- The paper shows that neural collapse occurs when the mean feature norm reaches a specific threshold, serving as a reliable indicator of representational transition.
- It systematically examines how depth, activation, weight decay, and width affect collapse speed, revealing non-monotonic and architecture–dataset interactions.
- Empirical results from MNIST and CIFAR-10 demonstrate that while collapse timing is adjustable via hyperparameters, the threshold invariance remains robust.
Neural Collapse Dynamics: Structural Regularities and Feature Norm Thresholds
Summary and Motivation
"Neural Collapse Dynamics: Depth, Activation, Regularisation, and Feature Norm Threshold" (2604.00230) systematically investigates the temporal dynamics underlying neural collapse (NC)—the convergence of penultimate-layer features to a simplex equiangular tight frame—across varying architectures, activations, regularisation regimes, and widths. While prior research characterizes the equilibrium geometry and optimality of NC in deep networks, this work addresses the open question of what governs the timing and rate of collapse onset in practical training scenarios. A central empirical finding is that NC consistently occurs as the mean feature norm (∥h∥) descends to a sharply defined, model–dataset-specific threshold, regardless of training protocol or hyperparameter settings. This threshold proves robust and predictive, offering an actionable marker for impending representational reorganization.
Empirical Framework and Key Metrics
The analysis utilizes MNIST and CIFAR-10 as representative datasets, with architectures spanning multi-layer perceptrons (MLP) of variable depth and width, and ResNet-20. All models employ two-phase training: (1) cross-entropy to reach high accuracy, followed by (2) mean squared error (MSE) for driving collapse. The study focuses on four NC metrics: NC1 (within- to between-class scatter ratio), NC2 (class mean angle regularity), NC3 (classifier–class mean alignment), and the mean feature norm (hˉ), which serves as the critical progress variable.
Collapse Dynamics and Feature Norm Compression
The onset of NC is tightly linked to feature norm dynamics. For the MNIST MLP-5 baseline, feature norm compresses 25× across two-phase training, with collapse marked by a stable threshold hˉ≈1.06.
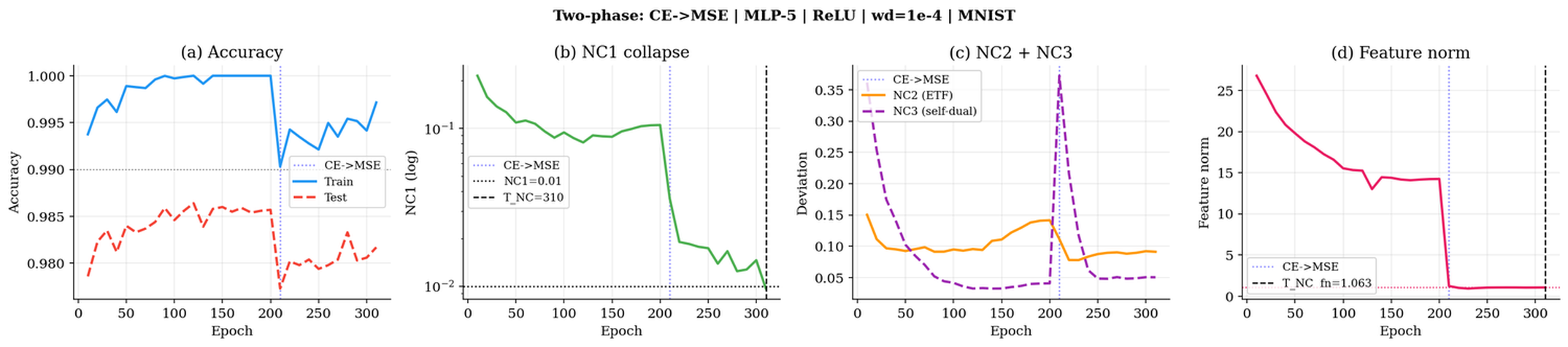
Figure 1: MNIST baseline dynamics; NC1 collapses at epoch 310, accompanied by 25× feature norm compression.
ResNet-20 on CIFAR-10 collapses at a higher threshold (hˉ=1.52), demonstrating architecture–dataset specificity in equilibrium feature geometry.
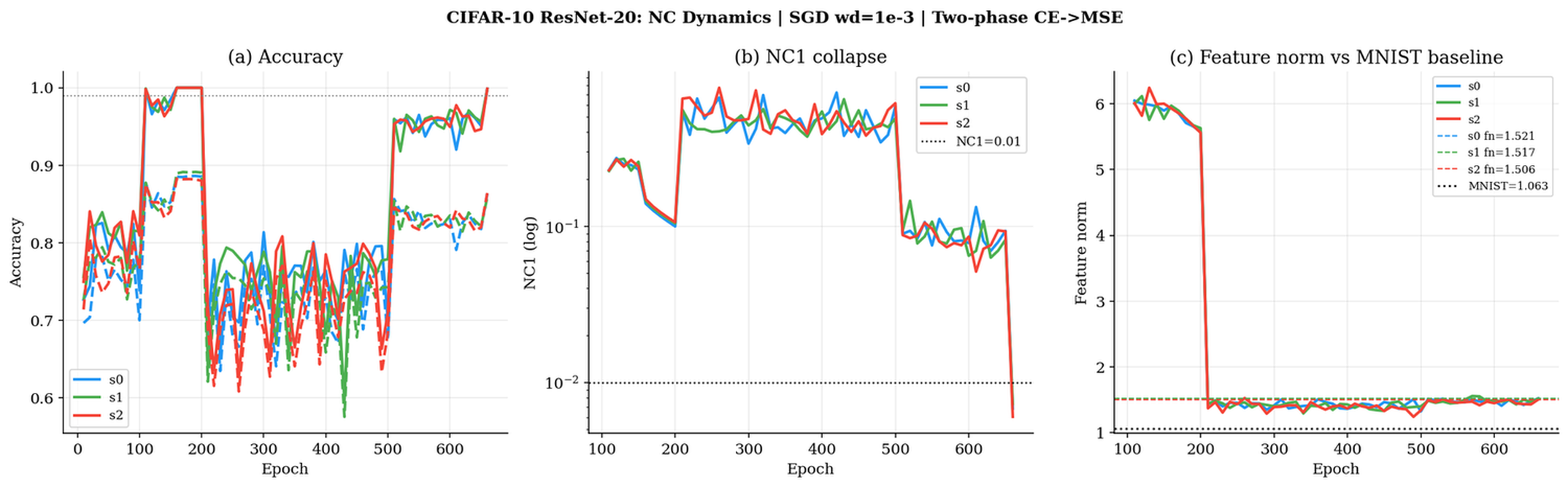
Figure 2: CIFAR-10 ResNet-20 dynamics; collapse at epoch 660 with thresholded feature norm substantially above MNIST MLP values.
Depth, Activation, Width, and Regularisation Effects
The paper rigorously decomposes effects along several axes:
- Depth: Collapse speed is non-monotonic; intermediate depth (MLP-3) is fastest, deeper models are slower, but all attain the same threshold.
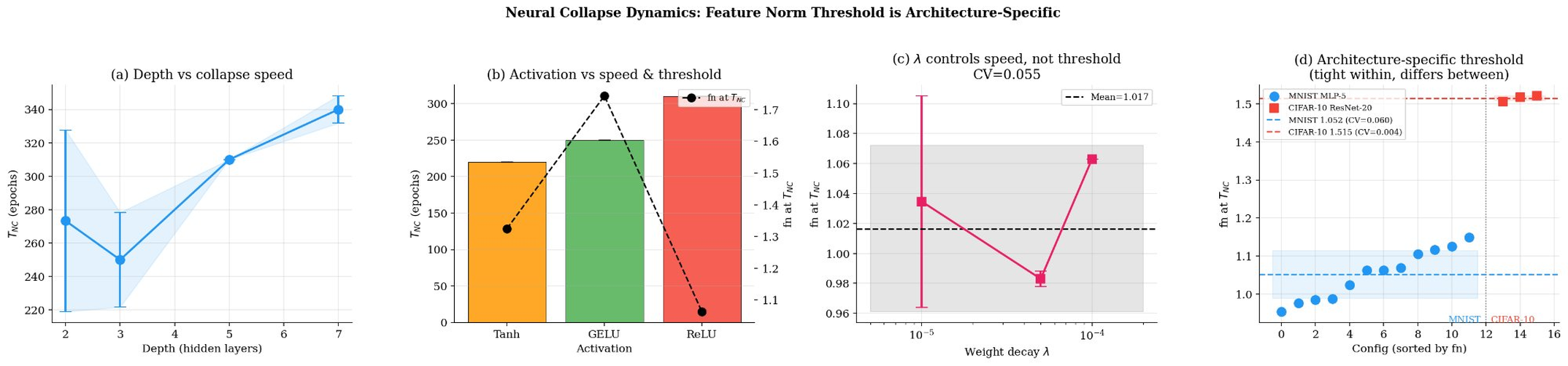
Figure 3: Depth effect; intermediate depth accelerates collapse but does not alter threshold.
- Activation: Both collapse speed and equilibrium threshold are determined by activation. ReLU yields lower thresholds, GELU is higher and more variable, Tanh is intermediate.
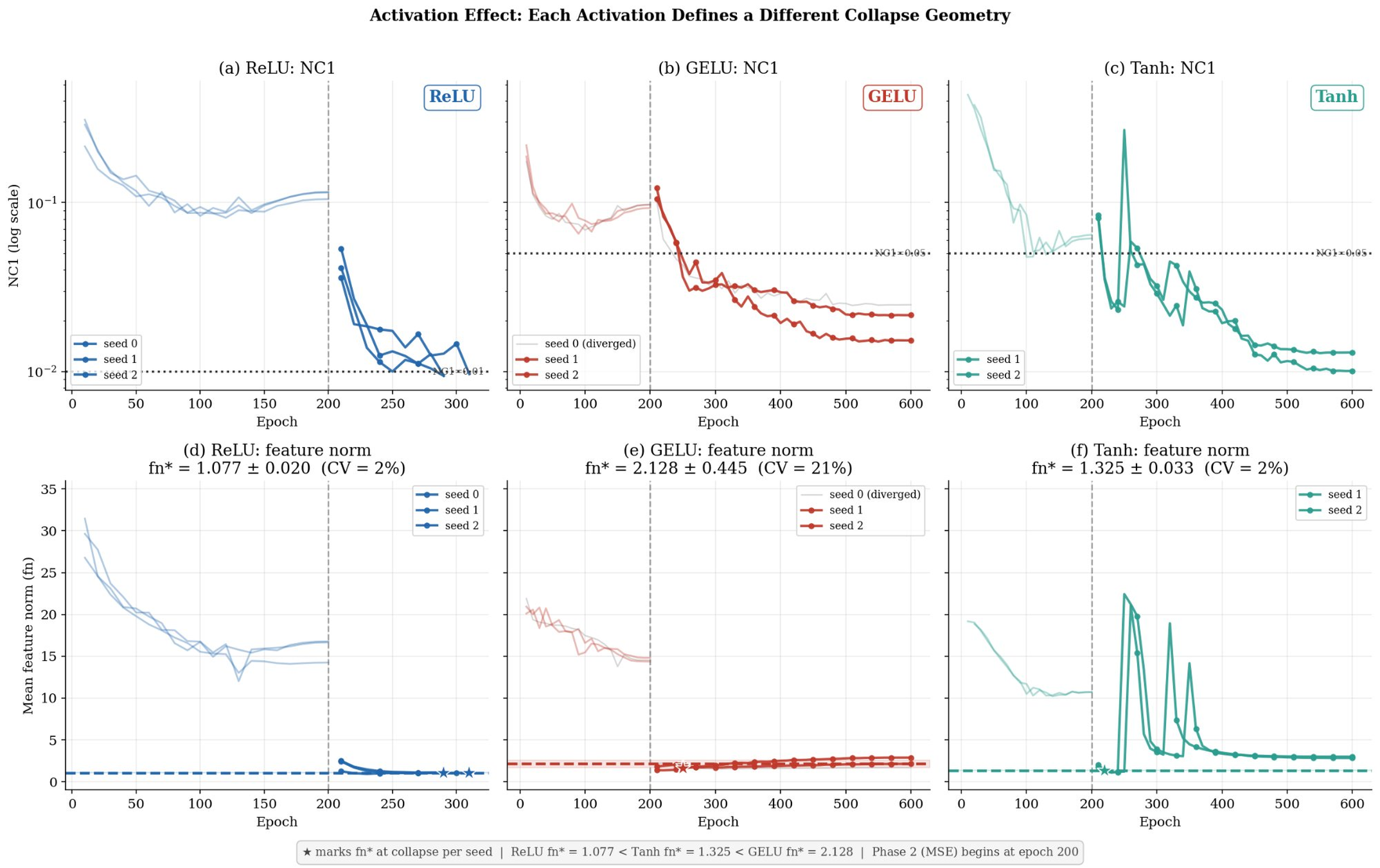
Figure 4: Activation functions jointly determine collapse speed and feature norm threshold.
- Weight Decay: There is a Goldilocks regime; too little slows collapse, optimal values accelerate, excessive weight decay prevents collapse entirely. Yet the threshold is invariant over a 10× range of λ among successful regimes.
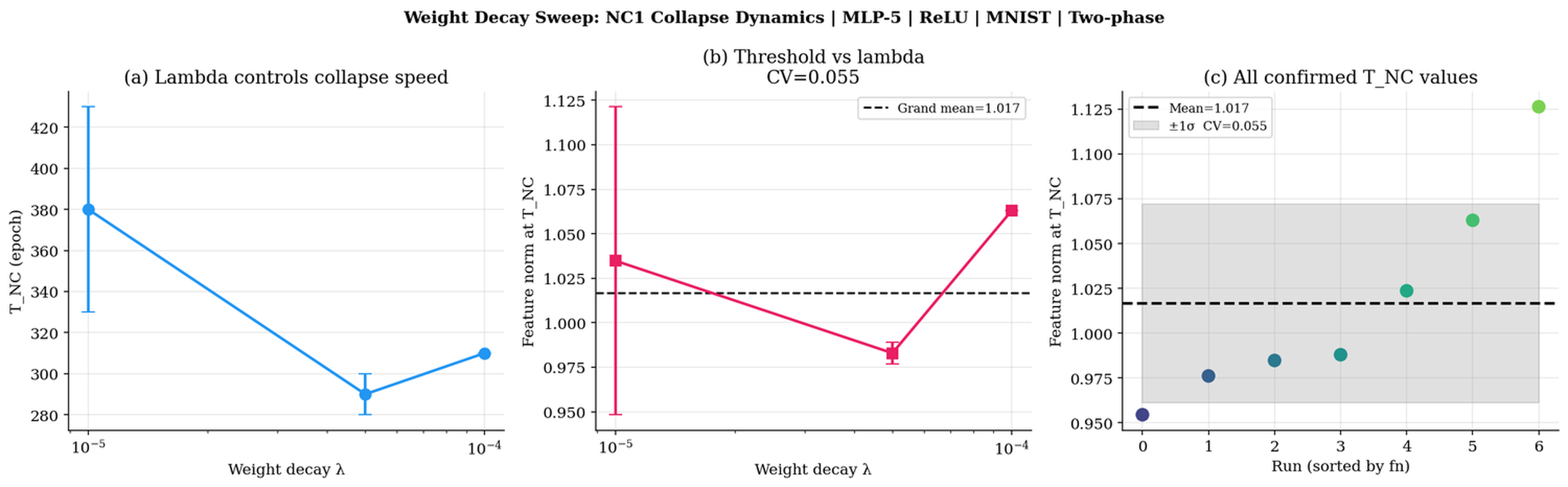
Figure 5: Weight decay sweep; TNC shifts by 90 epochs while threshold clustering remains tight.
- Width: Width monotonically accelerates collapse but shifts the threshold by at most 13%, marking a decoupling of representational and convergence dynamics.
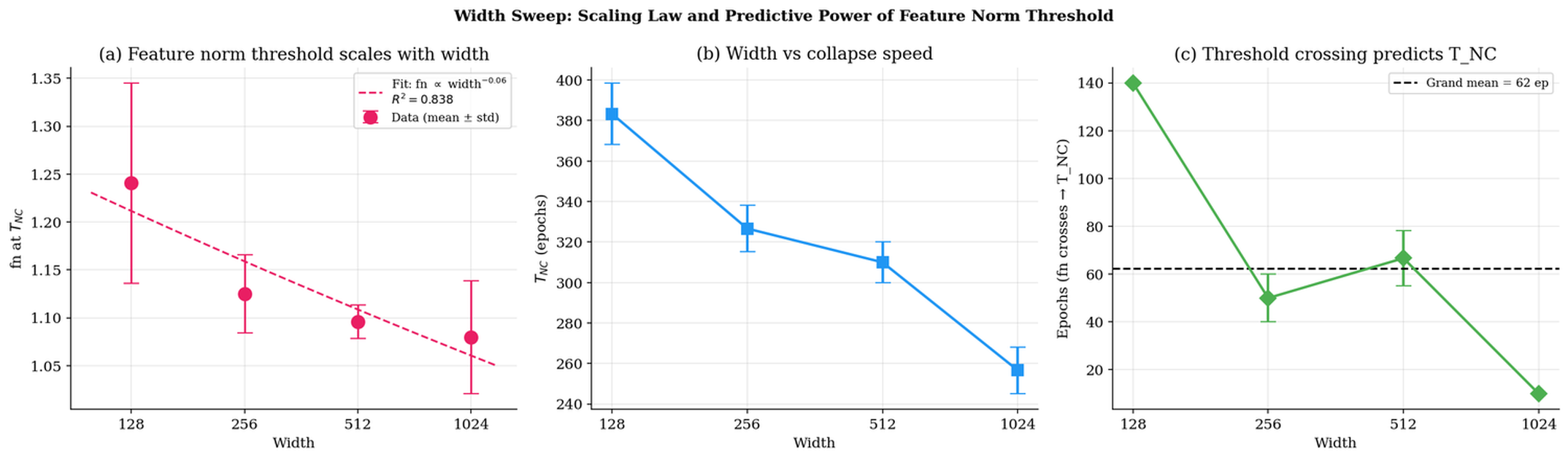
Figure 6: Width sweep; collapse speed improves but threshold norm remains nearly invariant.
A summary figure consolidates these findings, showing that collapse timing responds to architectural and hyperparameter manipulations, but threshold value is highly concentrated within each (model, dataset) pair.
Figure 7: Comprehensive summary of NC dynamics across depth, activation, weight decay, and width.
Architecture × Dataset Interaction
Crucially, completing the grid of ResNet-20 and MLP-5 across MNIST and CIFAR-10 reveals strongly non-additive interactions: the architecture effect (+458% on MNIST, only +68% on CIFAR-10) and dataset effect (up to -74%) are not separable and do not combine additively or multiplicatively.
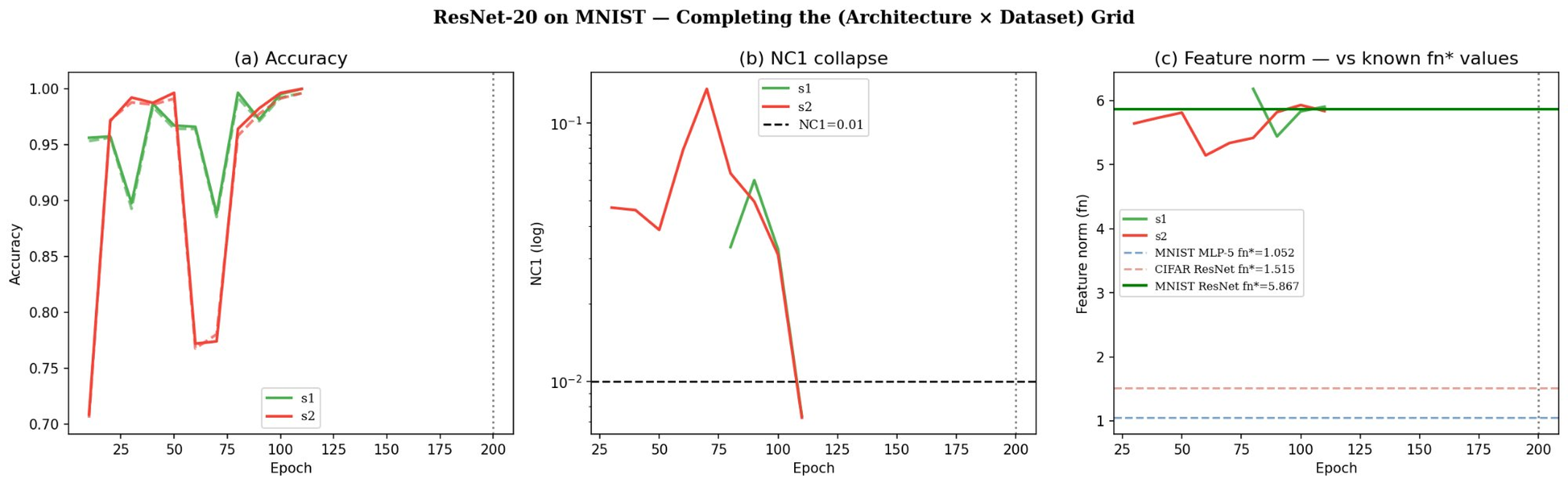
Figure 8: ResNet-20 on MNIST exhibits an extreme threshold (5.867), demonstrating strong architecture–dataset interaction.
Predictive Value and Gradient Flow Attractor
Monitoring feature norm crossing below the threshold provides a mean predictive lead of 62 epochs to collapse, with a mean absolute error of 24 epochs. Intervention experiments (rescaling feature norm by 0.3× or hˉ0) show rapid convergence back to the same threshold, confirming it as a stable attractor under gradient flow, not a causal trigger.
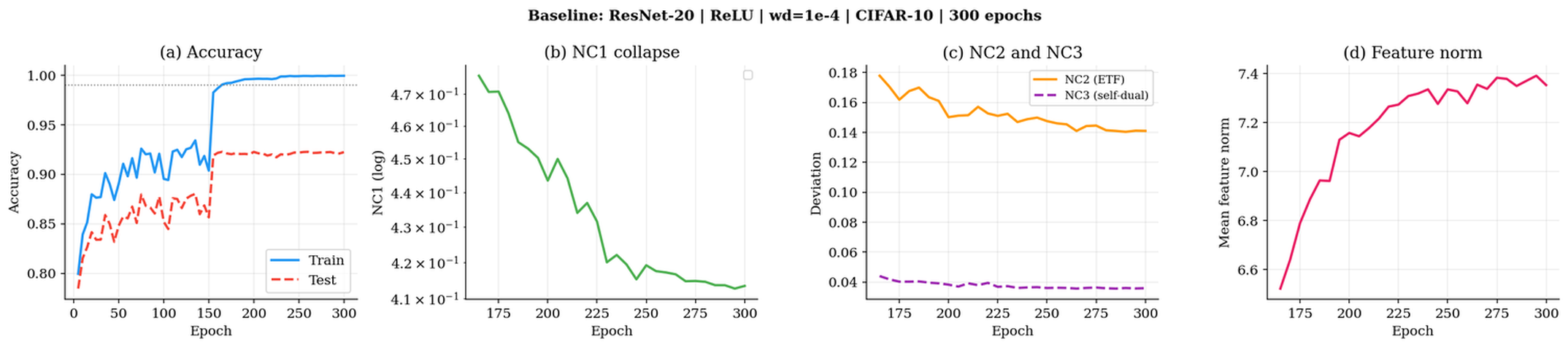
Figure 9: Protocol validation shows CE-only training cannot induce collapse; feature norm dynamics underpin robust detection.
Theoretical Implications and Unified Dynamics
These empirical signatures—the norm threshold invariance, collapse prediction, and non-monotonic parameter effects—unify neural collapse with grokking (delayed generalization phase in algorithmic tasks), where norm thresholds similarly predict representational transitions. The findings indicate that delayed phase changes in deep networks—be it NC or grokking—are governed by norm dynamics specific to the architecture–dataset pair, rather than optimization per se.
Limitations
Dataset diversity is limited and small-sample caveats apply (notably for MLP-5/CIFAR-10), but effect sizes are large and consistent, making qualitative reversal unlikely. The width scaling regression is underpowered and should be interpreted as an upper bound.
Practical and Theoretical Implications
Monitoring feature norm offers a reliable early-warning diagnostic for NC onset. The results highlight principled control levers (weight decay, width, depth) for collapse timing. The paradigm reframes NC theory from equilibrium geometry toward dynamics and thresholds, motivating further investigation into the mechanism—positive homogeneity, accumulated implicit regularization, BatchNorm-induced norm pinning, and gradient flow structure.
Conclusion
The work establishes that mean feature norm at collapse is a reproducible, highly concentrated structural property, specific to (model, dataset) pairs and predictive of NC onset. The collapse threshold is invariant under extensive hyperparameter variation and reveals a strong architecture–dataset interaction. Collapse timing can be controlled, but not the threshold value, except by jointly changing architecture or dataset. These structural regularities align closely with grokking dynamics, suggesting norm-threshold-driven delayed phase transitions are a general organizing principle in deep learning representation theory.