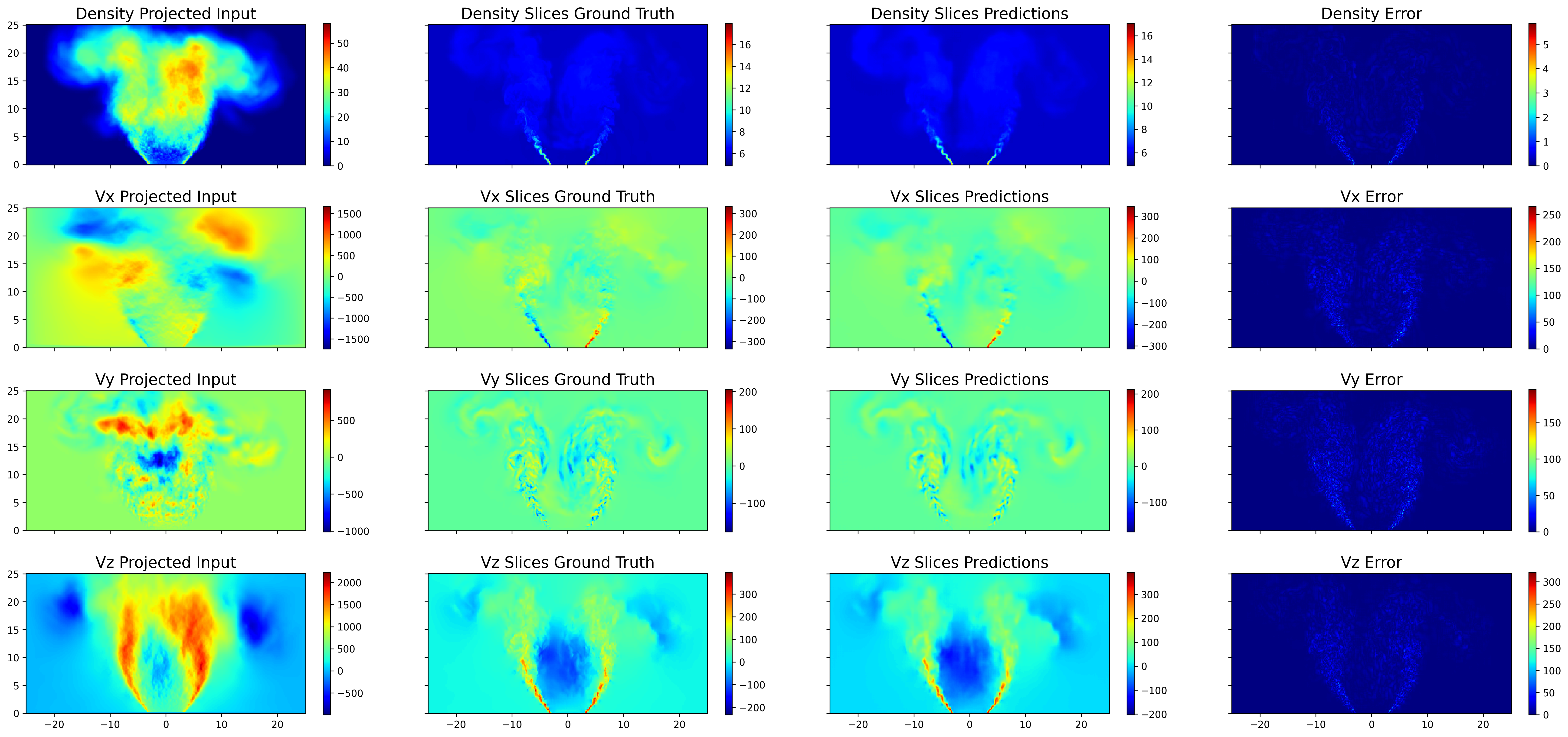
Figure 8: Rollout for transverse slice at z=10~mm; subsequent spatial evolution remains physically consistent.
Feature transformation tasks probe the ability to reconstruct missing or unmeasured fields at a given time from observed variables. Five cases are explored, encompassing in-plane and cross-plane mapping, projection-to-slice inversion, and spatial transfer:
- Density to velocity inference: The model reconstructs velocity components from density distributions. High fidelity is achieved for in-plane velocities (u, w), with reduced accuracy for out-of-plane (v), reflecting information-theoretic limits of 2D-to-3D inference.
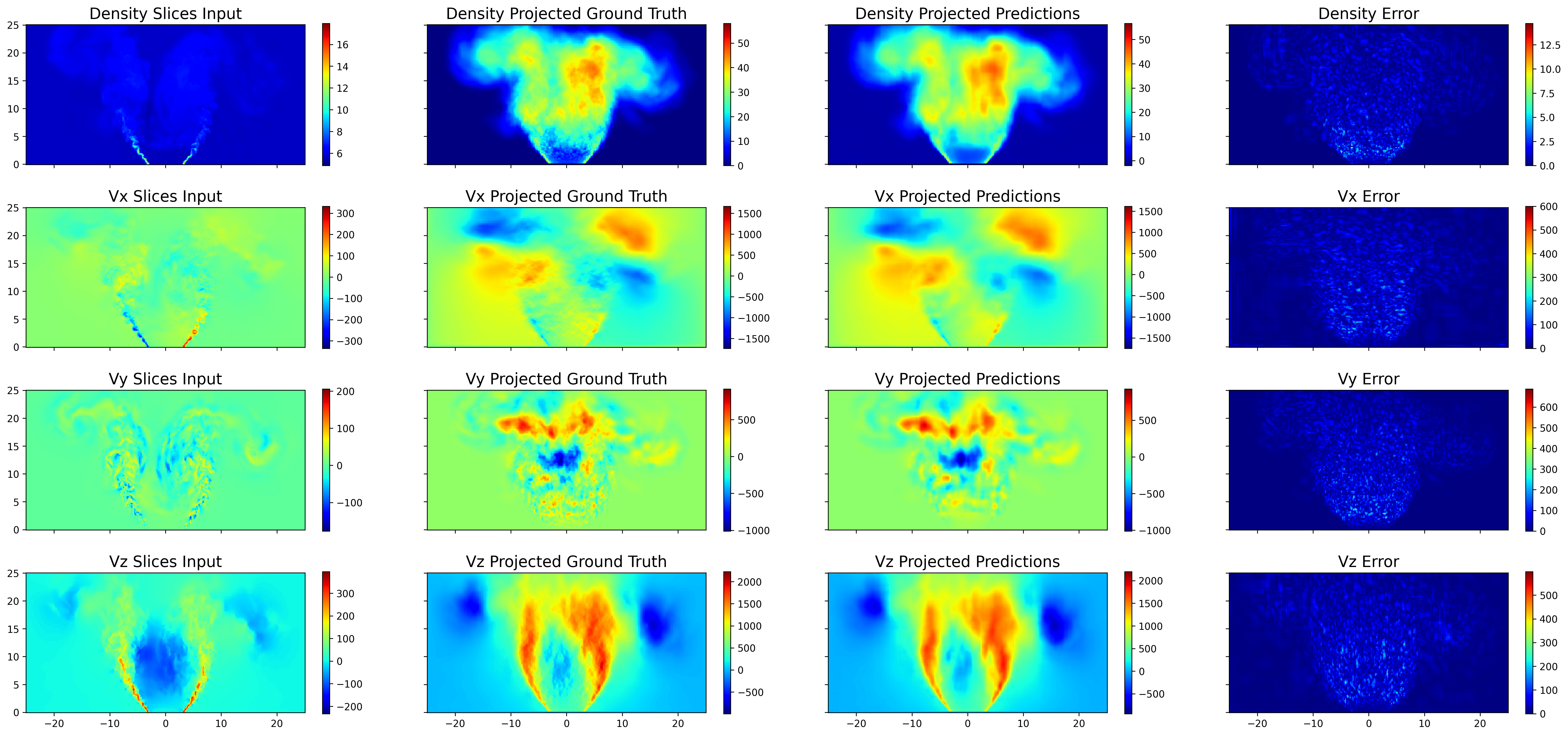
Figure 9: Predicted velocity components from longitudinal projected density highlight strong performance in-plane and smoothing in out-of-plane component.
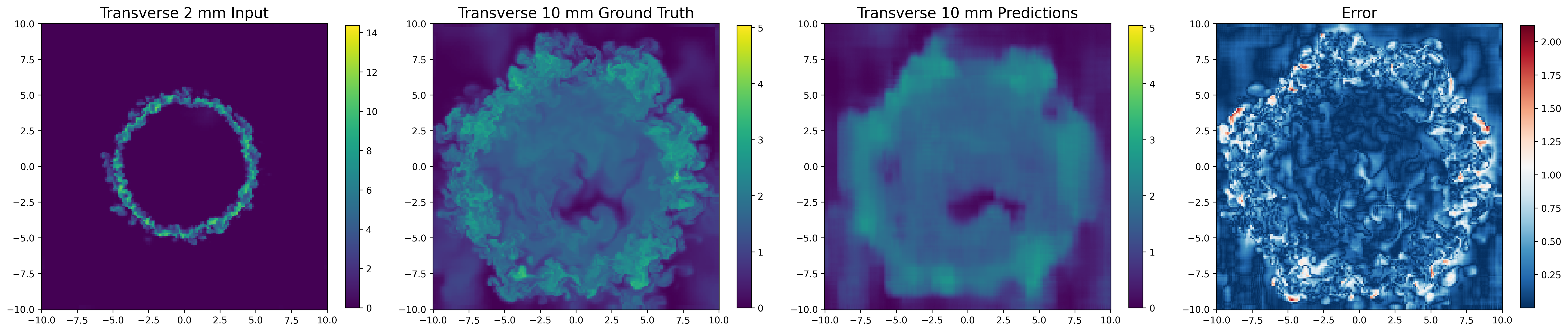
Figure 10: Analogous mapping from longitudinal slice density to velocities confirms overall trends and error localization.
- Longitudinal projection to transverse slice: The model reconstructs transverse slices from projections, achieving consistent mapping of large-scale features, though smoothing of turbulence is evident.
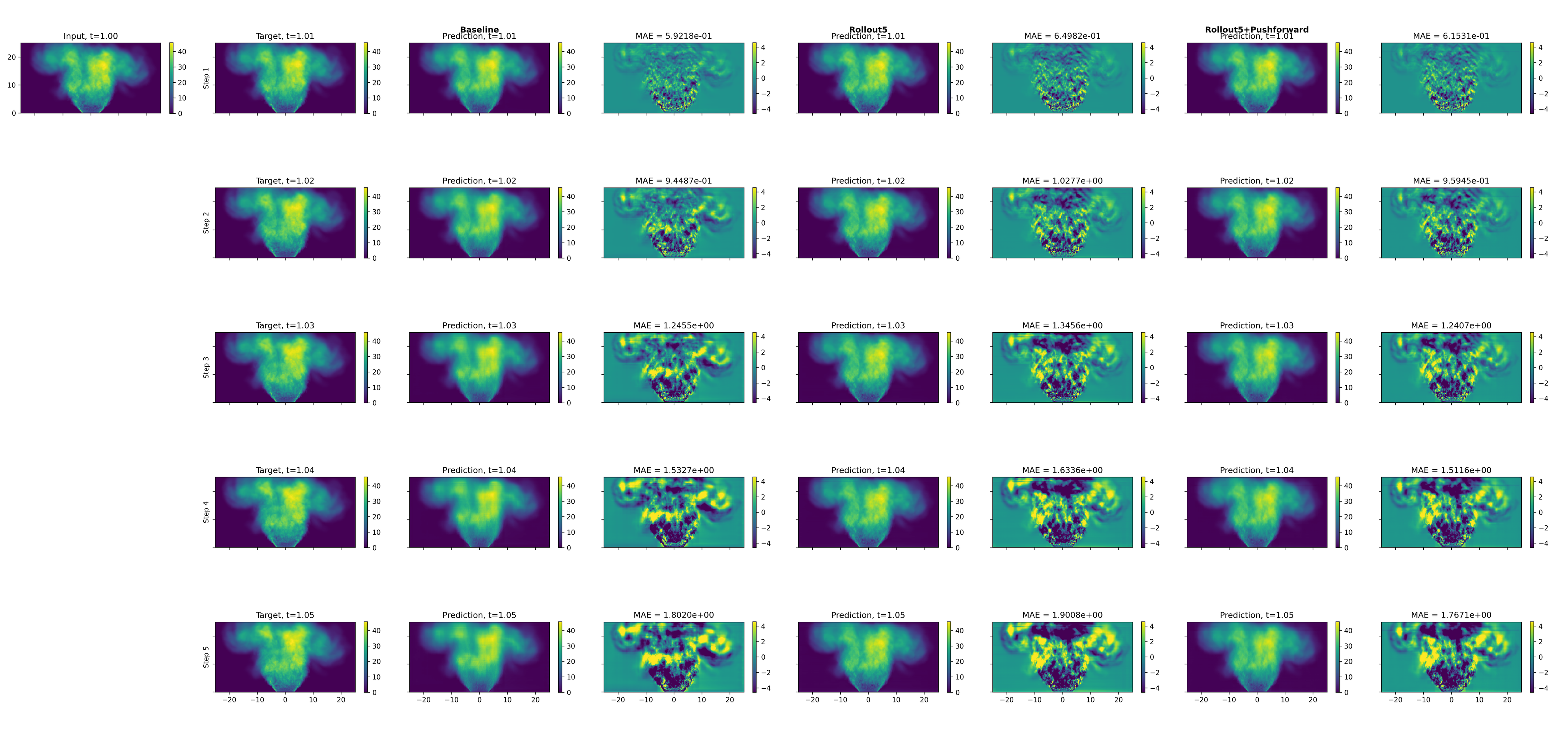
Figure 11: Inverse transform from projection to transverse slice recovers dominant spatial structures but with reduced fine-scale texture.
- Multimodal fusion and projection/slice aggregation: Integrating projected density and velocity yields accurate slice reconstruction, and vice versa for aggregation.
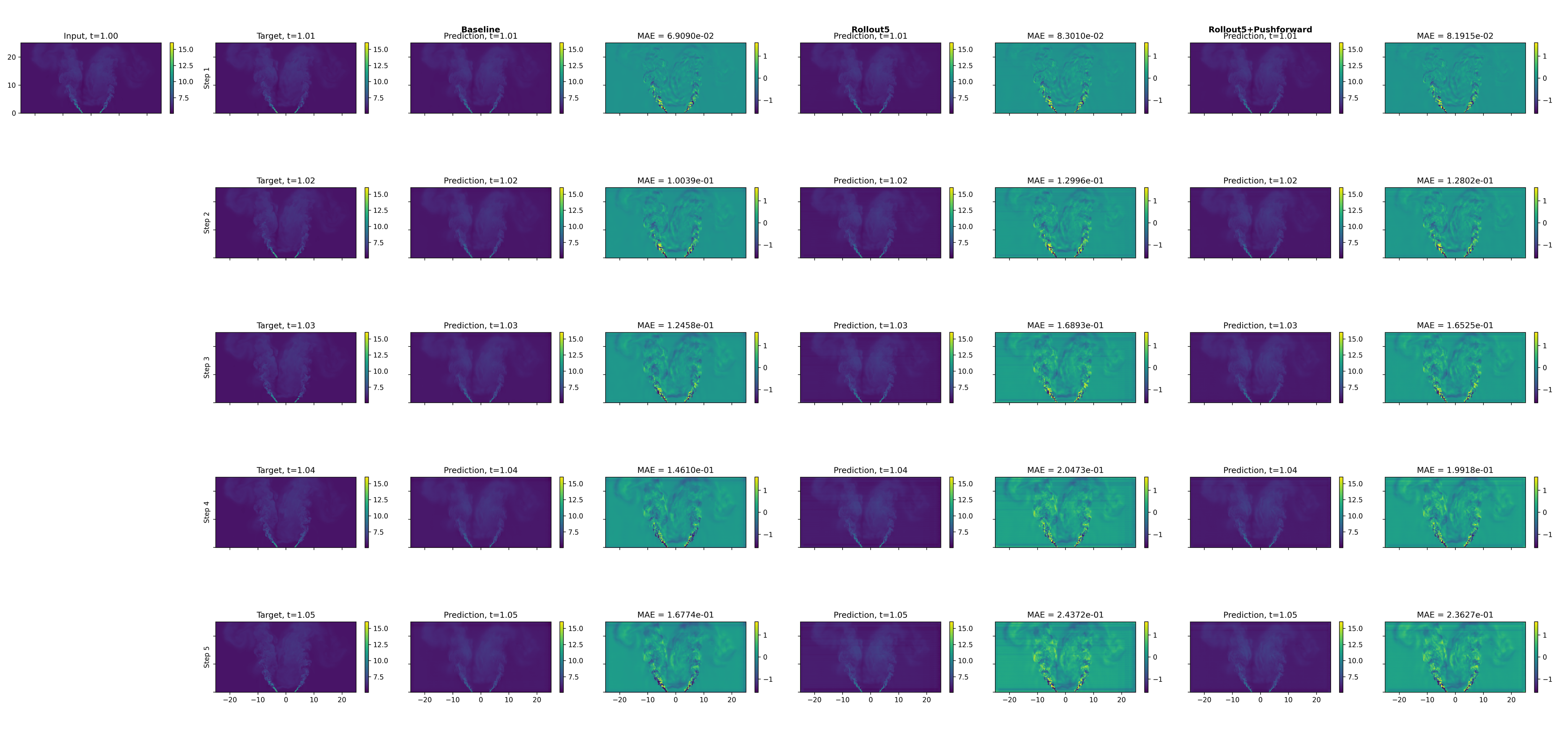
Figure 12: Joint mapping from projected to slice fields demonstrates model's multimodal fusion capabilities for both density and velocity.
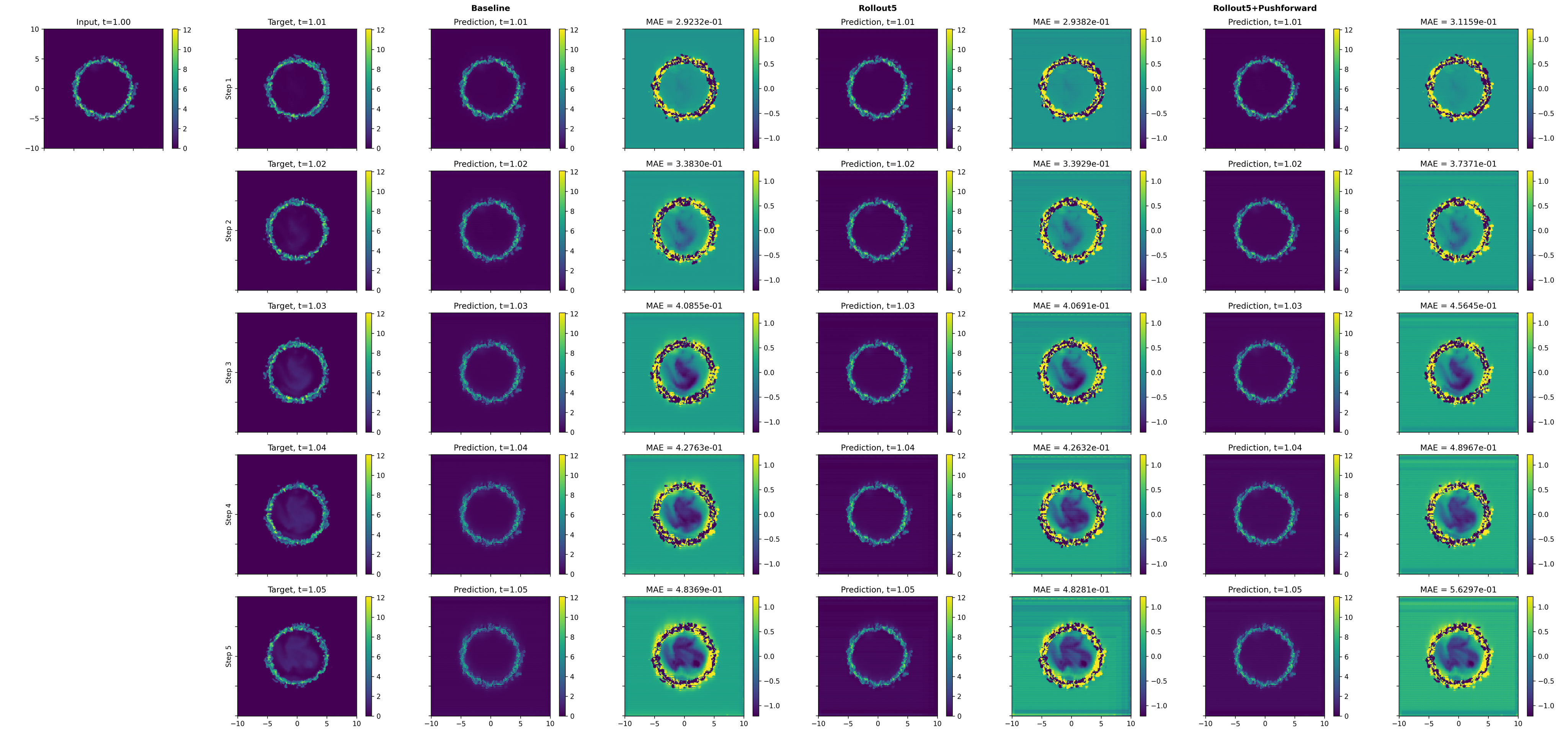
Figure 13: Aggregation from local slices to projected density/velocity recovers global structure, illustrating the bidirectional mapping's efficacy.
- Cross-plane transfer: Transfer between z=2~mm and z=10~mm planes is feasible, transferring large-scale patterns downstream but with increasing smoothing over distance.
Figure 14: Cross-plane density transfer accurately propagates jet expansion and mixing, with some loss of fine structure.
Across all feature transformation tasks, output fields are qualitatively and quantitatively coherent, with mean error escalating in scenarios requiring inherent out-of-plane or cross-modal reasoning. The smoothing artifact—also observed in similar generative or inverse surrogate tasks for PDEs—is prominent when underlying physical ambiguity is present.
Implications and Future Directions
This multimodal transformer-based framework demonstrates that SwinV2-UNet architectures, when properly conditioned, are capable of generalizing both temporally and across heterogeneous modalities in realistic, non-idealized engineering flow regimes. Notably, the same architectural backbone achieves strong results in both temporal rollout and cross-modal inference, effectively bridging the simulation-measurement gap for engineering surrogacy.
From a practical standpoint, this work signals a pathway towards deployment of unified neural surrogates that could replace or deeply accelerate expensive CFD runs in engine design and optimization, uncertainty quantification, or real-time control. The conditioning and training methodology directly supports heterogeneous and multi-fidelity data assimilation, which is crucial as high-fidelity simulation and experimental datasets proliferate.
Theoretically, the results validate that windowed vision transformers, with sufficient inductive bias and context encoding, efficiently model the family of compressible Navier–Stokes flows even under multimodality, outperforming per-case operator-learners that cannot generalize across resolutions or modalities.
The study also identifies distinct avenues for further research:
- Scaling to even broader classes of physics and mesh representations through incorporation of graph or point-cloud encodings.
- Fast training and inference in exascale simulation regimes via advanced parallelization techniques (e.g., SWiPe).
- Incorporation of probabilistic and masked-latent training strategies for improved uncertainty propagation and robustness (e.g., OmniCast).
These directions will underpin next-generation scientific foundation models for fluid mechanics and related fields.
Conclusion
This work establishes a robust, scalable framework for multimodal spatiotemporal forecasting and cross-field inference in high-fidelity fluid dynamics, leveraging advanced hierarchical vision transformers (SwinV2-UNet) with rich modality and temporal conditioning. The approach attains high accuracy and coherence across a suite of challenging prediction and transformation tasks on multi-fidelity, multi-modal CFD datasets representative of engine-relevant flows. While fine-scale turbulence is not fully resolved—mirroring persistent limitations of data-driven surrogacy—the generalization across physics, resolution, and measurement modality is a substantive advance. This framework provides a foundation for data-driven surrogate deployment in real-world scientific workflows and motivates expansion toward ever more general, physical, and scalable neural operators in scientific machine learning.