- The paper presents a unified framework that uses vision token manipulation to reduce hallucinations in MLLMs by enhancing visual grounding and correcting latent biases.
- The approach leverages Synergistic Visual Calibration (SVC) and Causal Representation Calibration (CRC) to counteract visual fading and bias without additional training overhead.
- Experimental results on benchmarks like POPE and CHAIR demonstrate improved object recognition accuracy and a significant reduction in sentence-level hallucinations.
Summary of "One Token, Two Fates: A Unified Framework via Vision Token Manipulation Against MLLMs Hallucination"
Introduction
The paper "One Token, Two Fates: A Unified Framework via Vision Token Manipulation Against MLLMs Hallucination" (2603.10360) presents a novel approach to address the problem of hallucination in Multimodal LLMs (MLLMs). MLLMs have shown significant capabilities in multimodal reasoning, yet they suffer from hallucinations—an issue where generated text contradicts visual information. The authors propose a unified framework leveraging the vision token for both visual signal enhancement and model bias correction, which tackles the systemic vision-language imbalance inherent in MLLMs.
Unified Framework Proposal
The unified framework proposed operates at the representation level, enabling simultaneous execution of two processes using vision tokens. The Synergistic Visual Calibration (SVC) module enhances visual grounding by integrating augmented tokens to counteract visual fading during text generation. Concurrently, the Causal Representation Calibration (CRC) module uses pruned tokens as in-distribution negative samples to correct biases in the model's latent states, thus reducing hallucination occurrences.
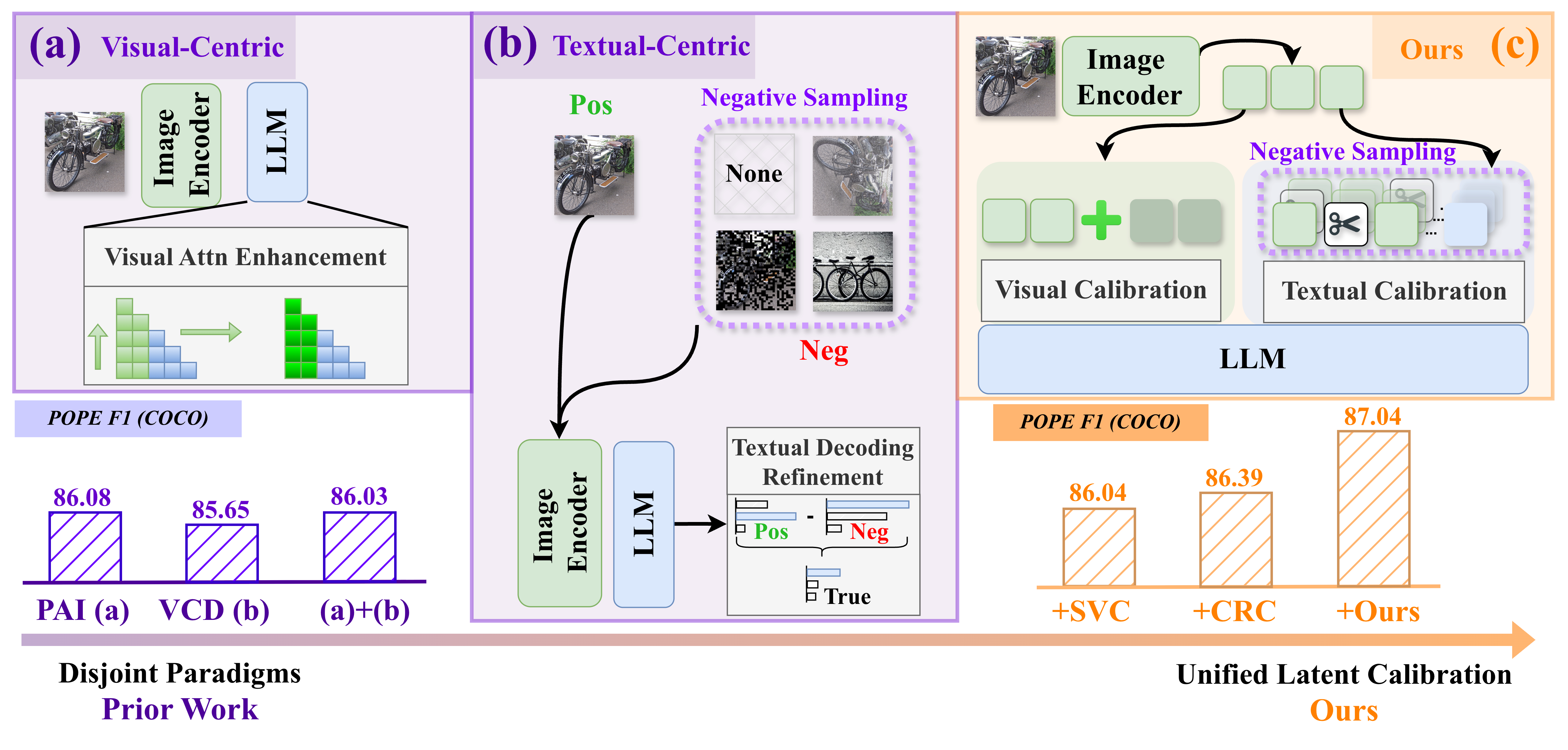
Figure 1: Disjoint Paradigms vs. Our Unified Latent Calibration. Naive combination of different methods degrades performance, highlighting the need for a unified approach.
Figure 2: Our Three Core Findings—diagnosing imbalance in visual grounding—and the superiority of information-gap negative sampling.
Theoretical Underpinnings
The theoretical foundation of the paper lies in the treatment of hallucination as a causal problem where latent model biases interfere with true visual signals. The authors utilize Structural Causal Models (SCM) to model and address these spurious pathways from biases to latent representations. By isolating these biases, the CRC mechanism performs a counterfactual adjustment, leveraging latent space differential vectors to achieve effective bias probing and visualization correction.
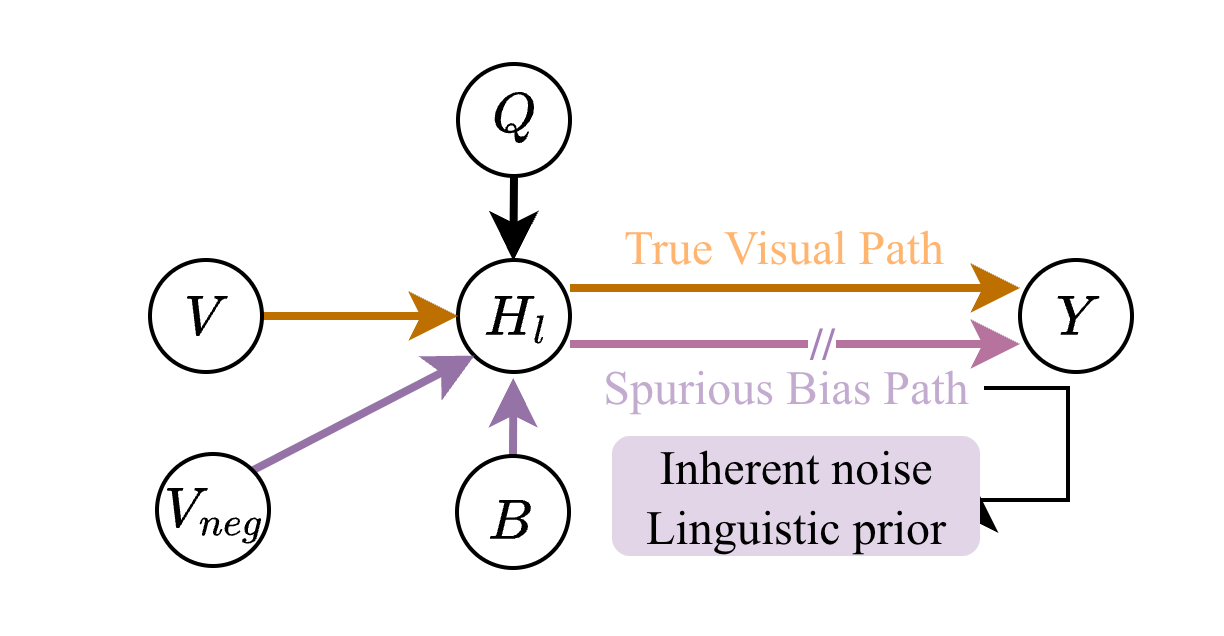
Figure 3: The simplified Structural Causal Model (SCM) for hallucination, illustrating spurious biases affecting latent representation.
Implementation Details
The framework is implemented as a training-free approach, enhancing practical applicability by eliminating the need for additional training data or processes. Experimental results demonstrate the framework's ability to significantly reduce hallucinations with minimal latency overhead, proving efficient across various MLLM architectures and benchmarks.
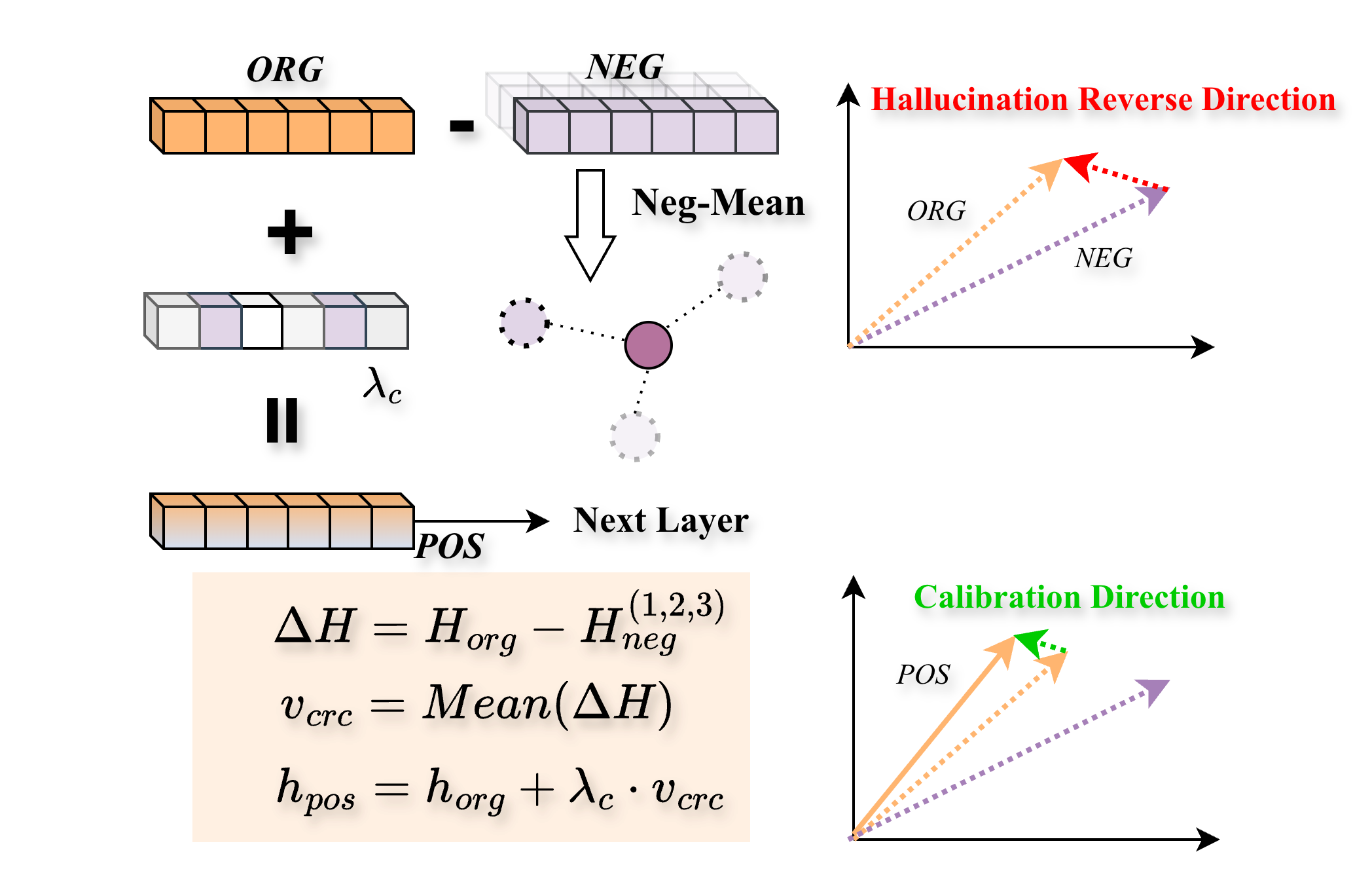
Figure 4: Illustration of the CRC mechanism, subtracting biased latent representations to purify hidden states.
Results and Analysis
Through comprehensive evaluations on benchmarks like POPE and CHAIR, the proposed framework outperforms leading training-free solutions. The approach consistently improves object recognition accuracy and reduces sentence-level hallucinations, attesting to its generalizability across different MLLMs and datasets.
Figure 5: Â MMHal-Bench Evaluation indicating superior performance across several benchmarks and multiple MLLMs.
Conclusion
The paper introduces an effective solution for MLLM hallucinations by redefining vision token manipulation to balance vision-language representations. This unified approach significantly enhances the reliability of multimodal models, achieving state-of-the-art results with efficient computational overhead.
Further Research Directions
While the framework offers robust performance improvements, future research could explore the extension of this technique to other domain-specific applications under varying multimodal conditions. Additionally, investigating deeper causal pathways and interactions between visual representations and language biases could yield further optimizations and insights for improving MLLM outputs in complex scenarios.