- The paper introduces IVE, a model-agnostic method that dynamically redistributes visual attention to mitigate cognitive hallucinations in MLLMs.
- It employs trend-guided token selection using an EMA-based mechanism to distinguish and adjust between emergent and inertia tokens.
- Empirical results on benchmarks like Reefknot and MME show improved response accuracy and reduced hallucination rates across multiple models.
Inertia-aware Visual Excitation: Mitigating Cognitive Hallucination in MLLMs
Introduction
Multimodal LLMs (MLLMs) achieve significant progress in vision-language reasoning, but exhibit persistent reliability issues due to hallucinations—model outputs unsupported or contradicted by visual evidence. While existing mitigation approaches primarily address perceptual hallucinations (object presence, attributes), they fail to resolve cognitive hallucinations—fabrications in relational or compositional understanding across image regions. The paper "Attention at Rest Stays at Rest: Breaking Visual Inertia for Cognitive Hallucination Mitigation" (2604.01989) proposes Inertia-aware Visual Excitation (IVE), a training-free, inference-time intervention that modulates attention dynamics in MLLMs, directly targeting the phenomenon of "visual inertia" underlying cognitive hallucination.
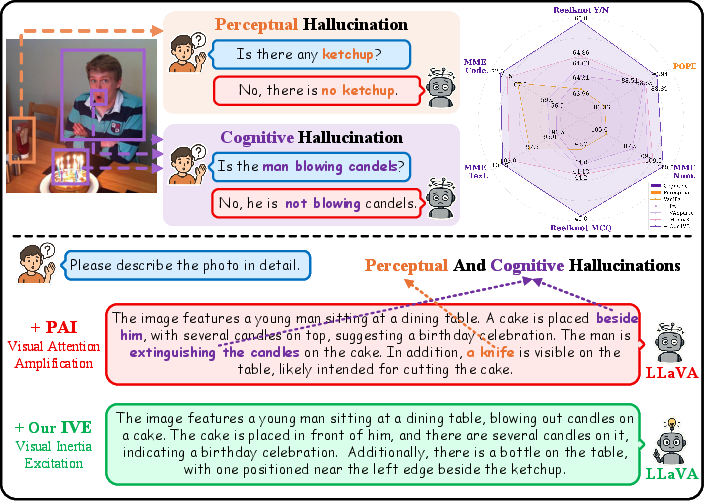
Figure 1: Overview of the distinction between perceptual and cognitive hallucinations, and demonstration that IVE suppresses both via excitation of inertial visual attention.
Cognitive Hallucination and Visual Inertia
Cognitive hallucinations are formalized as model errors in relational inference—scenarios where object recognition is correct but inter-object relationships are fabricated. This error is traced not merely to insufficient attention strength but to attention dynamics: visual attention in autoregressive decoding shows inertia, remaining fixed on initial regions rather than dynamically shifting toward relational cues critical for compositional inference. Quantitatively, "visual activeness"—the mean Wasserstein distance between attention distributions for consecutive tokens—demonstrates that attention in MLLMs commonly plateaus, regardless of the generative context.
Amplification-based mitigation (e.g., PAI) designed for perceptual hallucination exacerbates this inertia, intensifying static focus and thereby further harming performance on cognitive hallucination tasks.
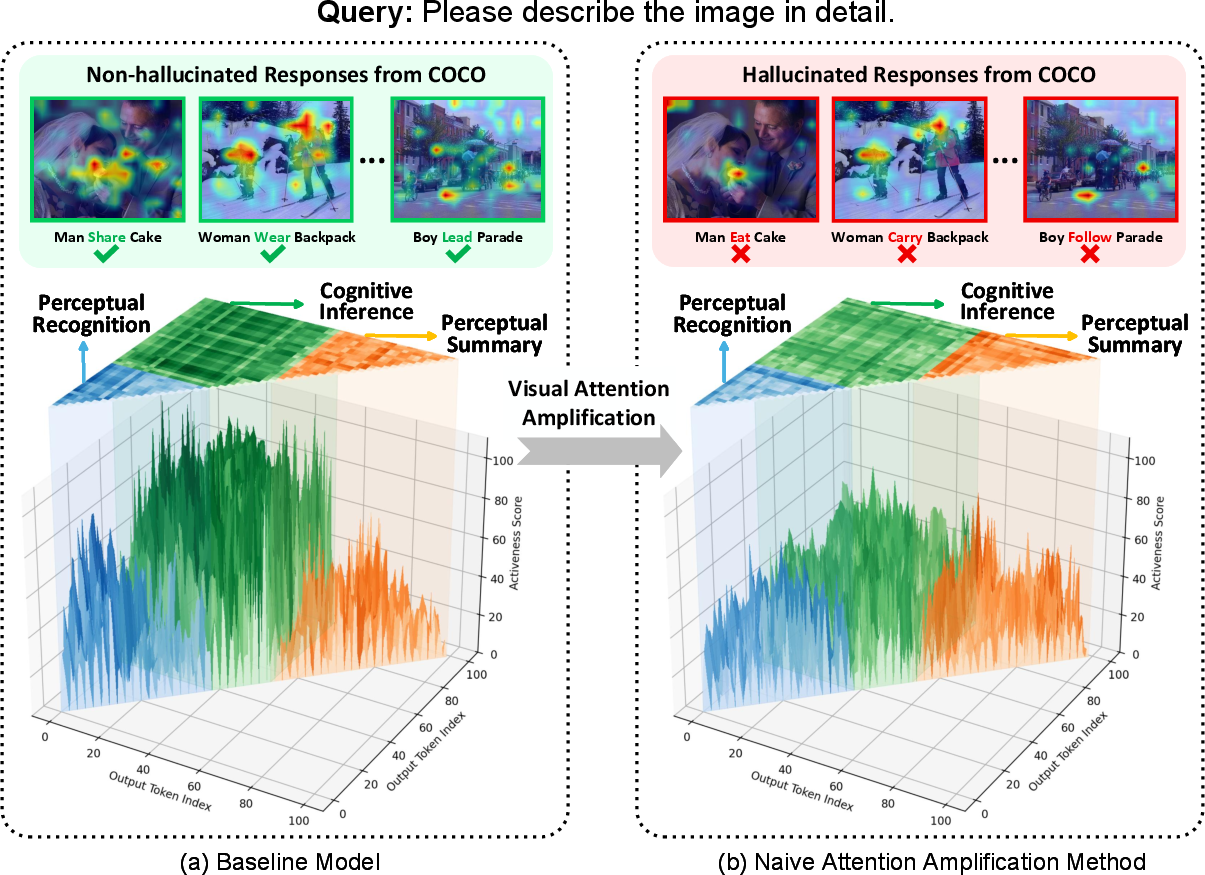
Figure 2: Naive attention amplification (PAI) restricts attention switching, decreasing visual activeness and worsening cognitive hallucinations.
Inertia-aware Visual Excitation: Methodological Framework
IVE comprises two synergistic mechanisms:
- Trend-guided Token Selection: For each decoding step, visual tokens are partitioned by their deviation from an exponential moving average (EMA) of historical attention. Emergent tokens—those obtaining significantly higher attention than their historical baseline—are dynamically emphasized; inertia tokens—persistently high in history—are identified for penalization.
- Inertia-aware Attention Penalty: For each inertia token, the cumulative persistence across prior steps determines a progressive attenuation factor. Penalized attention is precisely reallocated to emergent tokens in proportion to their relative deviation score, promoting adaptive, composition-sensitive attention redistribution.
This mechanism directly regulates attention matrices at each autoregressive decoding step, modulating attention before computation of the next-token distribution. Implementation is training-free, model-agnostic, and incurs negligible inference overhead relative to alternatives.
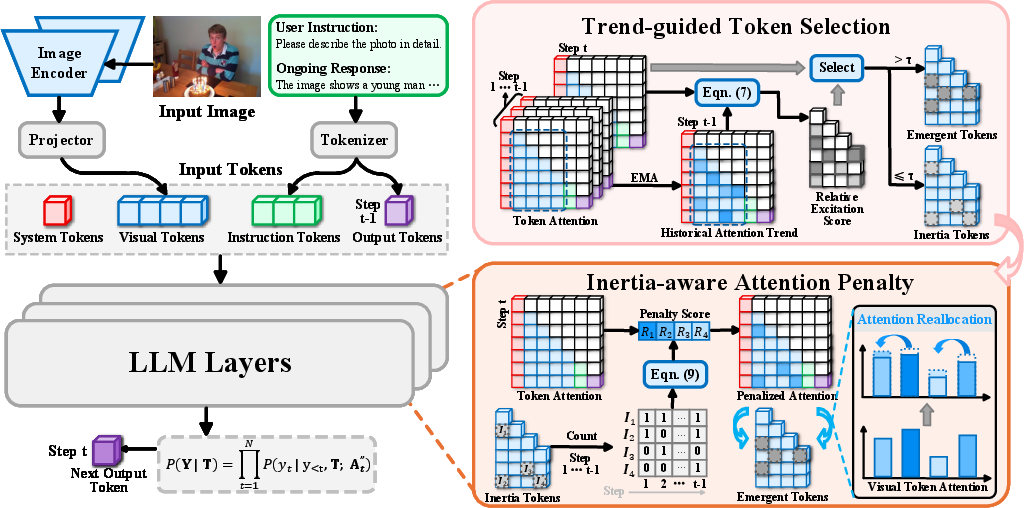
Figure 3: Schematic of IVE: autoregressive decoding with EMA-guided token categorization and adaptive, persistence-dependent penalty-reallocation for dynamic visual attention.
Empirical Results
Benchmarks and Models
IVE is evaluated on a suite of established hallucination benchmarks: Reefknot and MME (cognitive hallucination focus), POPE (perceptual hallucination), and MMBench (multidimensional evaluation). Backbone MLLMs include LLaVA-1.5, InstructBLIP, and Qwen2.5-VL-Instruct.
On Reefknot, IVE attains reductions in cognitive hallucination rates up to 1.92% absolute and response accuracy improvements up to 1.84% (Y/N format) over the next best method. On MME, IVE yields 6.5–9.5 points improvement in cognitive tasks (commonsense, numerical, code) across multiple backbones. POPE results confirm that IVE also offers strong or best gains on perceptual hallucination tests, indicating that excitation of inertial tokens generalizes beyond relational reasoning.
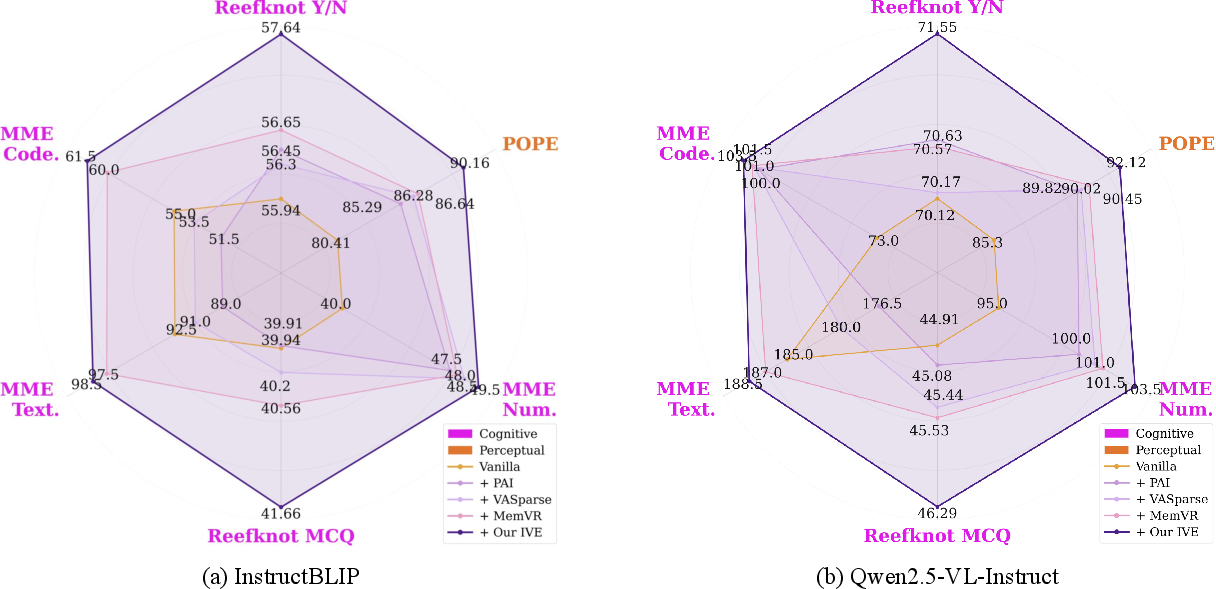
Figure 4: Radar chart demonstrating that IVE consistently dominates prior hallucination mitigation methods across all major benchmarks and models.
MMBench results show that IVE advances performance across perception, cognition, and reasoning tasks.
Visualization and Analysis
IVE consistently elevates visual activeness, verified by tokenwise attention activeness matrices: layers associated with cognitive inference exhibit heightened activeness, and hallucinated responses are characterized by lower activeness across key tokens.

Figure 5: Token-level activeness visualization; green rectangles mark dynamic layers/steps for valid responses, red rectangles signal inertial/hallucinatory generations.
Attention heatmap comparisons show that IVE enforces spatially broader and more compositionally grounded attention in challenging contexts, in contrast to naive amplification approaches.

Figure 6: Heatmap comparison—IVE vs. naive amplification—highlighting improved distribution of attention over relationally relevant regions.
Visual activeness trajectories indicate that IVE maintains higher inter-step attention switching versus PAI, supporting the hypothesis that inertia-breaking is essential for mitigating relational hallucinations.
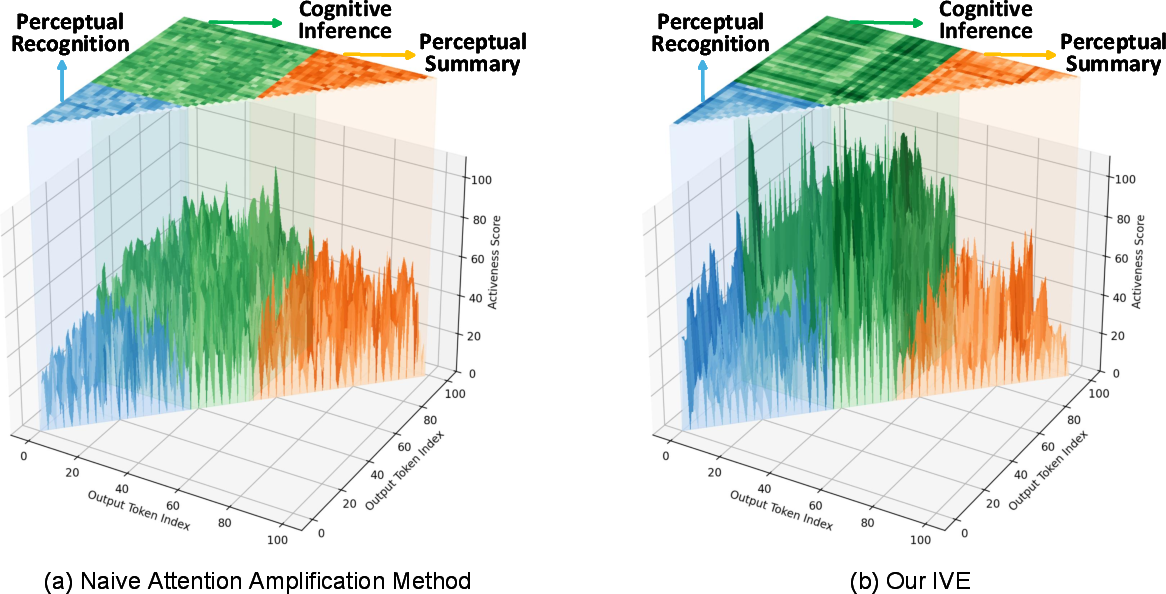
Figure 7: Visual activeness comparison—IVE retains higher activeness than naive amplification, correlating with improved cognitive hallucination mitigation.
Case studies on Reefknot, MME, POPE, and MMBench qualitatively demonstrate that IVE enhances factual alignment with visual context and suppresses relational hallucination.

Figure 8: Illustration of IVE suppressing cognitive hallucinations on Reefknot; attention correctly adapts to context and avoids unsupported inferences.
Theoretical and Practical Implications
IVE conceptualizes cognitive hallucination as a temporal failure of attention dynamics rather than static under-utilization, distinguishing it from prior mitigation protocols. The introduction of explicit, history-aware token excitation/penalization reorients the focus of inference-time interventions from global attention intensity toward adaptive modulation based on compositional needs. This reframing is directly portable to MLLMs with frozen parameters, facilitating rapid integration into deployed systems. As instruction-tuned MLLMs target compositional generalization in high-stakes domains, inference-time attention modulation strategies such as IVE represent a scalable approach for improving factuality without sacrificing model agility or incurring the cost of retraining.
Future Directions
IVE motivates several research directions:
- Integration with learning-based mitigation, optimizing both static alignment and dynamic attention responsiveness.
- Further theoretical analysis of layerwise activeness patterns and attention inertia across different architectures.
- Extension to video and multi-turn vision-language tasks, where relational reasoning dependencies may span longer temporal horizons.
- Exploration of alternative historical summarization techniques (beyond EMA) and adaptive thresholding schemes.
Conclusion
IVE establishes that cognitive hallucinations in MLLMs are fundamentally tied to visual inertia—the tendency of attention to persist in localized regions. By breaking this inertia through trend-aware excitement and penalization, IVE achieves consistent mitigation of both perceptual and cognitive hallucinations across model families and benchmark suites. The findings underscore the necessity of dynamic, history-conditioned attention reallocation for robust compositional reasoning, and position inertia modulation as a foundational principle for future hallucination mitigation in vision-LLMs.