Model-Based Reinforcement Learning for Control under Time-Varying Dynamics
Published 2 Apr 2026 in cs.LG and cs.RO | (2604.02260v1)
Abstract: Learning-based control methods typically assume stationary system dynamics, an assumption often violated in real-world systems due to drift, wear, or changing operating conditions. We study reinforcement learning for control under time-varying dynamics. We consider a continual model-based reinforcement learning setting in which an agent repeatedly learns and controls a dynamical system whose transition dynamics evolve across episodes. We analyze the problem using Gaussian process dynamics models under frequentist variation-budget assumptions. Our analysis shows that persistent non-stationarity requires explicitly limiting the influence of outdated data to maintain calibrated uncertainty and meaningful dynamic regret guarantees. Motivated by these insights, we propose a practical optimistic model-based reinforcement learning algorithm with adaptive data buffer mechanisms and demonstrate improved performance on continuous control benchmarks with non-stationary dynamics.
The paper introduces adaptive buffer strategies (R-OMBRL and SW-OMBRL) to mitigate stale data bias in MBRL under non-stationary dynamics.
It shows that balancing historical and recent data significantly enhances model accuracy and yields tighter dynamic regret bounds in continuous control settings.
Empirical results across simulated and real-world benchmarks validate that adaptive buffer mechanisms enable rapid recovery and sustained performance post-drift.
Model-Based Reinforcement Learning for Control under Time-Varying Dynamics: Expert Essay
Problem Overview and Motivational Context
The paper "Model-Based Reinforcement Learning for Control under Time-Varying Dynamics" (2604.02260) investigates reinforcement learning (RL) for control in dynamical systems exhibiting temporal non-stationarity, where transition dynamics evolve persistently due to drift, environmental changes, or hardware degradation. Classical model-based reinforcement learning (MBRL) frameworks, while theoretically sound and empirically effective in stationary environments, systematically underperform in such settings because they indiscriminately leverage all historical data, which induces bias in system identification and control.
The work addresses the following pivotal question: how should data and uncertainty be managed in MBRL to guarantee robust performance and theoretically justified regret when dynamics are time-varying? The paper's central thesis is that stale, outdated data must be judiciously forgotten or discounted to avoid calibrated model misestimation and poor adaptation.
Theoretical Framework and Assumptions
The authors operate within an episodic finite-horizon control context with continuous state-action spaces. The system's dynamics are modeled as an unknown, time-varying function fn∗ at each episode n, admitting structure in a common vector-valued RKHS with bounded norm. The temporal evolution is bounded by a variation budgetPN, controlling the total drift (in RKHS norm) over N episodes. A dynamic regret metric is adopted, benchmarking the learner's episode-wise performance against a sequence of optimal, per-episode policies, unachievable by static-regret frameworks in this regime.
Gaussian Process Models and the Stale Data Phenomenon
The theoretical core employs Gaussian process (GP) regression for dynamics modeling, yielding tractable closed-form posteriors for both epistemic uncertainty and mean predictions. For episodic non-stationarity, the paper rigorously analyzes the failure of classical GP-based MBRL:
Stale Data Problem: Fitting the model to all past transitions, as done in stationary settings, produces overconfident predictions and persistent model bias, since observed trajectories increasingly diverge from current system conditions.
Calibration under Drift: The standard GP-based Bayesian confidence intervals become invalid. The paper extends prior concentration inequalities, introducing a two-term error bound: classical epistemic uncertainty (scale dictated by the retained data) plus additive bias proportional to cumulative drift over the data horizon.
This is formalized in their extension of GP concentration yields (Equation (7)), which become the analytical substrate for regret guarantees.
Forgetting Mechanisms and Algorithmic Contributions
To counteract stale data, the authors introduce two practical buffer adaptation schemes:
Reset-based OMBRL (R-OMBRL): All prior data are cleared at fixed intervals (H episodes), fitting the model only to recent experience.
Sliding Window OMBRL (SW-OMBRL): The data buffer retains only the w most recent episodes for GP fitting and policy synthesis.
Both mechanisms are integrated into an optimistic MBRL framework: at each episode, the agent maximizes a sum of model-based expected return plus an intrinsic reward proportional to the epistemic uncertainty (Equation (13)). This controls both exploitation and exploration under non-stationarity.
The practical instantiation (beyond GP setting) leverages Bayesian neural networks (i.e., ensembles) as scalable drop-in replacements, introducing hyperparameters for soft resets of policy/model parameters and emphasizing adaptive tuning of the exploration weight.
The dynamic regret for R-OMBRL or SW-OMBRL with buffer horizon p is:
RN=O~Npγp3+γpp3/2PN
where γp denotes the maximum information gain for kernel k over n0 episodes.
This reveals a bias-variance-style trade-off:
Larger n1 (n2 or n3): More data per fit, lower variance/uncertainty in the model, but increased cumulative drift leads to higher bias.
Smaller n4: Less stale data, thus rapid adaptivity to changing dynamics, at the cost of higher statistical uncertainty.
Selecting n5 (reset period or window size) thus becomes crucial. The setting recovers classical sublinear regret only as n6 (stationary system) and highlights a path to sublinear regret for nontrivial variations, given appropriate parameter scaling.
Experimental Validation
Pendulum Environment (GP Dynamics)
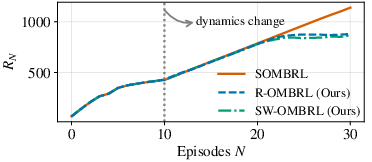
In a controlled non-stationary Pendulum scenario, both R-OMBRL and SW-OMBRL outperform a stationary buffer baseline (SOMBRL). Performance recovers rapidly following abrupt changes in dynamics, while the stationary method accrues substantial regret due to unadapted, out-of-date modeling.
Figure 1: Learning curves for the Pendulum environment with an induced change in system dynamics. Only R-OMBRL and SW-OMBRL manage to adapt and minimize regret post-change.
Continuous Control Benchmarks
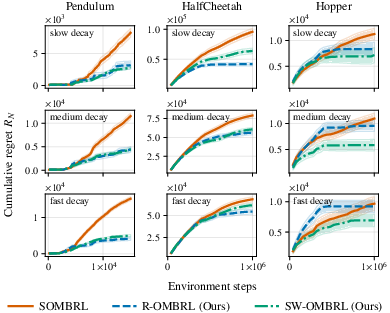
Benchmarks on higher-dimensional environments (e.g., HalfCheetah, Hopper, RC car hardware) with progressive actuator strength decay elucidate the central empirical claims:
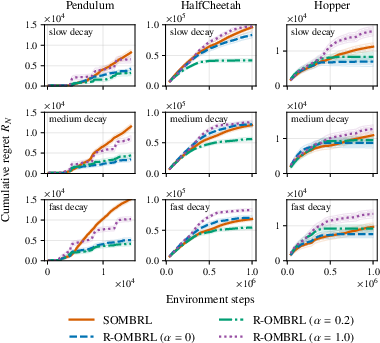
Both data buffer adaptation mechanisms robustly track optimal performance post non-stationarity onset, while stationary MBRL rapidly accumulates regret (Figure 2). This is consistent across varying rates of drift and task complexities.
Figure 2: Dynamic regret comparison over different environments and rates of decay. Buffer adaptation methods dramatically reduce regret under non-stationarity.
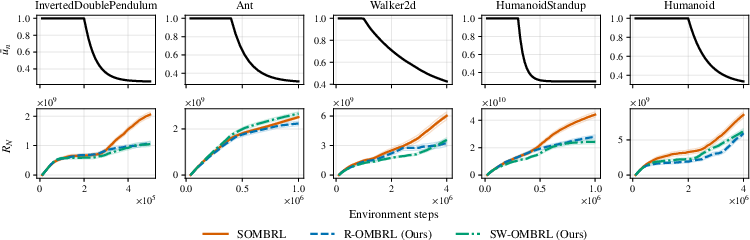
Buffer adaptation is effective across environments initially stationary, then subjected to drift (Figure 3), showcasing the method's generality and scalability.
Figure 3: Dynamic regret and environment parameter evolution in multiple MuJoCo settings. R-OMBRL and SW-OMBRL quickly adapt after non-stationarity sets in, unlike the stationary baseline.
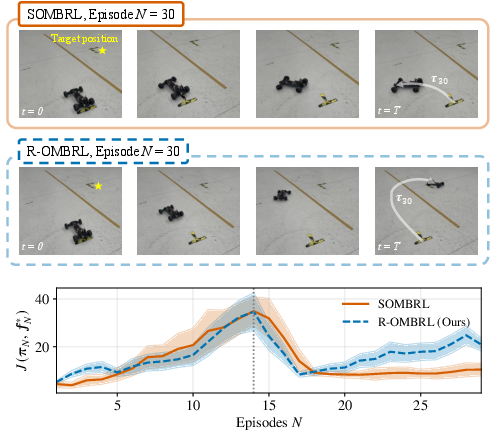
In real-world hardware, R-OMBRL successfully maintains task performance through environmental change, whereas the stationary implementation fails to adapt (Figure 4).
Figure 4: Policy rollout visualization and quantitative performance for RC car drift-to-parking task. R-OMBRL maintains robustness under actuator degradation.
Additional Insights and Ablations
An ablation on soft reset parameters (n7) reveals that moderate perturbation rates for policy and model weights after buffer resets optimally balance plasticity and stability. Excessive perturbation degrades transient adaptation.
Practical MBRL deployment: Environments with hardware degradation, wear, or systematic drift (e.g., robotics, autonomous vehicles) require dynamic buffer adaptation for credible model-based control, rather than naive stationarity assumptions.
Theoretical advancement: The dynamic regret results extend GP-based optimism bounds to genuinely non-stationary, continuous-value, nonlinear settings, providing a rigorous framework for further development.
Algorithm design: Parameter-free or adaptive mechanisms for buffer length selection (e.g., event-based resets) are open avenues, as is the integration of advanced recurrent or meta-learning approaches for "buffer adaptation policies."
Beyond episodic structure: Extending to non-episodic, continuously drifting systems and establishing minimax optimal rates for more general non-stationary models remains open.
Conclusion
This work formalizes and solves central issues in MBRL under persistent non-stationary dynamics. By providing tailored theoretical bounds, practical algorithms with validated empirical superiority, and clear perspectives on adaptation, it advances both the theory and application of RL for dynamical systems whose properties evolve through time. Dynamic buffer adaptation emerges as a necessary architectural principle for robust, long-term learning and control in realistic, temporally shifting settings.