- The paper establishes a Lipschitz-based generalization bound that links demonstration quality and distribution shift to in-context learning performance.
- It formalizes chain-of-thought prompting as task decomposition, showing when CoT improves compositional learning through well-chosen subtasks.
- It characterizes how prompt templates and demonstration count interact, revealing exponential decay in prompt sensitivity with consistent instructions.
Theoretical Characterization of In-Context Learning: Demonstrations, CoT, and Prompt Templates
Introduction
This paper ("Demonstrations, CoT, and Prompting: A Theoretical Analysis of ICL" (2603.19611)) develops a rigorous theoretical framework for understanding In-Context Learning (ICL) in LLMs. The analysis eschews restrictive architectural assumptions prevalent in prior work—such as linear attention, single-layer transformers, or i.i.d. data—in favor of mild, general conditions that capture practical design factors: demonstration selection, Chain-of-Thought (CoT) prompting, number of demonstrations, and prompt templates. The primary contributions include:
- Establishing a generalization bound for ICL test loss using Lipschitz continuity, quantifying the effectiveness of demonstrations and the impact of task ambiguity and distribution shift.
- Formalizing CoT prompting as task decomposition, showing conditions under which CoT improves ICL performance.
- Characterizing the effect of prompt templates and demonstration count, deriving bounds that explain prompt sensitivity decay and failures in specific formats.
The theoretical claims are substantiated by synthetic and empirical evaluations, demonstrating alignment between the proposed framework and observed ICL behaviors.
Lipschitz Generalization Bound for Demonstrations
Central to the analysis is the derivation of a Lipschitz-based generalization bound. The ICL test loss is controlled by three factors:
- The intrinsic ICL capability of the pretrained model.
- The effectiveness of demonstrations in identifying the underlying task, captured by the minimum Lipschitz constant of the ICL loss along paths from test prompts to pretraining samples.
- The degree of distributional shift between the test and pretraining domains.
The bound establishes that performance degrades exponentially with the Lipschitz constant and shift, unless demonstrations robustly resolve task ambiguity and align with pretraining. This quantifies the tradeoff between task retrieval and local adaptation mechanisms in ICL.
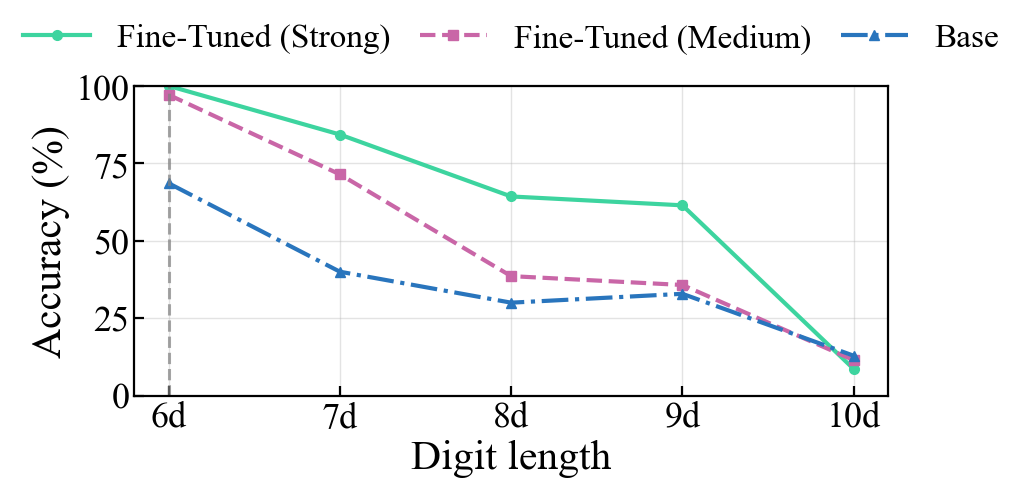
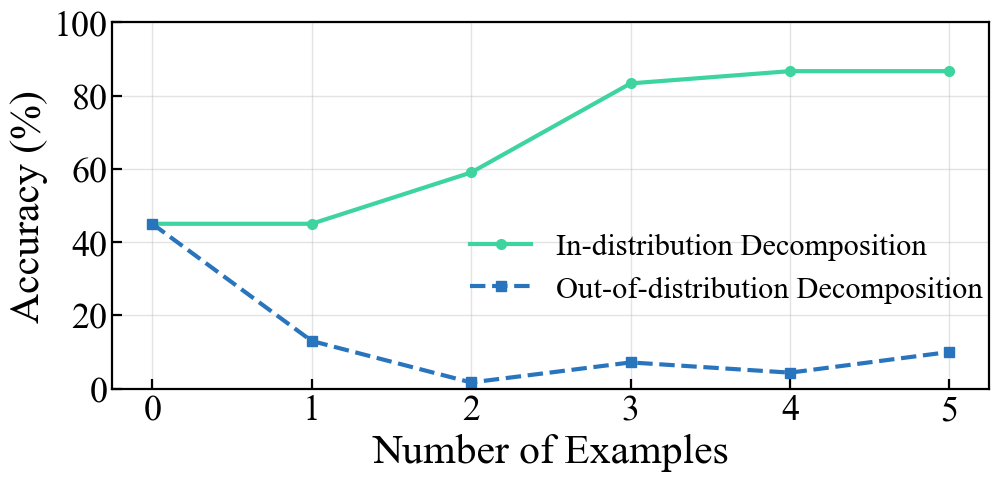
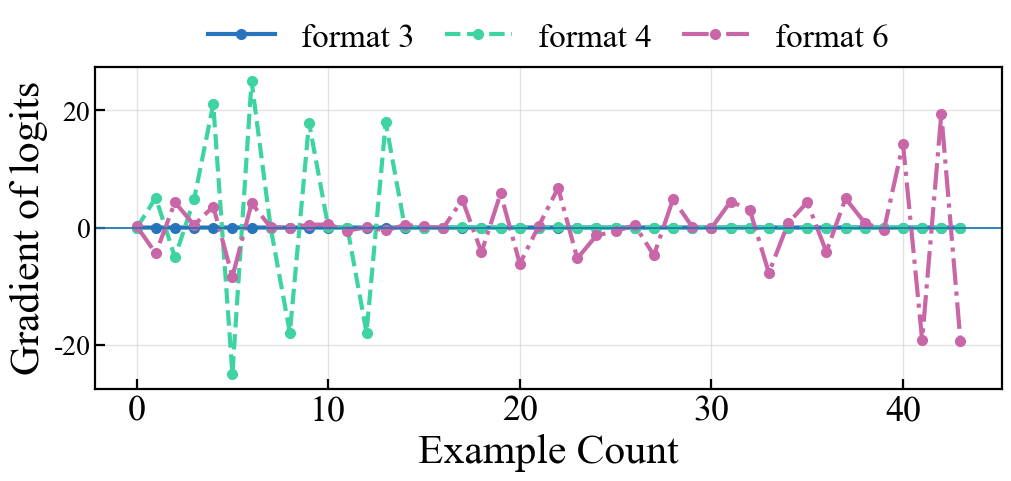
Figure 1: ICL accuracy as a function of digit length and intrinsic model capability, highlighting convergence in accuracy as task shift increases—reflecting the dominance of the Lipschitz constant.
Empirical results validate these predictions: test accuracy among model variants with different intrinsic ICL capability diverges when prompts are close to the pretraining distribution, but converges at low levels as task shift increases, indicating that the Lipschitz constant governs generalization when intrinsic capability is insufficient.
Chain-of-Thought Prompting as Task Decomposition
The paper presents a formalization of CoT prompting in ICL as task decomposition. The generalization bound for CoT-augmented prompts decomposes the overall loss into a sum of losses incurred at subtasks, each weighted by the Lipschitz constant of the induced path in prompt space.
- CoT is beneficial when decomposition yields subtasks that are well-learned and demonstrations are well-chosen for each substep.
- If decomposition is misaligned with pretraining (i.e., out-of-distribution subtasks), CoT can degrade performance.
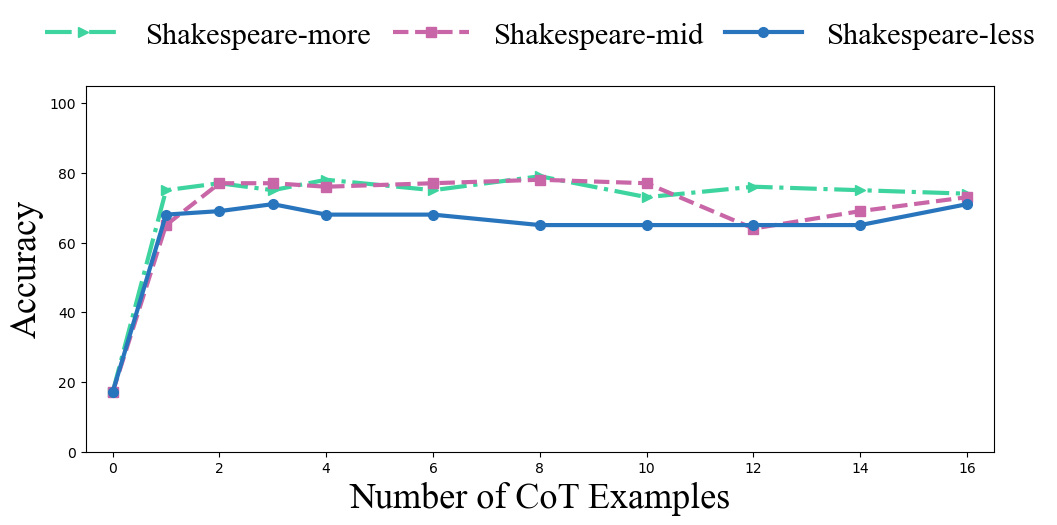
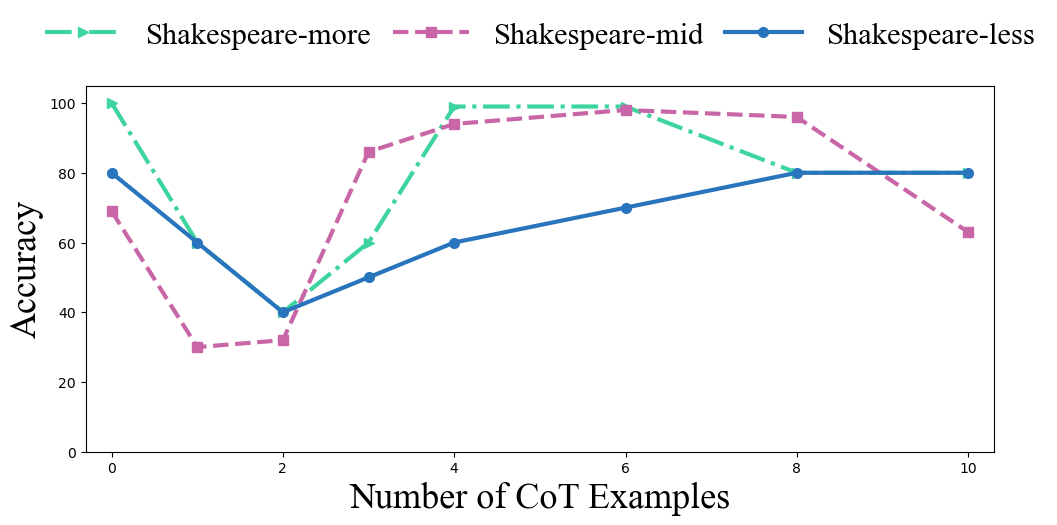
Figure 2: Effect of structured distractors during pretraining on CoT accuracy—showing model robustness to irrelevant steps when pretraining supports selective suppression.
(Figure 1) also demonstrates empirical gains for in-distribution CoT decompositions relative to vanilla ICL, with performance dropping precipitously in out-of-distribution decomposition regimes as predicted by the theory.
Prompt Templates, Demonstration Count, and Instruction Sensitivity
The framework analyzes how prompt templates interact with demonstration count, revealing exponential decay of prompt sensitivity under formats with consistent instructions:
- When demonstrations are informative and instructions are consistent (formats 1–5), the influence of prompt templates on output probabilities decays exponentially as demonstration count increases, enabling reliable task retrieval from demonstrations.
- When instructions are inconsistent and incorrect (format 6), sensitivity persists despite increasing demonstrations—indicative of failure in task identification.
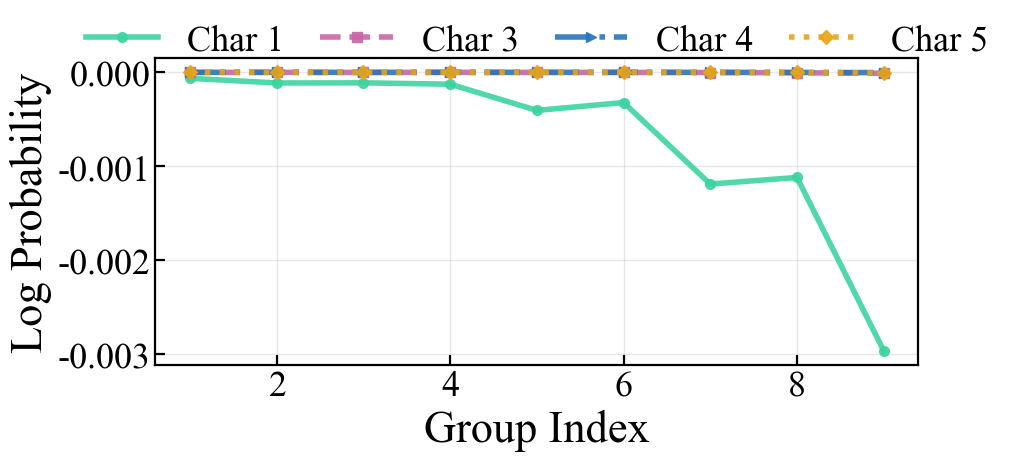
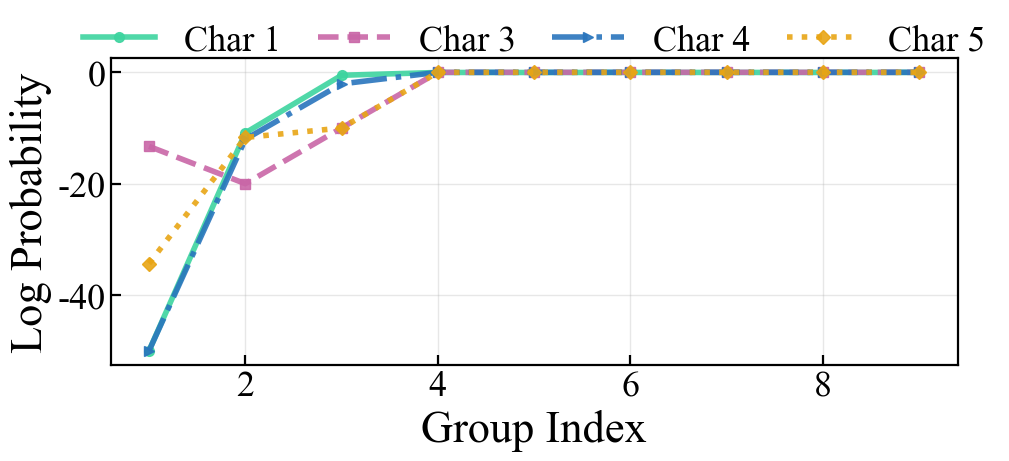
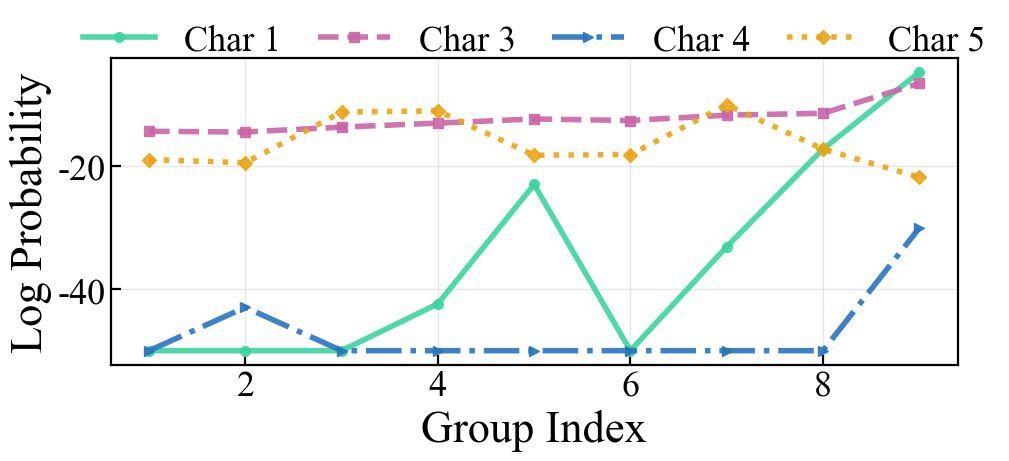
Figure 3: Equivalent instructions demonstrating prompt stability across demonstrations.
Figure 4: Posterior confidence and gradient behavior under instruction variation; (a) Stable high-confidence with equivalent instructions, (b) recovery with consistent incorrect instructions, (c) persistent instability with inconsistent instructions.
Empirical traces of output gradient magnitudes with respect to instruction tokens corroborate these claims: prompt sensitivity diminishes for consistent instructions, but remains high (or even increases) for inconsistent formats.
Practical and Theoretical Implications
The theoretical results have several implications:
- Pretraining induces a latent task space that supports generalization via retrieval and composition, not just memorization.
- Demonstrations act as retrieval keys, pinning down tasks or subtasks commensurate with the pretraining domain.
- CoT prompting extends generalization to compositional tasks, provided subtasks correspond to pretraining-supported routines.
- Prompt engineering—choice and consistency of instructions, demonstration selection, and decomposition strategy—directly impacts generalization, explaining empirical variability in ICL outcomes.
- The framework offers a foundation to study prompt-level phenomena such as hallucination, adversarial robustness, and security through the lens of task ambiguity and pathwise loss variation.
Speculatively, future developments in AI may leverage these insights to optimize prompt construction for robust generalization, mitigate failures stemming from task ambiguity, and engineer models capable of precise task retrieval and composition in open-ended domains.
Conclusion
This work rigorously characterizes the factors governing ICL generalization in LLMs, providing a Lipschitz-based theory that links demonstration quality, CoT structure, prompt templates, and demonstration count to downstream performance. It establishes conditions under which ICL reliably retrieves and composes pretrained capabilities, as well as those in which prompt variation disrupts task identification and generalization. The linkage between practical prompt engineering and theoretical risk bounds offers actionable guidance for designing robust in-context learners, and a foundation for further exploration of prompt-induced errors, security, and compositionality in advanced AI systems.