- The paper introduces HIRE, which edits token-wise representations to reduce hallucination without retraining or redundant inference passes.
- It employs a dual-encoder architecture and a lightweight Router to precisely detect and correct hallucinated features while maintaining semantic integrity.
- Empirical evaluations show a 40-50% reduction in hallucination rates across benchmarks, with efficient training on limited data and controllable editing via a hyperparameter.
Motivation and Problem Analysis
Large Vision-LLMs (LVLMs) have achieved impressive capabilities in multimodal reasoning and complex scene understanding through integrating visual encoders with LLMs. Despite these advances, LVLMs exhibit substantial hallucination problems: generated outputs often introduce content not grounded in the visual input, undermining trustworthiness in downstream applications. Prior research has attempted hallucination mitigation via two principal approaches:
- Retraining-based methods: Fine-tune LVLMs with specialized, hallucination-annotated datasets, which yields good performance but at the cost of prohibitive data collection and computational overhead.
- Contrastive decoding (CD) methods: Apply at inference by contrasting predictions under clean and perturbed visual inputs, reducing hallucination but incurring significant inference cost and lacking token-level specificity.
These directions are summarized visually, with the proposed method conceptually distinct in directly editing intermediate representations without model weight updates or redundant inference passes.
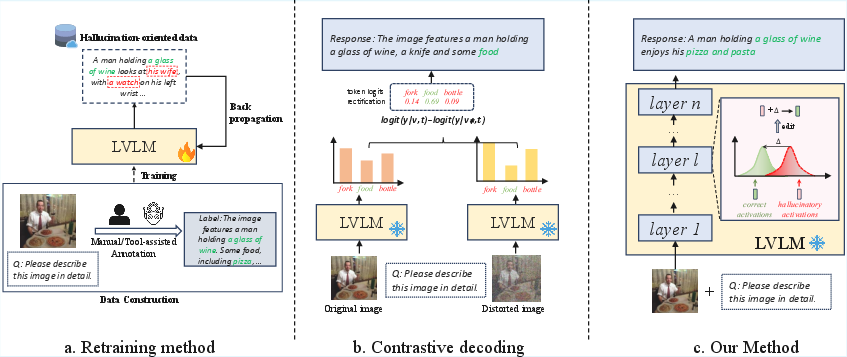
Figure 1: Comparison of mainstream hallucination mitigation paradigms. (a) Retraining-based methods; (b) Contrastive decoding methods; (c) The proposed intermediate representation editing.
HIRE: Framework and Methodology
The paper introduces HIRE (Hallucination-aware Intermediate Representation Edit), a framework that suppresses hallucination by detecting and editing token-wise hidden representations within the LVLM. Rather than retraining or dual-pass inference, HIRE operates via auxiliary modules—an Editor and a Router—trained to leverage the inherent separability of hallucinated versus truthful features in the latent space without modifying main model parameters.
The Editor leverages a dual-encoder architecture: a semantic encoder isolates tokens' core, visual-grounded meaning; a hallucinatory encoder specializes in detecting deceptive or hallucinated features. These encoders are trained via contrastive learning to maximize separation between faithful and hallucinatory representations, with the resulting latent directions used to project hidden states away from hallucination. To limit computational cost, the Router—a lightweight MLP—learns to predict which tokens are at risk of hallucination and enables editing only where necessary, trained by direct preference optimization (DPO) from pairwise faithful/unfaithful outputs.
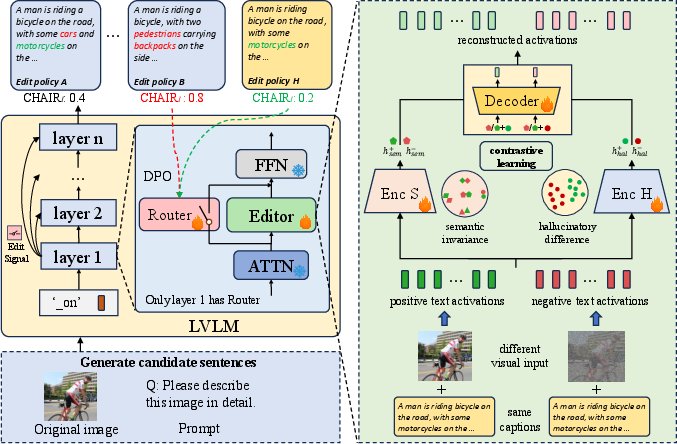
Figure 2: Overview of HIRE, highlighting the Editor's dual encoders and the Router's intelligent editing control.
This pipeline enables dynamic, token-level correction of hidden activations towards truthfulness, with an explicit control parameter (α) for tuning the strength or even direction of hallucination mitigation/amplification.
Empirical Evaluation and Analysis
HIRE is extensively evaluated on the LLaVA-1.5 and InstructBLIP LVLMs over the CHAIR, POPE, and AMBER hallucination benchmarks for both generative and discriminative tasks. The results demonstrate that HIRE achieves superior hallucination mitigation, reporting a reduction of sentence-level (CHAIRS) and instance-level (CHAIRI) hallucination rates by approximately 40% and 50%, respectively—outperforming prior state-of-the-art retraining-based and CD methods, while requiring only a single forward inference pass.
Figures presented in the paper clearly indicate the qualitative and quantitative advantages of HIRE: edited outputs remove hallucinated content and introduce missing, correct content without degrading the overall semantic quality.

Figure 3: Examples from generative and discriminative tasks, with hallucinations (red) suppressed and correct additions (green).
HIRE's performance is robust with respect to training data size: strong mitigation is achieved with as few as 2,500 training samples, thanks to efficient editor/router module parameterization. Control over hallucination is precise—adjusting α smoothly interpolates between hallucination suppression and amplification, demonstrating fine-grained controllability unavailable with CD or retraining-based paradigms.
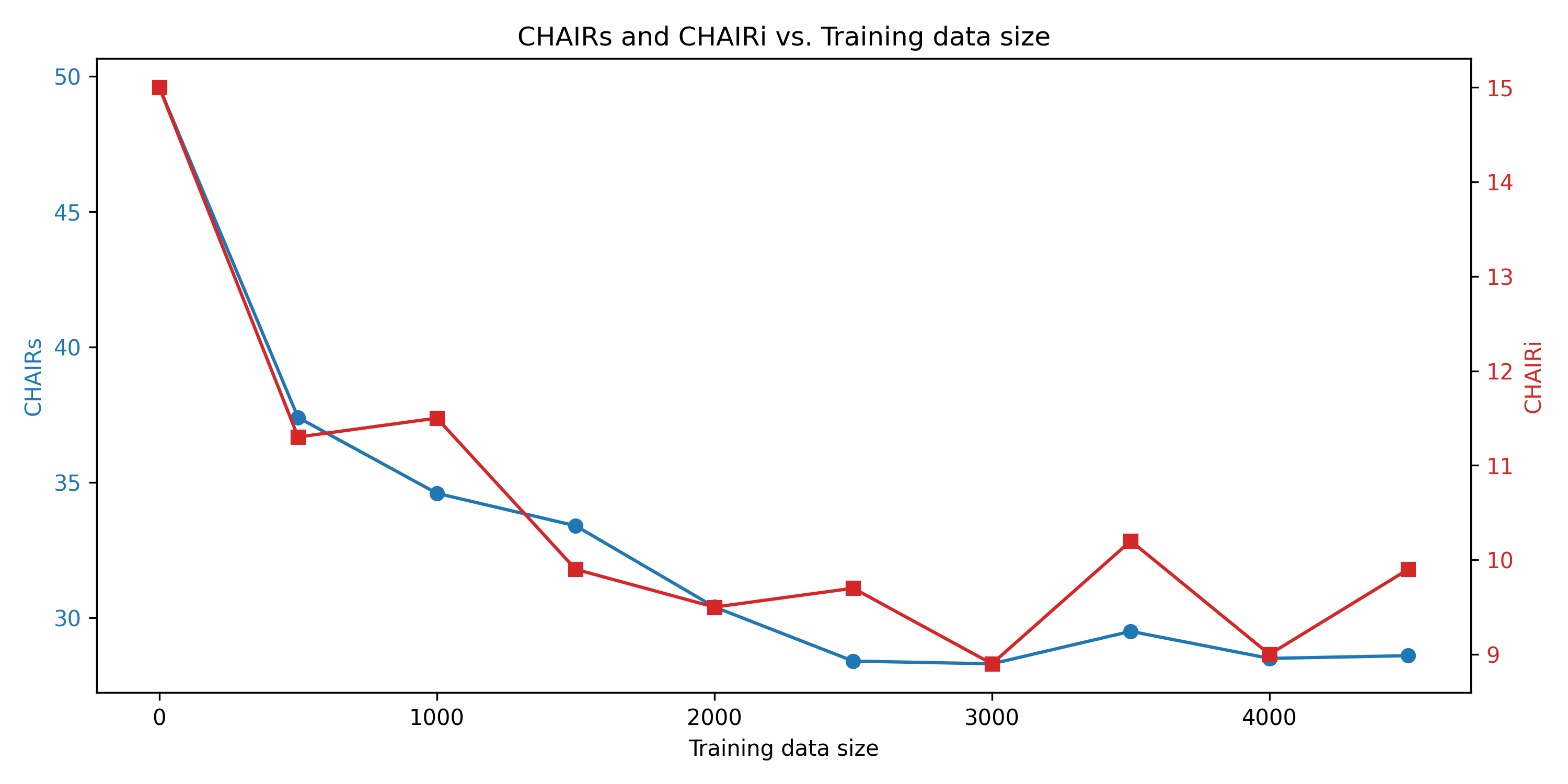
Figure 4: HIRE achieves top-tier performance even under limited training data availability.
Furthermore, ablation experiments validate that the complementary design of semantic and hallucinatory encoders is essential for optimal performance; the router module reduces computational burden by about 30% with negligible impact on suppression efficacy.
Hallucination Controllability and Visualization
A notable innovation of HIRE is explicit, continuous control over hallucination degree via the editing strength hyperparameter. Empirical evidence shows that positive α values reduce hallucination rates, while negative values deliberately enhance hallucinations—a property with implications for tasks where creativity is prioritized over factual grounding.
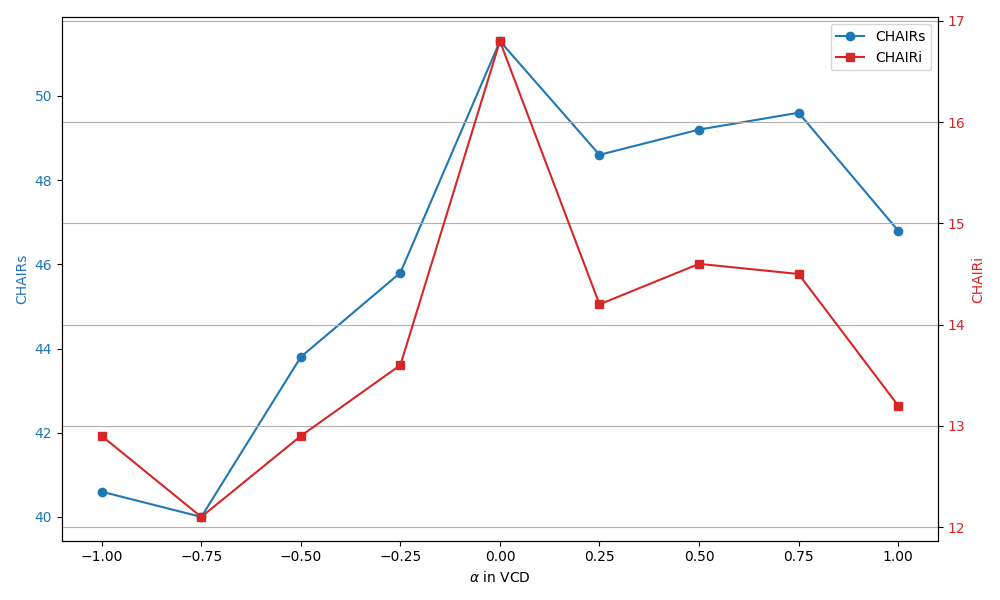
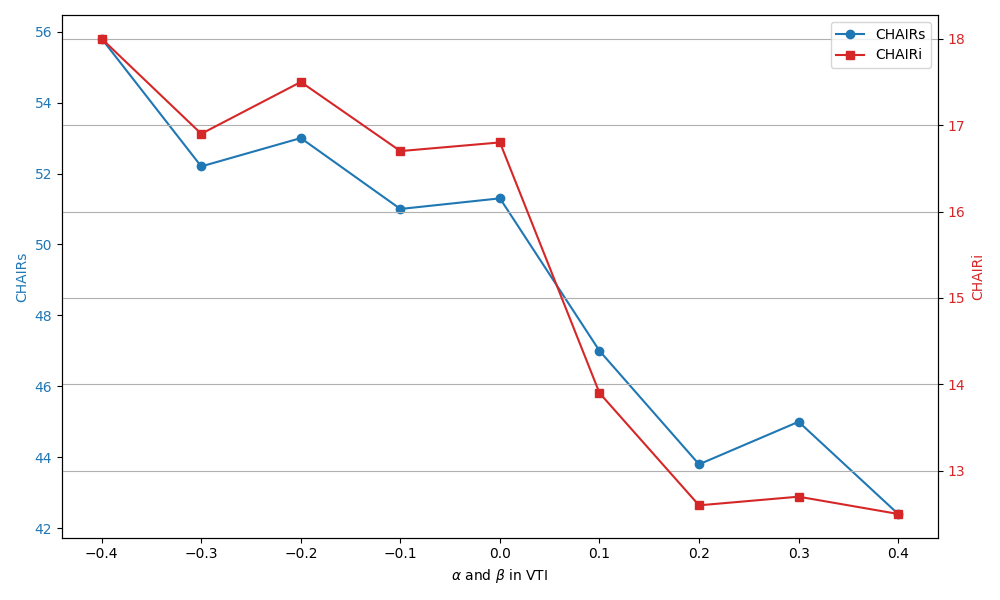
Figure 5: Control over hallucination generation via the hyperparameter α in VCD—HIRE offers more stable and predictable control.

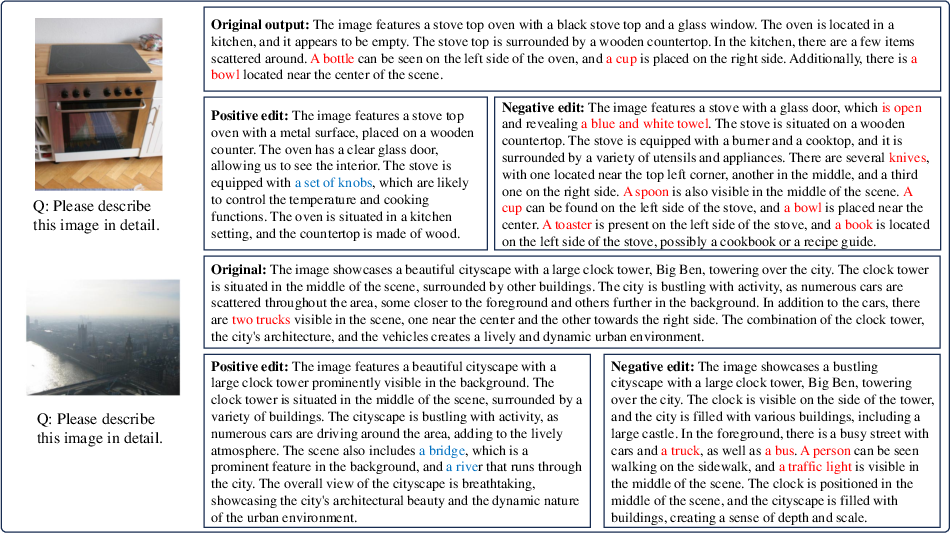
Figure 6: HIRE enables both amplification and mitigation of hallucinations via α.
Qualitative analysis, visualizing both text outputs and representation space distributions, shows that HIRE moves hallucinated features towards the non-hallucinated cluster, confirming its efficacy at the feature level.
Compatibility and Future Extensions
HIRE is orthogonal to, and therefore compatible with, other steering-based approaches that operate at the model weight or visual feature levels, enabling hybrid solutions for further suppression. Additionally, HIRE preserves general capabilities on broader benchmarks (MME, SEED-Bench) and generalizes well to other architectures (Qwen2.5-VL, TinyLLaVA), suggesting transferability across LVLM families.
This direct feature-level editing paradigm offers insights into LVLM interpretability and delegation of control to external modules, opening new theoretical questions regarding the disentanglement and manipulation of semantic and hallucinatory subspaces. The modular structure further supports scalable, application-aware hallucination regulation.
Conclusion
The paper presents HIRE, a novel and efficient feature-editing-based paradigm for hallucination mitigation in LVLMs. By dynamically detecting hallucinated intermediate representations and editing them without retraining or dual inference, HIRE sets new state-of-the-art benchmarks in both generative and discriminative settings. The framework provides precise, user-controllable regulation of hallucination with minimal computational overhead, strong sample efficiency, and compatibility with conventional steering methods.
The practical implication is a step towards deployable, trustworthy LVLMs across domains requiring factual grounding. On a theoretical front, this work motivates deeper analysis of latent feature interpretability and external alignment of large pre-trained models. Future research may target selective, layer-wise feature intervention and further extension of plug-and-play controllability paradigms in multimodal AI.