- The paper introduces a dual-system architecture that decouples intent and action via a differentiable latent bottleneck for robust VLA performance.
- The paper demonstrates superior simulation and real-world results, achieving up to 70.2% success on pick-and-place tasks and high few-shot efficiency.
- The paper leverages human demonstration data and systematic ablations to validate scalable, interpretable latent world modeling within embodied AI.
DIAL: Decoupling Intent and Action via Latent World Modeling for End-to-End VLA
Introduction
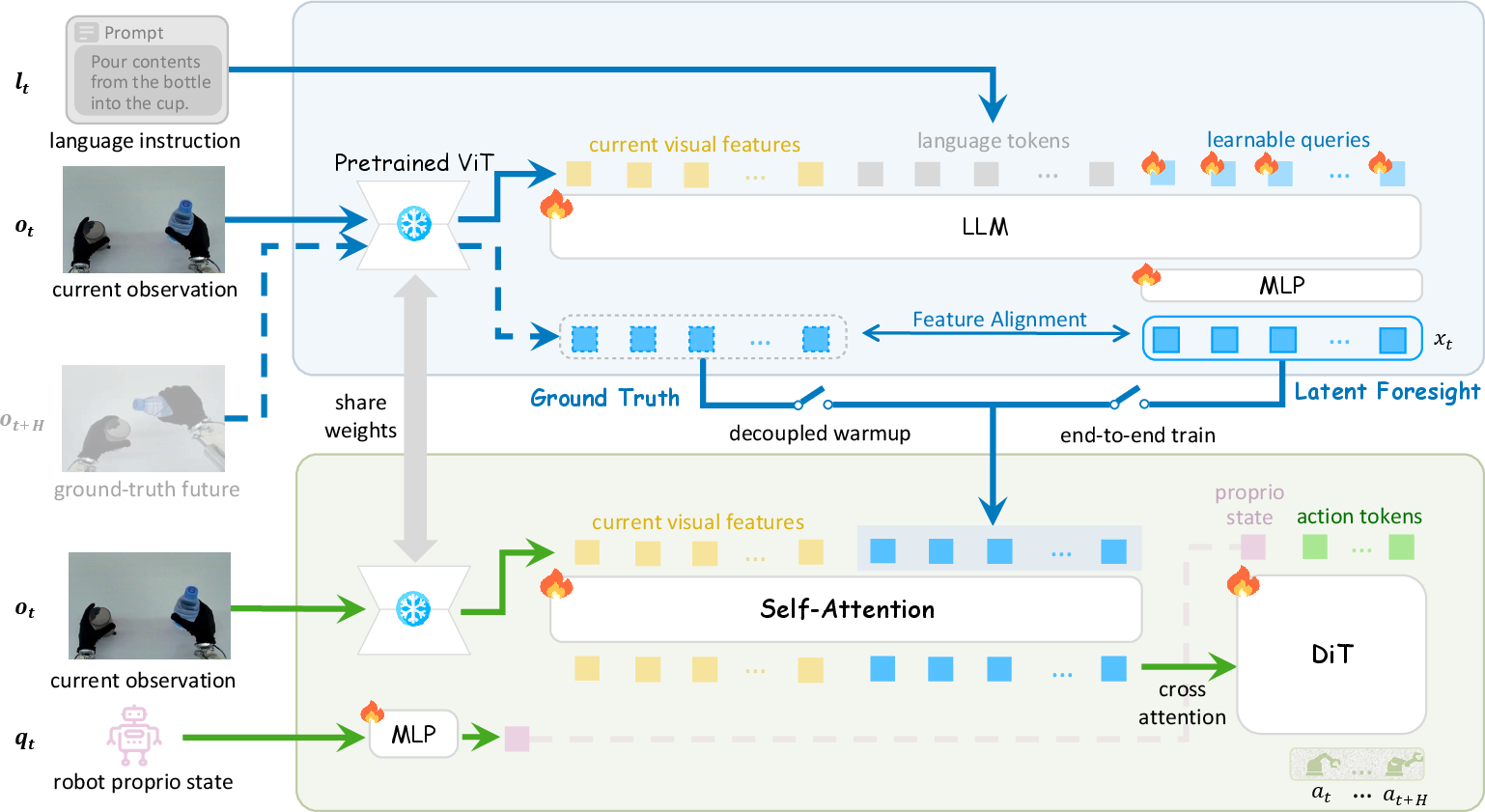
DIAL addresses a core challenge in embodied AI: unifying high-level intent and low-level motor execution within Vision-Language-Action (VLA) architectures. Traditional approaches either introduce non-differentiable bottlenecks (e.g., textual plans or pixel-level goal images) or treat Vision-LLMs (VLMs) merely as feature encoders. The latter leads to unstable optimization and suboptimal utilization of VLM semantic capabilities. DIAL circumvents this issue by decoupling intent and action through a differentiable latent world modeling bottleneck, thereby bridging cognitive high-level reasoning and precise robotic motor control (Figure 1).
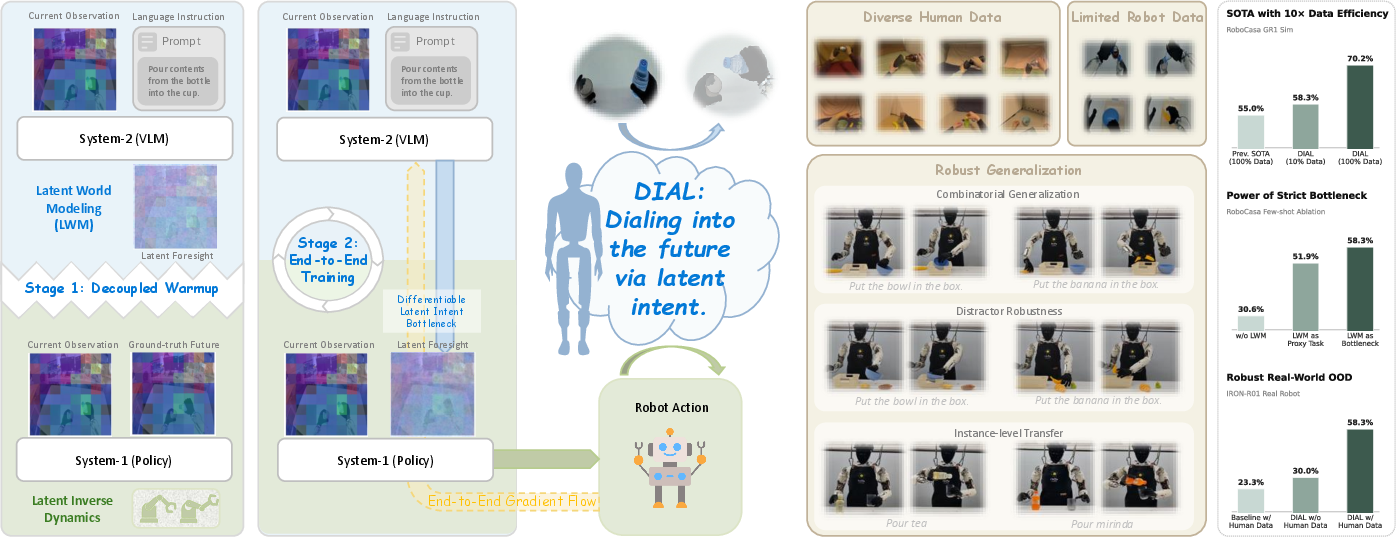
Figure 1: DIAL structurally separates high-level VLM intent synthesis (System-2) and low-level action decoding (System-1) with a differentiable latent bottleneck for robust intent-to-action grounding.
Architectural Contributions
At the core of DIAL is a dual-system model: System-2 (VLM-based) synthesizes predictive latent foresight representing high-level intent within the VLM's ViT feature space. System-1 (policy) acts as a latent inverse dynamics model, decoding the difference between current observations and System-2's predicted foresight into robust, high-frequency motor actions. This architecture is explicitly implemented via:
This methodological stratification ensures that the VLM's decision making is structurally indispensable for the low-level policy, directly mitigating shortcut learning and forcing action policies to be causally dependent on VLM-predicted intent (Figure 3).
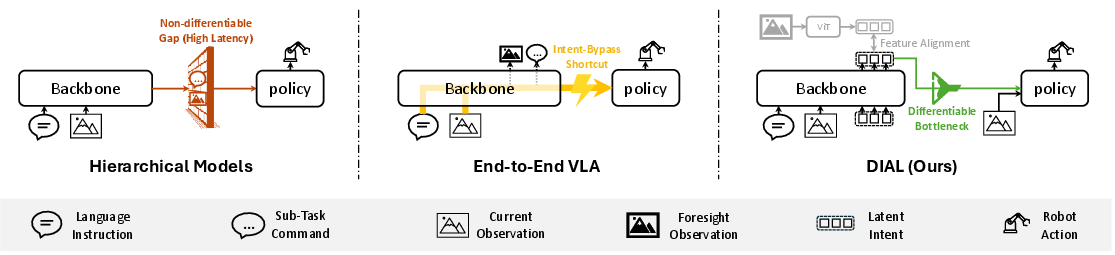
Figure 2: Comparative analysis demonstrates DIAL's strict bottleneck between reasoning and execution, outperforming hierarchical and end-to-end VLA designs without enforced structural grounding.
Empirical Evaluation
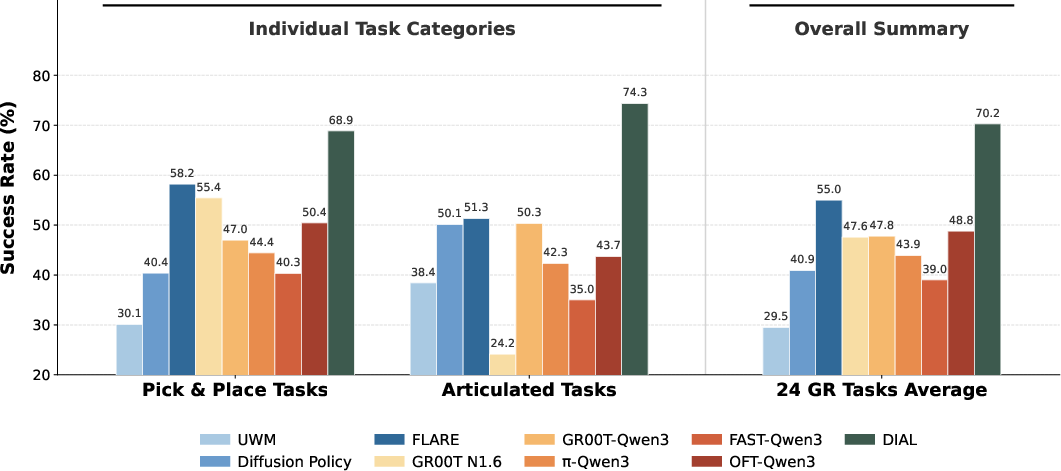
Simulation Benchmarks
On RoboCasa GR1 Tabletop, DIAL establishes a new upper bound for VLA performance:
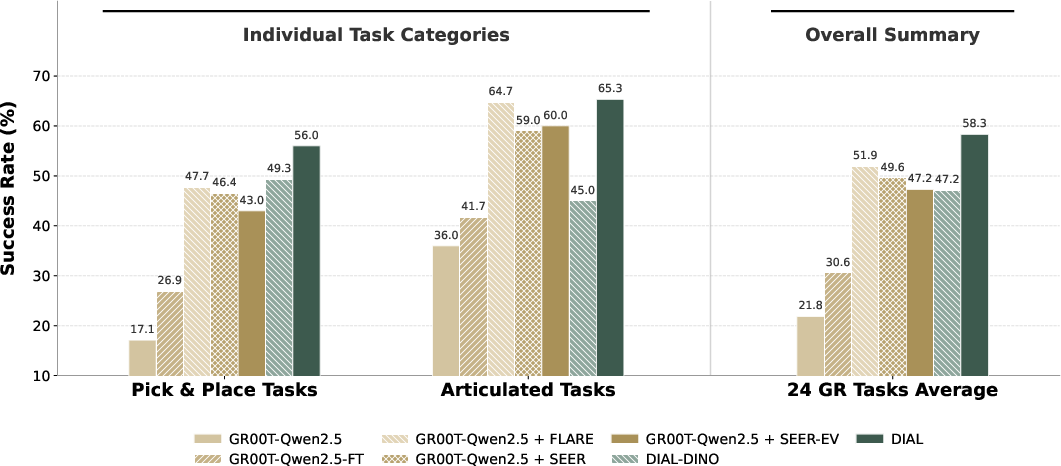
Ablation Analyses
A systematic dissection reveals:
Leveraging Human Data for Scalability
By pre-training on EgoDex human demonstration data, DIAL inherits physically grounded manipulation priors. This integration yields:
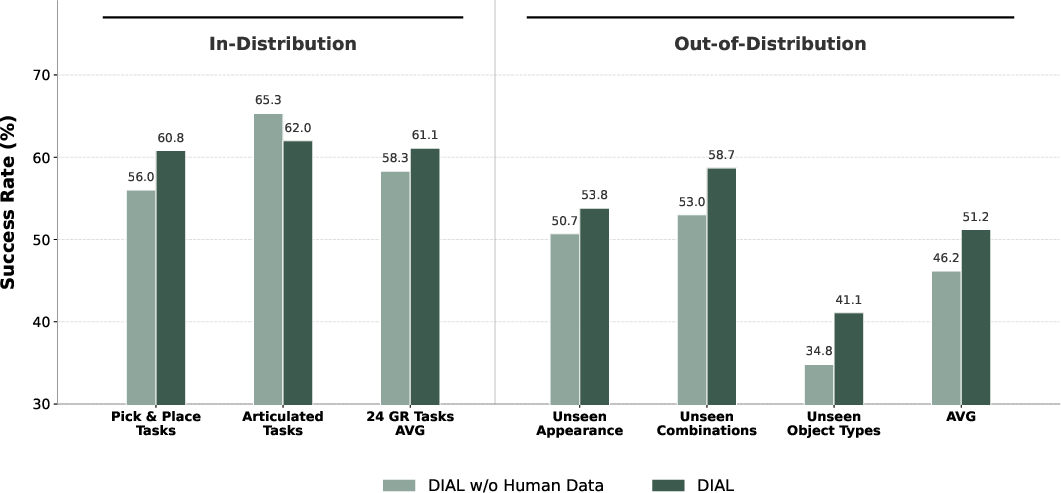
Real-World Validation and Stability
On the IRON-R01-1.11 robot, DIAL maintains robust physical performance:
- In-Distribution: Warmup phase critical for training stability and real-robot success (77.5% with warmup vs 57.5% without).
- Generalization: Consistently outperforms baselines in combinatorial, distractor, and instance-level OOD tasks, enabled by structured comparison between current ViT features and predicted foresight.
- Role of Human Data: Removing human data from pre-training halves OOD performance, emphasizing the need for cross-embodiment demonstration as a semantic prior.
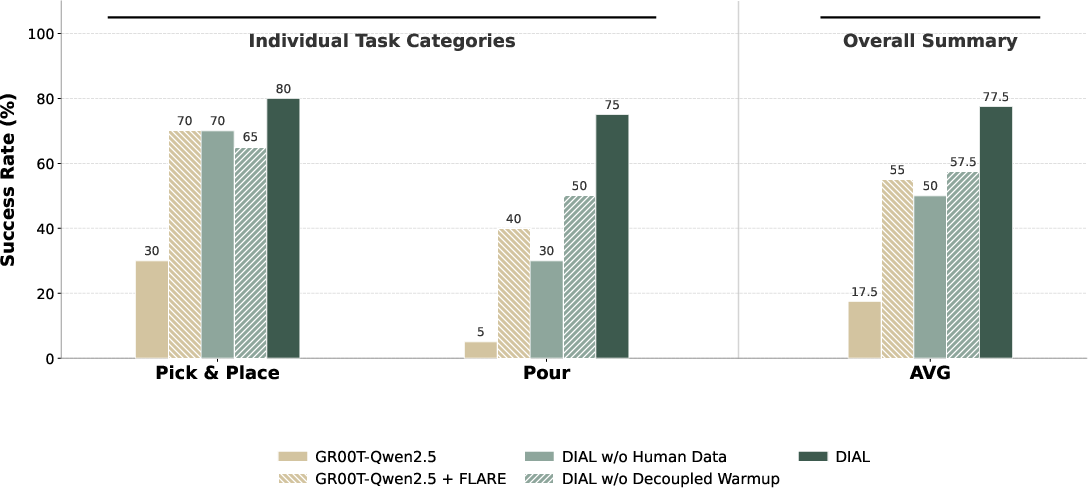
Figure 4: DIAL demonstrates stable execution and generalization on real robots; warmup and human priors are essential.
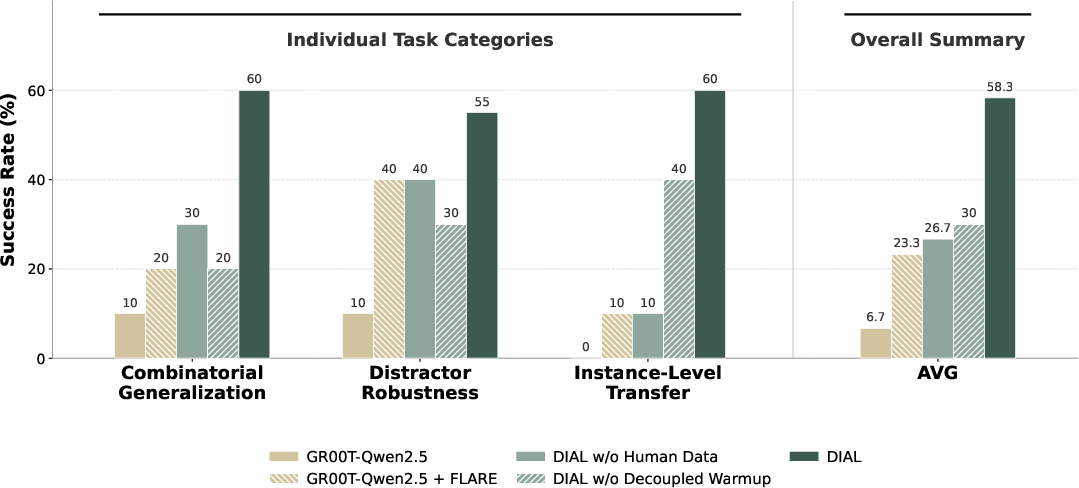
Figure 6: DIAL's zero-shot robustness extends across combinatorial, distractor, and instance transfer settings in the real world.
Foresight Interpretability
Qualitative analyses using PCA projections show that DIAL's latent foresight aligns closely with ground-truth future features in localized, task-relevant areas while diverging from current observations precisely where change is needed. This indicates that System-2 generates an actionable visual roadmap, not mere scene reconstructions, confirming that the structural bottleneck encodes semantically meaningful, task-specific transitions.
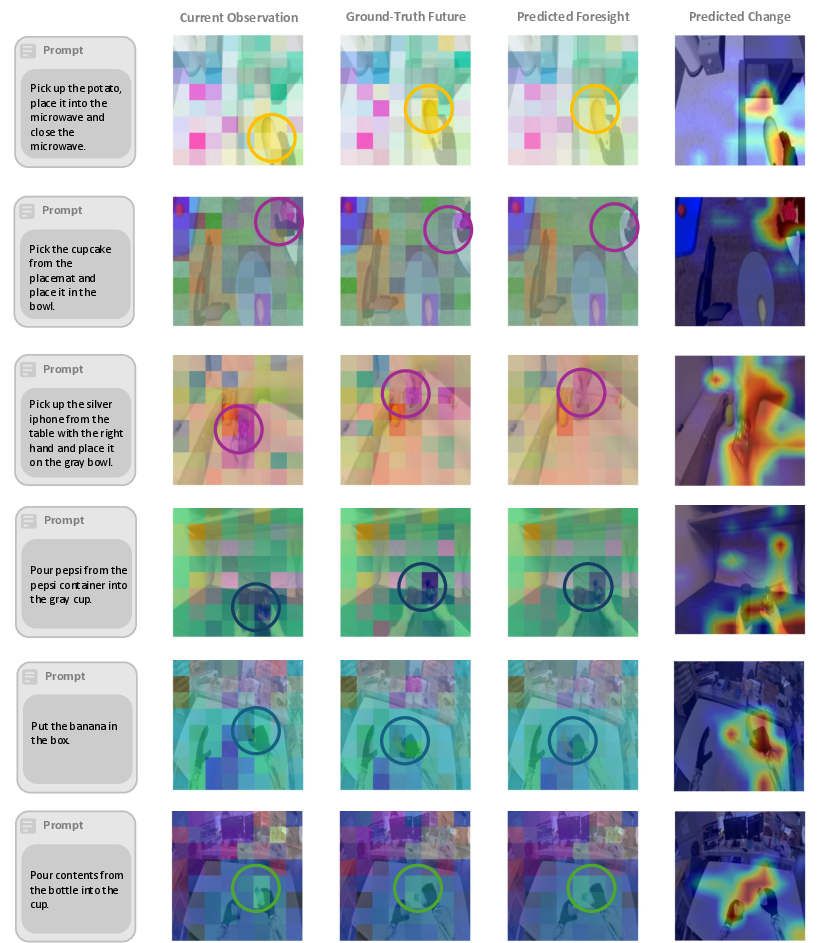
Figure 8: DIAL's latent foresight anticipates spatially- and semantically-precise future scenes, providing interpretable structural guidance for downstream action.
Implications and Future Directions
DIAL's structural decoupling establishes a paradigm where high-level VLM reasoning is directly harnessed for action, enabling:
- Highly data-efficient embodied policy learning with robust zero-shot OOD transfer.
- Seamless integration of human-centric priors through action-free demonstrations.
- Native compatibility with future advances in VLM/ViT pre-training and scalable action modules.
The architecture supports rapid transfer and iteration: a strong System-1 policy can be efficiently paired with new versions of VLM backbones, while further scaling foresight pre-training to large-scale, unlabeled human videos is anticipated to significantly enrich semantic grounding—pushing toward the development of more generalist and adaptive robotic agents.
Conclusion
DIAL systematically solves the structural grounding problem inherent to current VLAs by establishing an explicit, differentiable latent intent bottleneck between VLM-based decision-making and action decoding. This not only enables strong performance and generalization with high sample efficiency but also provides a modular template for future research in scalable, intent-aware embodied agents. Continued advances in VLM, ViT, and effective utilization of unlabeled video remains a promising avenue for the expansion of the DIAL architecture and its real-world applicability.
(2603.29844)