- The paper introduces SMRA, a supervised moral rationale attention framework that significantly enhances prediction performance and explanation alignment in hate speech detection.
- It employs transformer models guided by expert-annotated token-level moral rationales, yielding notable improvements in metrics like IoU-F1 and Token-F1.
- The study presents the HateBRMoralXplain benchmark, demonstrating robust, cross-cultural performance and fairness in detecting hate speech with moral context.
Self-Explaining Hate Speech Detection with Moral Rationales
Introduction and Motivation
State-of-the-art hate speech detection (HSD) systems are limited by their reliance on surface lexical cues and the concomitant lack of robustness, cross-cultural contextualization, and interpretability. The work "Self-Explaining Hate Speech Detection with Moral Rationales" (2601.03481) addresses these critical deficiencies by proposing Supervised Moral Rationale Attention (SMRA), a novel attention-supervised framework informed by Moral Foundations Theory (MFT). SMRA explicitly aligns the model’s attention with expert-annotated token-level moral rationales during training, optimizing for both predictive performance and explanation faithfulness.
The emphasis on moral rationales is motivated by mounting evidence that hateful content is structured around a bounded set of recurring moral transgressions rather than merely lexical triggers. The paper also introduces HateBRMoralXplain, a large-scale benchmark in Portuguese, annotated with hate speech labels, moral categories, token-level rationales, and socio-political metadata, enabling robust evaluation of explanation methods in low-resource and highly contextual settings.
Supervised Moral Rationale Attention Framework
The SMRA framework extends transformer-based classifiers by supervising the model’s intrinsic attention weights with human-provided moral rationales. This results in self-explaining predictions that are fundamentally interpretable, context-aware, and robust against spurious correlations.
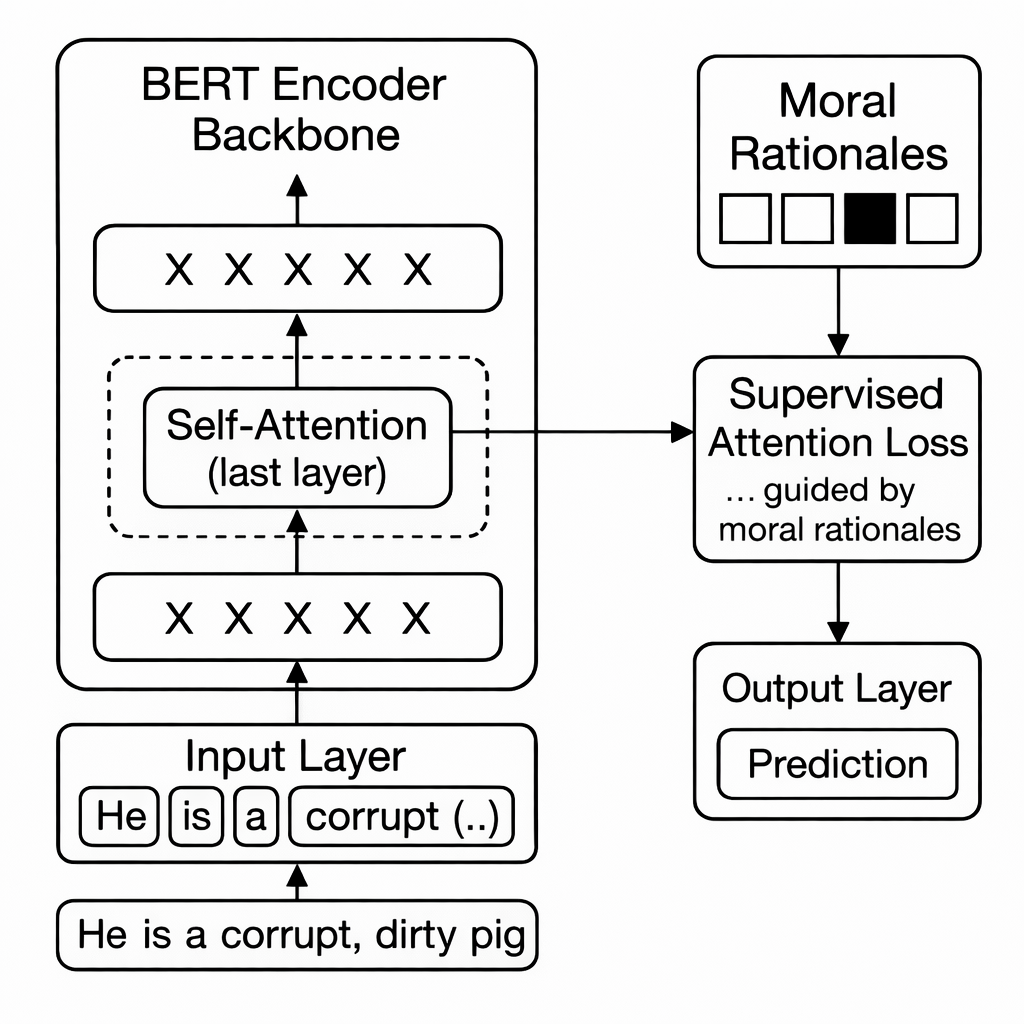
Figure 1: The SMRA training regime guides attention towards human-annotated morally salient tokens, yielding both hate speech predictions and inherently interpretable rationale heatmaps at inference.
Formally, given a sequence x=(w1,...,wL), its class label y, and rationale mask r (aligned to tokens), the model’s attention vector a is regularized to minimize mean squared error (MSE) with r for all relevant samples. The total loss is a convex combination of cross-entropy (for y) and attention alignment for r. This normative regularization is only applied on samples with non-null rationale annotations and non-trivial moral category assignments. The resulting gradient signals force transformer encoders (e.g., BERTimbau, mBERT) to learn attributions and feature dependencies that correspond to expert-identified moral reasoning phenomena.
Dataset: HateBRMoralXplain
HateBRMoralXplain extends previous Brazilian Portuguese hate speech corpora with 7,000 Instagram comments, amply annotated for binary hate, fine-grained moral categories (based on MFT), token-level rationales per category, and detailed metadata including political and demographic attributes. Multiple annotations per comment capture primary, secondary, and tertiary moral lenses, supporting multi-label and multi-hop explanation tasks. Annotator profiles are reported, including moral values, ideology, and socio-demographic information, enabling analysis of subjectivity in hate and moral judgments.
The rationale annotation guidelines enforce distinct evidence spans for each category, supporting precise supervision and avoiding confounds from over-broad explanations. Inter-annotator agreement is consistently substantial (Cohen’s kappa up to 0.81), demonstrating annotation reliability despite the inherent subjectivity of offensive and moral language.
Experimental Design and Metrics
The evaluation encompasses (1) standard fine-tuning of monolingual (BERTimbau) and multilingual (mBERT) transformers, (2) the same architectures with SMRA supervision, and (3) LLM prompting (GPT-4o-mini, Llama3.1-70B) with systematic prompt variations to analyze the utility of definitions, context, and joint reasoning for both hate and moral dimensions.
Metrics include Macro F1 and AUROC for prediction, IoU-F1 and Token-F1 for rationale plausibility, sufficiency and comprehensiveness for faithfulness, and group-based AUCs (GMB-Sub, GMB-BPSN, GMB-BNSP) for fairness. Explanations are evaluated using ERASER-style alignment with human rationales.
Empirical Results
SMRA provides consistent, statistically robust improvement in both interpretability and performance. On binary hate speech detection, SMRA achieves ≈0.9 F1 increase and substantial gains in rationale alignment (e.g., BERTimbau IoU-F1 up from 0.7612 to 0.8355, Token-F1 up by >0.05). Importantly, explanation sufficiency improves (lower is better: 0.0426 vs. 0.0657), indicating that rationales are more compact yet remain strongly causally relevant to model outputs. Fairness metrics exhibit no major regressions, countering concerns that explanation supervision might amplify bias.
On moral sentiment classification—a substantially more nuanced task—SMRA yields improvements in Macro F1 (0.772 vs. 0.757) and a dramatic increase in Token-F1 (0.966 vs. 0.725), establishing that direct supervision with moral rationales yields models that not only predict more accurately but also align attribution with evidence meaningful to human evaluators.
Comparative analysis demonstrates that SMRA outperforms attention supervision with hate rationales (SRA framework), especially in plausibility and context transfer, validating the use of moral scaffolding over purely surface-level lexical signals. Classic deep learning components (BoW, CNNs, RNNs) are systematically outperformed by contextual transformer models benefiting from attention regularization.
LLM prompting experiments reveal that architectural advances alone do not compensate for lack of explicit moral reasoning. While LLMs achieve high F1 on binary hate, their F1 for moral categories remains poor (<0.38 in all cases); incorporating moral rationales into prompts increases both hate and moral detection performance in both Portuguese and translated English data. Contextual metadata is less helpful, and translation introduces performance drops, evidence of non-trivial sociocultural transfer failures.
Ablation studies indicate that explicit MFT guidance is crucial for nuanced moral valence classification; removal causes 34-36% drops in moral F1.
Critical Analysis and Implications
The integration of explicit moral rationale supervision establishes a new paradigm for self-explaining hate speech detection. Unlike prior approaches limited to post-hoc attribution or lexical rationale alignment, SMRA offers causally faithful, contextually robust, cross-cultural explanations that can be audited, interrogated, and adapted for pluralistic contexts.
SMRA’s ability to improve sufficiency and maintain fairness demonstrates that explanation regularization need not compromise group-level performance. The results expose the limitations of both standard transformer fine-tuning and current LLMs in moral reasoning tasks, even when provided with sophisticated prompts. By tying model attention to culturally durable moral categories, SMRA introduces an additional axis of control and interpretability, reflecting the underlying normative structures in hate/discourse data.
Practically, models trained under SMRA supervision are more robust to adversarial attacks based on spurious cues, less likely to inherit dataset racial/ideological bias, and easier to deploy in allocation-sensitive environments (e.g., content moderation, policy auditing). The approach’s scalability is naturally bounded by the cost of rationale annotation, and there remain open challenges in generalization to truly low-resource domains and in capturing diverse minority/marginalized moral frameworks.
Theoretically, these findings connect advances in explainable NLP with computational moral psychology, institutionalizing the insight that value-laden judgments are not reducible to surface text phenomena. Future developments may focus on unsupervised or few-shot induction of moral rationales, cross-lingual transfer, and the extension of SMRA to other domains requiring normative reasoning (e.g., stance detection, misinformation resilience, legal text analysis).
Conclusion
The introduction of SMRA marks a substantial advance in hate speech detection by formalizing the role of moral rationales in self-explaining models. Empirical evaluation on the HateBRMoralXplain benchmark demonstrates robust increases in interpretability, faithfulness, and cross-cultural performance, without measurable trade-offs in fairness. The approach directly engages contemporary debates on subjectivity, annotation plurality, and normative reasoning in automated toxicity detection. Future work should examine annotation scaling, richer moral-cognitive frameworks, and the integration of SMRA in multi-lingual, multi-domain, and LLM-centric pipelines.