- The paper presents a novel benchmark that decouples navigation from question-asking, enabling precise evaluation of interactive reasoning.
- It introduces QAsk-Nav with two distinct protocols and a large-scale dataset of around 28K samples for structured, uncertainty-aware dialogue.
- Light-CoNav, a lightweight end-to-end VLM model, achieves higher success rates and efficiency, outperforming larger modular baselines.
A Reproducible Benchmark for Collaborative Instance Object Navigation: QAsk-Nav and Light-CoNav
Introduction and Motivation
The paper addresses a significant gap in embodied AI, specifically in Collaborative Instance Object Navigation (CoIN), where the agent must find a user-specified object instance in complex environments using egocentric vision and interactively resolve ambiguities through natural language dialogue with a human. Previous benchmarks entangled navigation and collaborative reasoning, lacked reproducibility, and suffered from poor annotation quality, thereby impeding reliable evaluation and rapid prototyping of interactive agents.
To overcome these limitations, the authors propose QAsk-Nav, a reproducible, modular benchmark that, for the first time, separates navigation and question-asking evaluation protocols, and introduce a new large-scale dataset, as well as Light-CoNav—a lightweight, unified model for collaborative navigation reasoning.
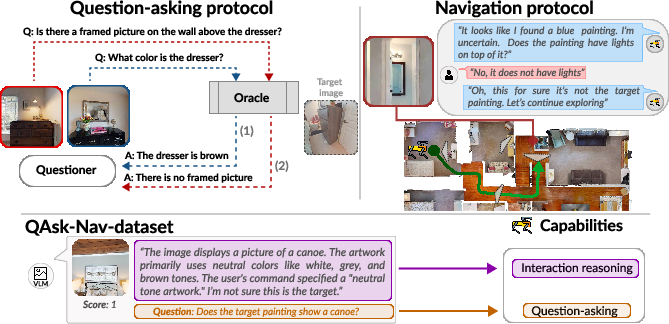
Figure 1: QAsk-Nav introduces two distinct protocols for question asking (top-left) and for navigation (top-right), supported by a novel dataset with structured reasoning, and question annotations (bottom).
QAsk-Nav Benchmark: Protocols and Dataset
Disentangled Evaluation Protocols
QAsk-Nav introduces two independent evaluation protocols:
- Question-Asking Protocol: Isolates the agent's ability to reason about ambiguity and ask clarifying questions without running full navigation episodes. Inspired by RL and dialog games, it provides the agent with a target description and several distractor images, requiring the agent to decide whether each image matches the description, ask clarifying questions, or make a decision.
- Navigation Protocol: Builds upon improved navigation episode design, featuring high-quality, diverse task descriptions and distractor-rich real-world 3D scenes. Task descriptions are enhanced using a strong vision-LLM, and oracle responses are provided by advanced VLMs, improving both precision and realism.
Generating Realistic Distractors and Task Descriptions
Distractor synthesis employs text-guided image editing to create fine-grained variants that are visually close to the target, avoiding the naivety of sampling only from navigation episodes.



Figure 2: Examples from QAsk-Nav. Original instance and two distractors generated by editing salient object attributes.
The dataset includes six hierarchical levels of task descriptions—from brief category labels to rich, multi-attribute narratives, enabling systematic analysis of language grounding and question-asking under varying ambiguity levels.
Dataset Scale and Structure
The open-source QAsk-Nav-dataset comprises ∼28,000 quality-checked reasoning and question-asking traces, split into train, validation (seen/synonyms), and validation (unseen) sets. Each sample is a tuple (D,O,R,S,Q,C) capturing description, visual input, reasoning trace, uncertainty score, question (if applicable), and dialog context.

Figure 3: Two QAsk-Nav dataset samples: one with an unambiguous match, the other showing uncertainty and context-sensitive reasoning and questioning.
The dataset is constructed by mixing LLM- and VLM-generated interactions, aggressive attribute perturbations, and manual curation, supporting robust training of interaction reasoning policies.
Model: Light-CoNav
Light-CoNav is a single-stage, end-to-end fine-tuned VLM (Qwen2.5-VL-7B-Instruct backbone) designed to replace complex modular pipelines typified by CoIN methods like AIUTA. Its design decouples exploration/navigation policy from human-agent collaboration, focusing parameter capacity on uncertainty-aware reasoning and interactive question generation.
Operationally, an external navigation policy triggers Light-CoNav whenever a candidate instance is encountered. Light-CoNav receives the initial instruction, visual input, and dialog history, and infers—via a joint reasoning/questioning prompt—a rationale, a score in {0,1,2} representing certainty, and a potential clarification question. This tight integration with modular navigation policies enables flexibility and interoperability.
Training follows a two-stage recipe: initial supervised fine-tuning on reasoning trace and uncertainty score prediction, then on data incorporating question generation and context-aware dialog grounding.
Empirical Analysis
Question-Asking Results
QAsk-Nav's disentangled question-asking evaluation protocol enables precise measurement of reasoning and information-seeking skills. Light-CoNav achieves a success rate (SR) of 0.68 on detail-rich descriptions, outperforming both the much larger modular AIUTA and the base Qwen2.5-VL-7B backbone. It asks notably fewer questions and completes more episodes without error (high finish rate), yet is 3× smaller and 70× faster than modular AIUTA. Light-CoNav even surpasses Qwen3-VL-30B (over 4× more parameters) on navigation-oriented resource constraints.
Increasing task description specificity monotonically improves performance, showing that Light-CoNav leverages linguistic information for improved visual-textual grounding—capabilities not matched by larger, but not fine-tuned, VLMs.

Figure 4: Illustration of QAsk-Nav episode: agent sequentially reasons, asks, and updates beliefs, culminating in a correct or clarified identification.
Human-in-the-loop evaluation confirms the validity of VLM-based oracles, showing near-identical success and finish rates, and significantly reduced annotation and response errors.
Navigation Results
On complex real-scene navigation tasks, Light-CoNav consistently outperforms all baselines in both seen and unseen target splits, suggesting robust generalization and effective ambiguity resolution. Notably, improvements are largest in the Val Unseen condition—critical for deployment in open-world settings—where Light-CoNav yields a success rate of 9.63 vs. 7.83 for AIUTA, and much lower for all other modular or end-to-end baselines.
The replacement of poor/hallucinated task descriptions in prior datasets with concise, high-fidelity ones contributes ∼30%-50% relative SR improvement for both Light-CoNav and AIUTA, demonstrating the sensitivity of navigation models to the quality of linguistic guidance.
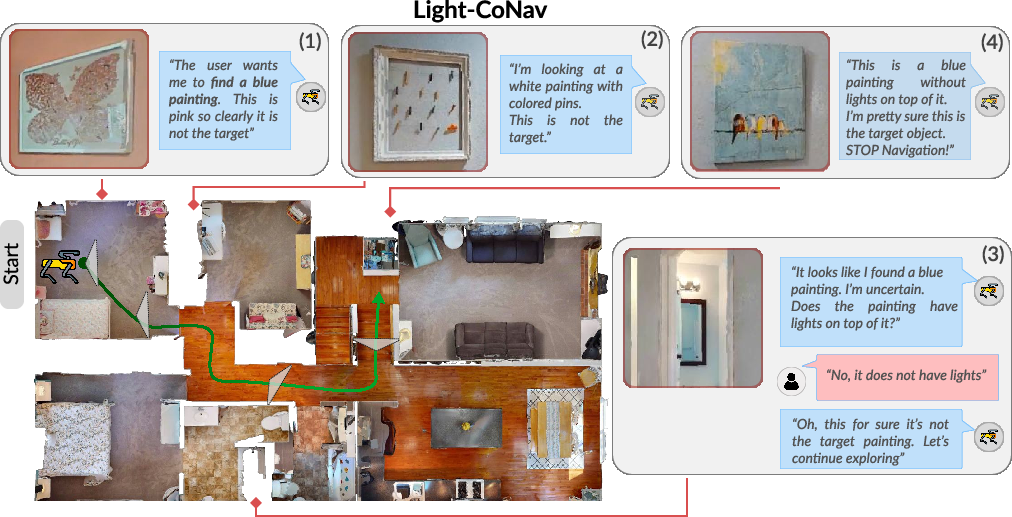
Figure 5: Light-CoNav navigation trajectory: accurate discrimination between distractors, strategic questioning to resolve ambiguous “mirror vs. blue painting”, culminating in correct target identification.
Data and Evaluation Ecosystem
Dataset analysis shows balanced category coverage and a realistic distribution of scores/questions, particularly in the training split, ensuring models learn not only matching/detection but also appropriate uncertainty estimation and dialog management.
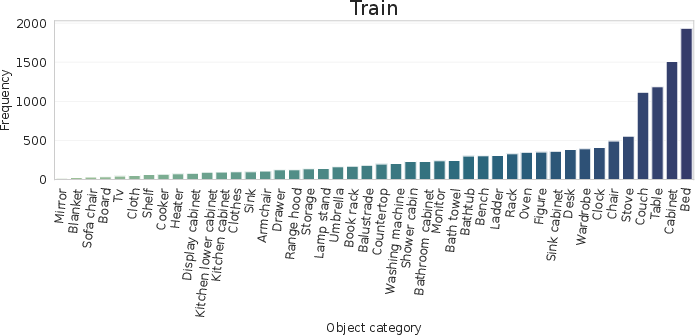
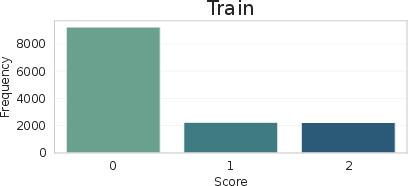
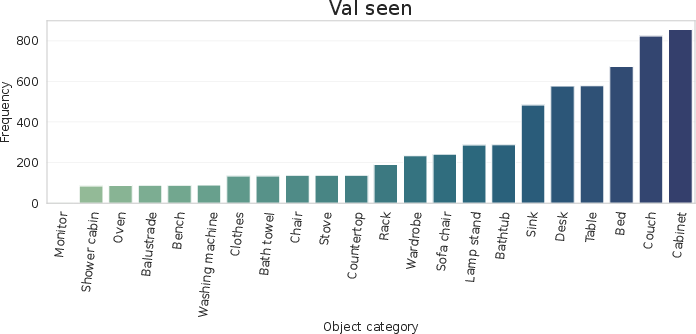
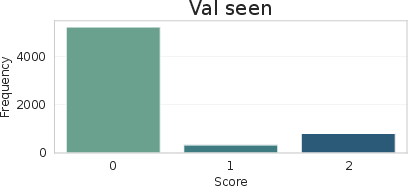
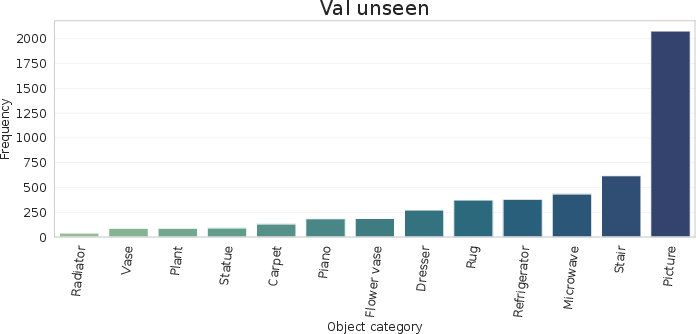
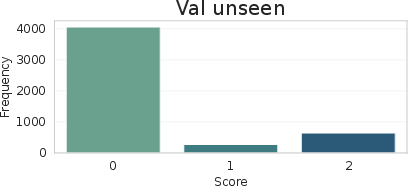
Figure 6: Distribution of categories and scores in QAsk-Nav-dataset, demonstrating coverage and emphasis on meaningful ambiguity.
Theoretical and Practical Implications
The explicit decoupling of navigation and collaborative interaction evaluation enables tractable, rigorous benchmarking and enables researchers to isolate reasoning and question-asking capabilities from physical exploration and control policies. This modularity facilitates analysis of learning dynamics, ablation studies on uncertainty thresholds, dialog policy adaptation, and rapid iteration on new architectures or data regimes.
Practically, Light-CoNav demonstrates that collaborative interaction-reasoning is possible with small, efficient architectures, challenging assumptions that complex or large modular VLM/LLM stacks are required. The reduction in model size and inference latency is crucial for resource-constrained, real-time embodied agents.
The methodology for dataset construction—incorporating aggressive and realistic distractor generation, multi-level linguistic annotation, and high-quality human/LLM curation—sets a new standard for reproducibility and transferability in embodied AI.
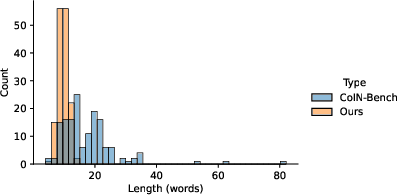
Figure 7: Distribution of description lengths; QAsk-Nav descriptions are shorter, more consistent, and more precise compared to CoIN-Bench.
Future Directions
- Explicit Uncertainty Calibration: Investigate integrating calibrated probabilistic uncertainty estimates with dialog management to further reduce unnecessary questioning, especially in high-noise or partial-observation conditions.
- Data-Efficient Training: Systematic studies of how much explicit reasoning supervision is necessary to attain robust question-asking behavior and the contribution of different question/answer context regimes.
- Scaling vs. Specialization: Analyze the effect of increasing backbone size and hybrid training with synthetic and human-in-the-loop data on the trade-off between interpretability, efficiency, and real-world performance.
- End-user Customization: Enable fine-tuning of question-asking strategies for user-adapted or task-specific behavior, e.g., minimizing dialog for expert users or maximizing clarifying interactions for non-experts.
Conclusion
QAsk-Nav establishes the first reproducible, modular benchmark and dataset for Collaborative Instance Object Navigation, enabling rigorous, independent evaluation of interaction reasoning and navigation. The joint introduction of Light-CoNav demonstrates that strong collaborative behavior is possible with lightweight, monolithic architectures, with substantial efficiency and performance gains over modular pipelines. The benchmark enables deeper research into collaborative embodied AI, supporting studies in uncertainty quantification, dialog policy learning, and efficient real-world deployment.
References:
- Full citation and dataset code: (2604.00265)