Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification
Published 31 Mar 2026 in cs.LG and cs.AI | (2603.29148v1)
Abstract: Graph Convolutional Network (GCN) is a model that can effectively handle graph data tasks and has been successfully applied. However, for large-scale graph datasets, GCN still faces the challenge of high computational overhead, especially when the number of convolutional layers in the graph is large. Currently, there are many advanced methods that use various sampling techniques or graph coarsening techniques to alleviate the inconvenience caused during training. However, among these methods, some ignore the multi-granularity information in the graph structure, and the time complexity of some coarsening methods is still relatively high. In response to these issues, based on our previous work, in this paper, we propose a new framework called Efficient and Scalable Granular-ball Graph Coarsening Method for Large-scale Graph Node Classification. Specifically, this method first uses a multi-granularity granular-ball graph coarsening algorithm to coarsen the original graph to obtain many subgraphs. The time complexity of this stage is linear and much lower than that of the exiting graph coarsening methods. Then, subgraphs composed of these granular-balls are randomly sampled to form minibatches for training GCN. Our algorithm can adaptively and significantly reduce the scale of the original graph, thereby enhancing the training efficiency and scalability of GCN. Ultimately, the experimental results of node classification on multiple datasets demonstrate that the method proposed in this paper exhibits superior performance. The code is available at https://anonymous.4open.science/r/1-141D/.
The paper introduces GB-CGNN, presenting a granular-ball based coarsening framework that achieves linear time complexity for efficient large-scale graph node classification.
It leverages multi-granularity structural information via adaptive partitioning and binary splitting, reducing neighborhood explosion in GCNs.
Empirical results across diverse datasets confirm superior scalability, memory efficiency, and high classification accuracy against sampling-based and condensation methods.
Efficient and Scalable Granular-ball Graph Coarsening for Large-scale Graph Node Classification
Motivation and Background
Graph Convolutional Networks (GCNs) are powerful for modeling graph-structured data, enabling substantial advances across domains such as social network analysis, bioinformatics, and recommender systems. However, escalating graph sizes introduce prohibitive computational costs, especially as GCN depth increases. Existing approaches—sampling, condensation, and coarsening—address scalability but neglect multi-granularity structural information or present high time complexity, limiting efficiency and representation quality.
The granular-ball computing paradigm, inspired by the "global precedence" principle from cognitive science, offers an avenue to reconcile scalability and granularity. By iteratively coarsening graphs at multiple granularities, this concept facilitates efficient, robust graph representations.
The presented work introduces GB-CGNN, an Efficient and Scalable Granular-ball Graph Coarsening Method tailored for large-scale node classification. The method leverages adaptive granular-ball partitioning to achieve linear time complexity, outperforming prior coarsening schemes and competing GCN sampling-based methods.
Granular-ball Coarsening Framework
Neighborhood Expansion Analysis
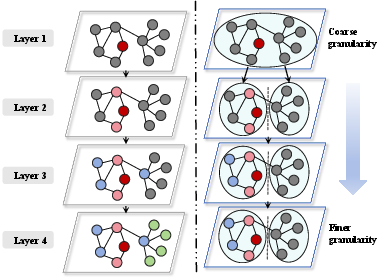
Traditional GCNs suffer exponential neighborhood expansion with increased layers due to recursive neighbor aggregation, causing inefficiency and "neighbor explosion." The proposed method constrains neighborhood expansion by leveraging multi-granularity structural capturing. This limits the convolutional scope and preserves essential connectivity patterns.
Figure 1: The proposed coarsening approach limits exponential neighborhood expansion by capturing structural information at multiple granularities.
GB-CGNN Architecture
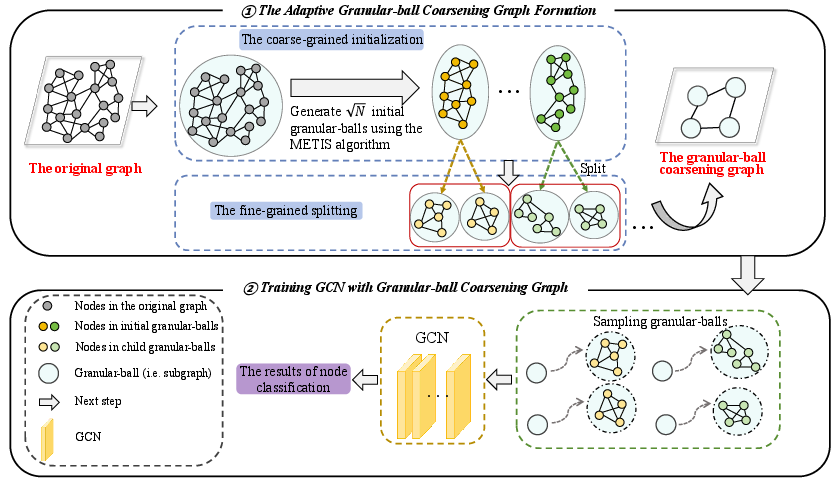
GB-CGNN executes graph coarsening in two principal stages:
Adaptive Granular-ball Coarsening Formation: The graph is recursively partitioned using METIS for coarse initialization and binary splitting for fine-grained refinement, governed by node connectivity quality metrics.
Training GCN with Granular-ball Coarsening Graph: Randomly sampled granular-balls form minibatches, each representing tight, cohesive subgraphs. GCN training proceeds on these batches, enabling scalability and locality-aware representation learning.
Figure 2: GB-CGNN framework showing adaptive granular-ball coarsening and subsequent GCN training using sampled granular-ball subgraphs.
Coarsening Procedure
METIS partitions the graph into N initial granular-balls, optimizing edge cuts and load balancing.
Quality metric, defined as average degree (AD=E/N), guides adaptive granular-ball splitting via binary partitioning.
Splitting proceeds if the average quality increases, preventing unnecessary fragmentation and retaining cohesive substructures.
Resultant granular-balls become supernodes; interGranular-ball edges are induced if connections exist between their contained nodes.
Theoretical Guarantee
The Rayleigh quotient preservation is demonstrated, leveraging projection matrices C to ensure spectral similarity between the original and coarsened graphs, implying minimal structural distortion and sound approximation for downstream tasks.
GCN Training Protocol
Training operates on block-diagonal adjacency matrices derived from granular-ball subgraphs, exploiting the decomposability for efficient minibatch training. Only local computations within granular-balls are required, and global graph access is avoided, drastically reducing memory footprint and computational overhead.
Complexity Analysis
Coarsening Stage: Achieves O(N) time complexity via efficient METIS partitioning and binary splitting restricted to local granular-ball neighborhoods.
Training Stage: Each batch scales as O(∥Aii∥0F+BF2), with overall epoch complexity O(L∥A∥0F+LNF2).
Memory: Loading only batches of B nodes per layer, yielding O(BLF+LF2) per epoch, suitable for GPU-bound computation.
Empirical Evaluation
Scalability and Coarsening Efficiency
GB-CGNN demonstrates orders-of-magnitude improvement in coarsening time compared to prior granular-ball and spectral coarsening methods, especially on graphs with nodes ranging up to millions. Out-of-memory failures in other methods underscore the critical advance in practical scalability.
Node Classification Performance
Node classification tasks across citation, social, biological, and e-commerce graphs showcase GB-CGNN's superior Micro-F1 scores. It achieves optimal or near-optimal results on 11/12 datasets, surpassing sampling-based baselines (FastGCN, GraphSAINT), condensation approaches (GCOND), and prior granular-ball techniques.
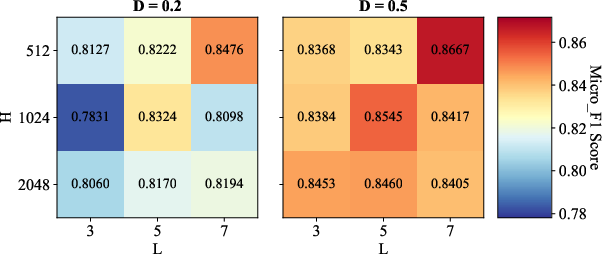
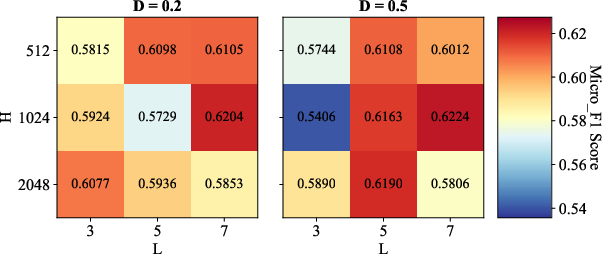
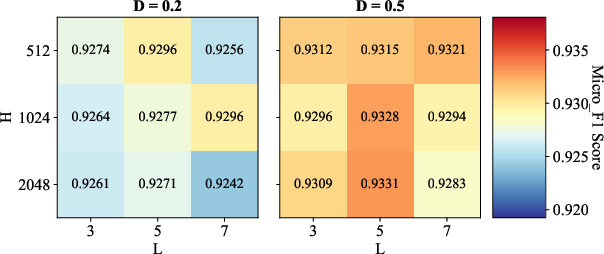
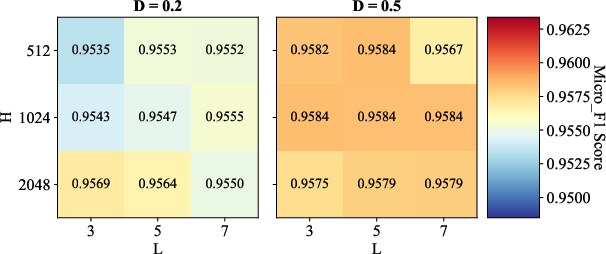
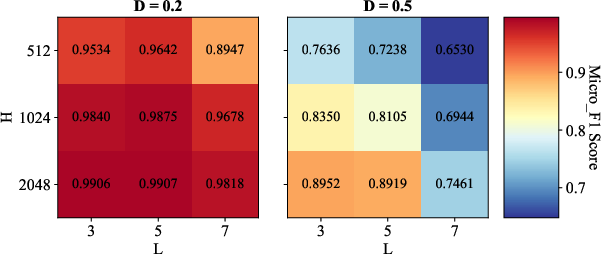
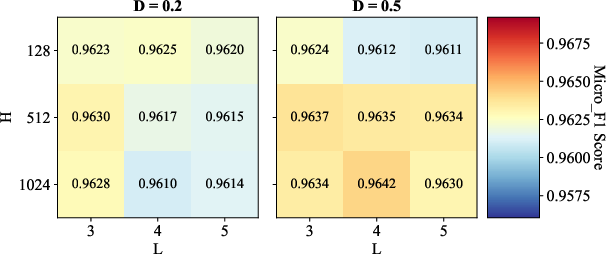
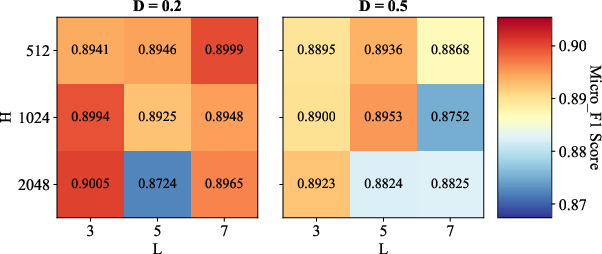
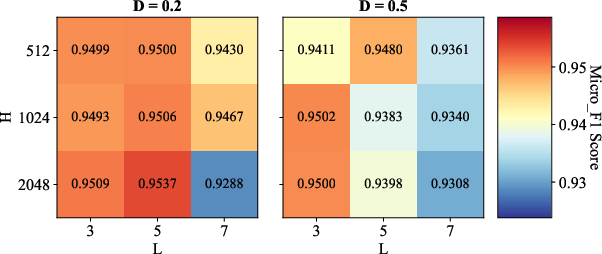
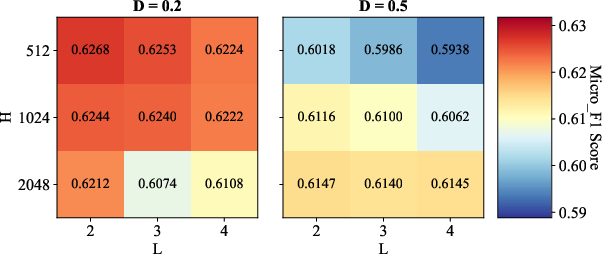
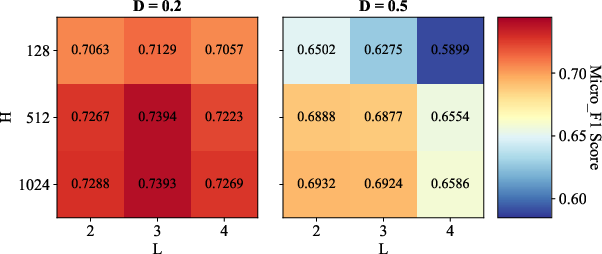
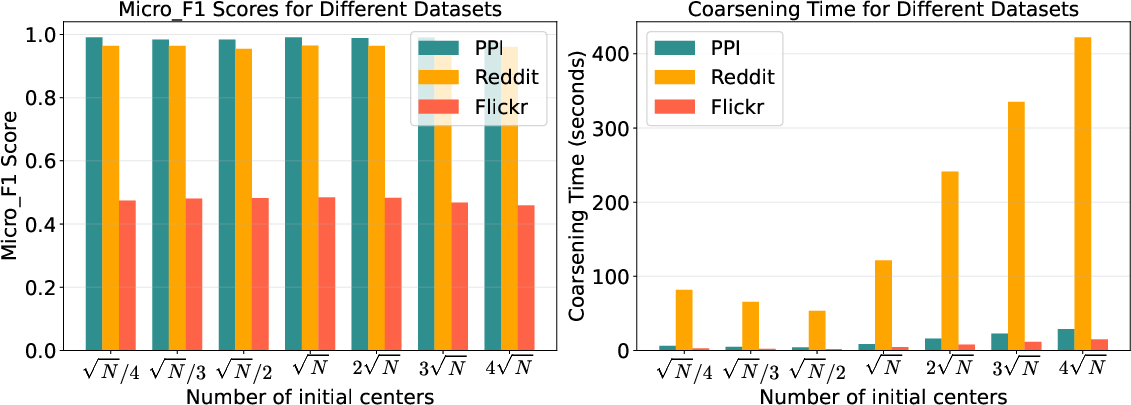
Parameter Sensitivity and Ablations
Comprehensive sensitivity analyses reveal the synergistic importance of convolution depth (L), hidden size (H), and dropout (AD=E/N0), as well as the robust effect of initial granular-ball center counts (AD=E/N1). Ablation studies confirm that both METIS-based coarse initialization and binary splitting are essential—removing either degrades classification accuracy or coarsening speed, depending on the data scale.
Figure 3: Sensitivity analysis illustrates the influence of AD=E/N2, AD=E/N3, and AD=E/N4 on classification performance across benchmark datasets.
Figure 4: Performance and efficiency trade-offs when varying the number of initial granular-ball centers.
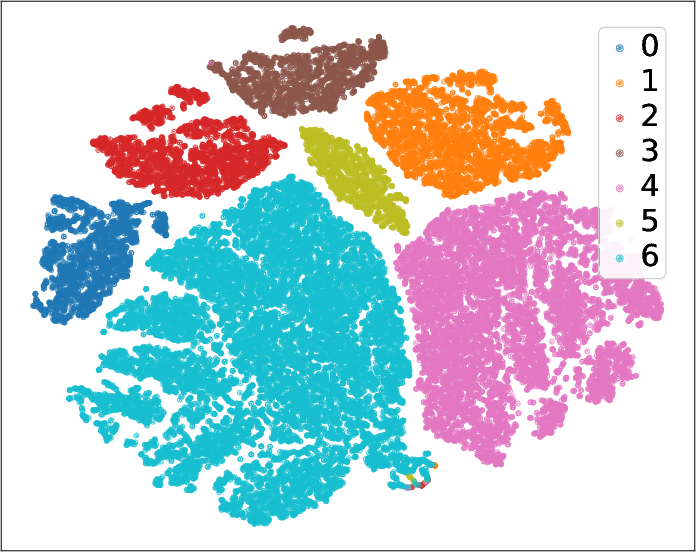
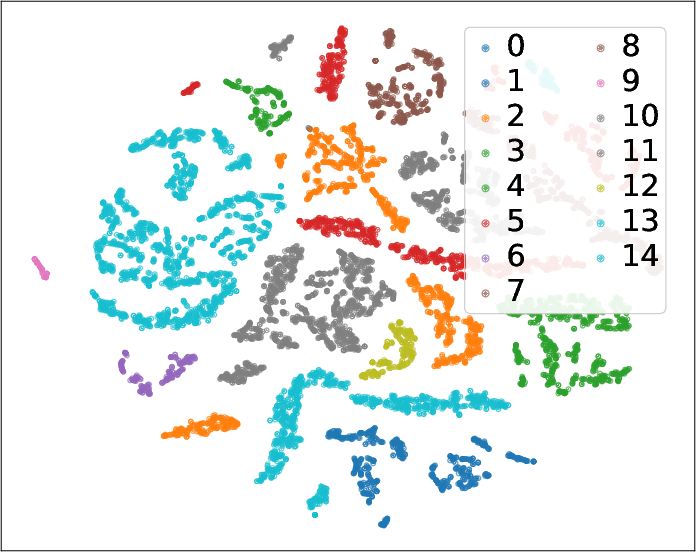
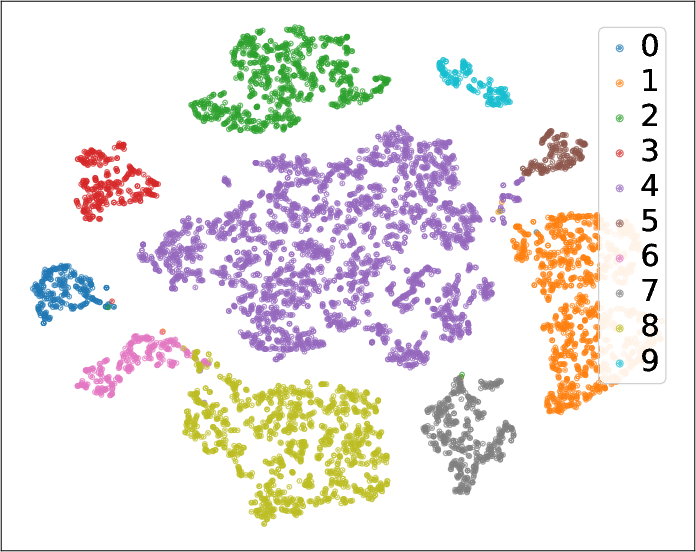
Embedding Visualization
t-SNE projections of node embeddings, post-training, confirm effective class separation and structural coherence, demonstrating consistent intra-class clustering and clear inter-class boundaries.
Figure 5: Node embeddings after GB-CGNN training, visualized for PubMed, Cocs, Flickr, and Computers; colors denote node classes.
Quality Metric Effects
Alternative granular-ball quality metrics (purity, purity + average degree) are evaluated. Exclusively structural metrics (average degree) yield superior classification outcomes and feasible coarsening times, especially for large graphs, while label-purity-based splitting leads to inefficient coarsening and impaired representation quality.
Implications and Future Directions
GB-CGNN advances the state-of-the-art in scalable graph coarsening for GCN training, demonstrating linear time complexity, efficient memory utilization, and high classification accuracy. The explicit modeling of multi-granularity structure, informed by both global and local connectivity, enables robust embeddings well-suited for node classification.
Practically, GB-CGNN’s architecture supports massive graph data processing in network analysis, drug discovery, fraud detection, and recommendation, with universal applicability where GNN scalability is a bottleneck.
Theoretically, the approach opens avenues for exploring dynamic granular-ball splitting, structure-adaptive quality metrics, integration with attention mechanisms, and extending the framework to heterogeneous graphs or temporal datasets. Further research may yield advances in interpretable GNNs, causal structure preservation, and transferability across domains.
Conclusion
The GB-CGNN method provides a formally grounded, efficient coarsening framework for large-scale graph node classification. It achieves linear-time coarsening, state-of-the-art accuracy, and practical scalability via adaptive granular-ball computing. Its robust empirical and theoretical foundations create a promising trajectory for future scalable GNN developments and widespread adoption in large-scale graph analytics.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.