- The paper introduces a collaborative pipeline integrating LLMs, compiler diagnostics, and code analysis to automatically detect and fix implicit inconsistencies in patch porting.
- Methodology employs hierarchical text similarity and usage snippet comparisons to resolve complex Type-1 and Type-2 inconsistencies across divergent software codebases.
- Empirical evaluations on Vim-Neovim and Linux backports show significant improvements over baselines, enhancing patch reliability and user trust.
Mitigating Implicit Inconsistencies in Patch Porting: A Comprehensive Analysis
Patch porting across software forks and branches is crucial for maintenance, especially for propagating critical vulnerability fixes in ecosystems such as Linux and widely-forked applications like Vim. The challenge addressed in "Mitigating Implicit Inconsistencies in Patch Porting" (2604.01680) is the automation of patch refinement with a focus on implicit inconsistencies—those requiring non-local, global mapping knowledge of codebase divergences, which cannot be resolved by examining the localized context where the patch applies.
Explicit inconsistencies—such as variable renamings visible in patch hunks—are tractable for current automated porting systems leveraging syntactic or semantic proxies. However, implicit inconsistencies arise when identifiers (functions, macros, constants) are referenced in the source patch but either (1) their definition has changed in the target codebase or (2) they have no direct counterpart in the target codebase, requiring mappings that can induce structural changes.
The paper introduces a collaborative solution leveraging an LLM, a compiler, and code analysis utilities to detect, diagnose, and automatically fix these implicit inconsistencies. This multilayered methodology aligns with the empirical observation that the highest overhead and contributor specialization in patch porting tasks arises from such global mapping challenges.

Figure 1: An example of patch porting with implicit inconsistencies.
Taxonomy of Implicit Inconsistencies
The authors classify implicit inconsistencies into two categories:
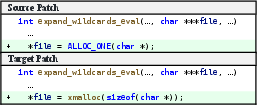
The authors demonstrate that resolving Type-2 inconsistencies can require inferring non-trivial mappings, such as recognizing that the macro ALLOC_ONE() is reified as a call to a differently named memory allocation routine (xmalloc) in the target codebase, rather than a direct textual or type-based mapping.

Figure 3: A function pair showing ALLOC_ONE mapping.
Methodology: The Collaborative Patch Refinement Pipeline
The refinement pipeline begins by compiling the patched target codebase and parsing compiler diagnostics to detect unresolved inconsistencies. The system then iteratively invokes two strategies depending on the diagnostic results:
- Fixes for Type-1 (existing identifier, changed definition): The LLM receives both the problematic function and structured compiler diagnostics, which explicate the mismatch and, when possible, relevant snippets from the target codebase. This aids the LLM in generating accurate patches with minimal hallucination.

Figure 4: Prompt template for fixing by compiler diagnostics.
- Fixes for Type-2 (non-existent identifier): The system retrieves snippet pairs from both codebases where the problematic identifier is used, performing hierarchical (name, signature, and body-based) text similarity to select candidate pairs. The LLM is then prompted with these usage pairs as demonstrations, training it to perform structural transformations by example.
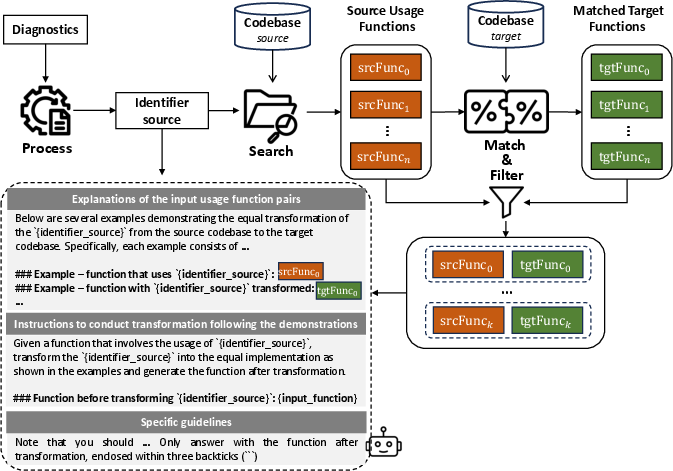
Figure 5: Pipeline of fixing non-existent identifiers through matched pairs of usage code snippets.
As the pipeline proceeds, it re-compiles the code after each fix, refreshing diagnostics and iterating until success or iteration exhaustion. Candidate patches are filtered using conservative heuristics to suppress over-aggressive changes—a critical aspect for industrial trust.
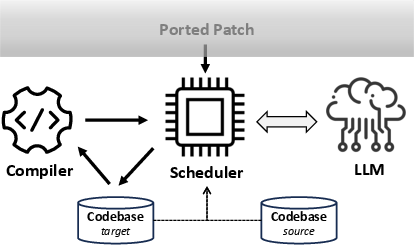
Figure 6: Overview of.
Experimental Results
Empirical Evaluation
The methodology is empirically evaluated in two high-impact real-world settings:
- Cross-fork: Patches from Vim to Neovim, with substantial codebase divergence.
- Cross-branch: Backports from Linux mainline to older branches, generally less divergent.
The authors curated datasets consisting strictly of ported patches exhibiting implicit inconsistencies. They measured both patch-level and inconsistency-level success rates, comparing their pipeline against:
- Naive compiler suggestion (CS)
- Compiler suggestion with definition matching (CS+)
- Llama3.1-70B LLM baseline prompted using only compiler diagnostics
Key numerical results: The proposed system successfully resolves 81.3% of Vim-to-Neovim patches and 72.7% of Linux backports, more than doubling the patch-level resolution rate of the best-performing LLM baseline. At the inconsistency level, >90% of both Type-1 and Type-2 inconsistencies are resolved in the Vim-Neovim dataset, with CS and CS+ trailing dramatically (<15%).
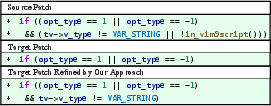
Figure 7: An example of failed mitigation.
Generalizability Across LLMs
The pipeline's modularity allows swapping in different LLMs. Ablations with GPT-4o and DeepSeek-v3 showed further gains, with the best result at 85.9% patch-level fix rate, and all strong models sharing a substantial set of residual failures. These failures predominantly occurred when no valid usage snippet pairs could be found or when the LLM failed to generalize from complex examples.
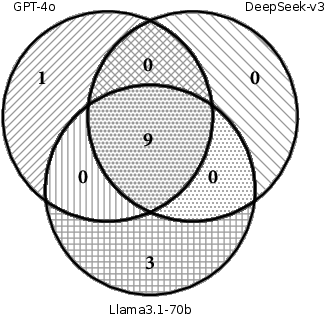
Figure 8: Venn diagram of failure cases of different LLMs.
User Study
A controlled user study with industry engineers examined practical effectiveness. The experimental group using the tool completed tasks 49.2% faster and achieved 21/30 correct patches, compared to 14/30 in the compiler-diagnostics-only control group. Notably, global mapping—retrieval and reasoning over usage pairs—was the major bottleneck ameliorated by the system. Participants reported high trust and transparency attributable to the evidence-driven, verifiable transformation logic, rather than black-box LLM inference.
Implications, Limitations, and Future Directions
The study demonstrates that global codebase mapping knowledge is the principal impediment to reliable patch porting automation. The evidence-driven pipeline outperforms naive or solely LLM-driven approaches, especially in the presence of complex structural divergences or insufficient pretraining data. However, ultimate effectiveness is bound by the availability and retrievability of high-quality usage pairs—a limitation in sparse or uniquely divergent code regions.
The insights reveal that developers strongly favor tools that provide verifiable, inspectable rationales for port mappings—usage snippet pairs, diagnostics, and explicit constraints for each code modification. This requirement of explainability is critical for production integration and risk management.
Controlling LLM overreach and hallucination is essential; the iterative, validation-centric design mitigates potential risks by only accepting changes with clear, justifiable provenance.
Future work should focus on supporting additional programming languages, leveraging richer contexts (e.g., evolutionary code history), and integrating behavioral testing for automated fix validation. Broader dataset curation will also facilitate stronger claims about the approach’s generalizability.
Conclusion
The proposed approach marks a substantive advance in automated patch refinement by attacking the implicit inconsistency problem through collaboration between LLMs, compiler diagnostics, and codebase analysis. By systematically surfacing and leveraging explicit mapping evidence, the method achieves substantial gains in reliability and human trust. As the complexity and size of software ecosystems grow, such evidence-driven, explainable, and conservative automation strategies will be integral for secure and efficient maintenance.